“矩形输出”图像拼接
Zhou, H., Zhu, Y., Lv, X., Liu, Q., & Zhang, S. (2023, October). Rectangular-Output Image Stitching. In 2023 IEEE International Conference on Image Processing (ICIP) (pp. 2800-2804). IEEE.
0. 摘要
图像拼接的目的是将两幅视场重叠的图像进行拼接,以扩大视场(FoV)。 然而,现有的拼接方法拼接的图像不规则,需要进行矩形化处理,耗时且容易出现不自然的现象。 本文提出了第一个端到端框架--矩形输出深度图像拼接网络(RDISNet),该框架可以将两幅图像直接拼接成一幅标准的矩形图像,同时学习图像对之间的颜色一致性并保持内容的真实性。 为了进一步保留拼接图像中大对象的结构,我们设计了一个扩张的BN-RCU块来扩展RDISNet的感受野,以提取丰富的空间上下文。 在此基础上,设计了一种新的数据合成流水线,构建了第一个矩形输出的深度图像拼接数据集(RDIS-D),实现了图像拼接与矩形化的连接。 实验结果表明,RDISNet的求解质量明显优于对比已有的求解方法。
1. 引言
图像拼接的目的是通过拼接多个具有重叠区域的图像来扩展原始视场(FoV)[1, 2, 3]。然而,将拼接结果应用于其他图像处理任务是困难的,因为结果中缺失的区域对网络特征的识别和梯度的计算有严重影响。因此,现有方法通常使用矩形化方法[4, 5]进行图像后处理,如图1所示,这是既耗时又劳神的。此外,传统的矩形化方法,如裁剪、合成[6, 7]和变形[4],无法达到保留图像内容和真实性的目的。Nie等人提出的最新深度学习方法[5]可以维持线性和非线性结构,但他们使用深度学习模型强行学习初始网格,这导致了网格之间的像素错位和更大尺度上的直线结构畸变。
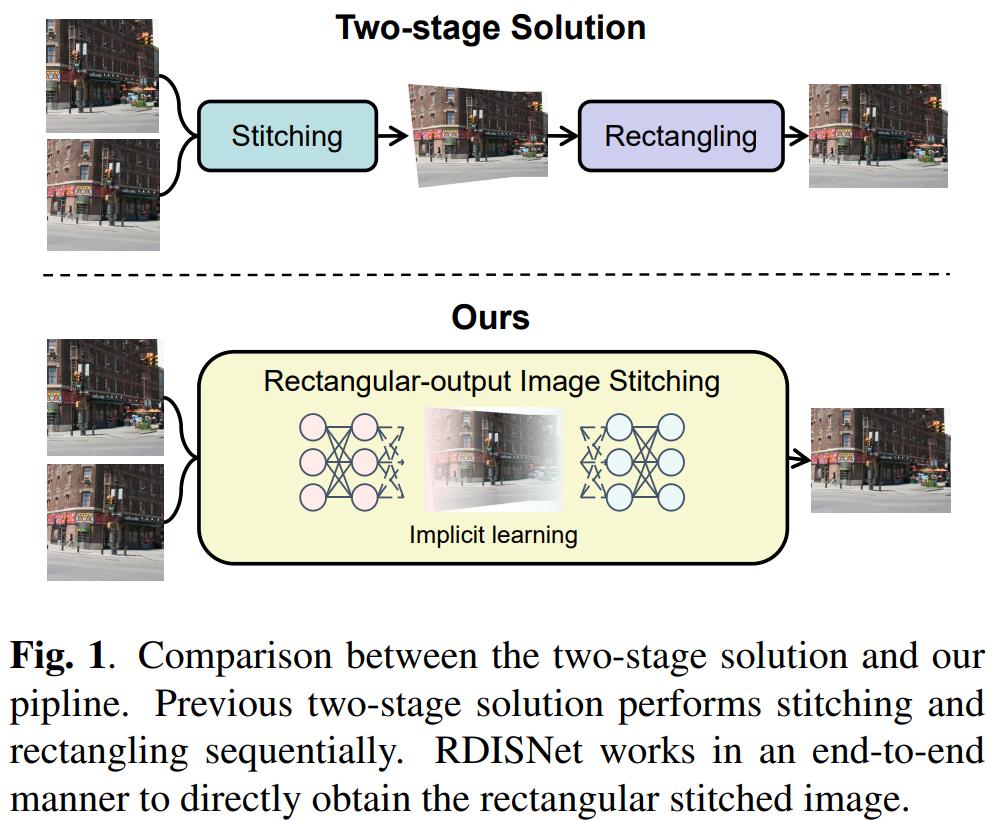
另一方面,缺乏高质量图像拼接数据集限制了现有基于学习方法的性能[8, 9]。Dai等人[10]使用现有的拼接方法创建伪真实标签(pseudo-GT labels),但这样的图像质量受到拼接方法性能的限制。Song等人[11]在GARLA上模拟真实场景,但对真实世界图像的影响有限。Nie等人[12]使用随机几何变换从自然图像中裁剪子图像作为输入和真实标签对,实现了作为自然存在图像的真实标签,但这无法涵盖自然图像的丰富内容信息。图像拼接中的另一个大挑战是在图像对的重叠区域保持颜色一致性。现有方法[13, 14, 15]通常设计特殊算法或模型来实现全局颜色优化,这增加了拼接方法的复杂性。在本文中,我们提出了一个新的任务,称为矩形输出图像拼接,旨在直接将两幅图像拼接成一个标准的矩形图像,同时保持颜色一致性和真实性。为了解决这些问题,我们设计了一个矩形输出深度图像拼接网络(RDISNet),这是第一次尝试以端到端的方式而不是两阶段设计来解决将图像拼接成矩形输出的问题。为了进一步保持拼接图像中大型物体的结构特征,我们设计了一个扩张的BN-RCU模块来扩展RDISNet的感受野。此外,我们设计了一个新的数据合成流程,并构建了第一个矩形输出深度图像拼接数据集(RDIS-D),包含52000个图像对。我们的贡献总结如下:
- 我们提出了一个矩形输出深度图像拼接网络(RDISNet),这是第一次将图像拼接和矩形化统一为一个端到端的过程,同时学习图像对之间的颜色一致性。
- 我们设计了一个扩张的BN-RCU模块来增加RDISNet的感受野,并保持大型物体的结构特征。
- 我们设计了一个新的数据合成流程,并构建了一个矩形输出深度图像拼接数据集(RDISD),包含52000个图像对。
2. 提出的方法
图2展示了所提出的RDISNet的整体结构。RDISNet由三个组件组成:带有扩张BN-RCU模块的双编码器、局部-全局上下文融合模块和卷积解码器。

2.1. 带有扩张BN-RCU模块的双编码器
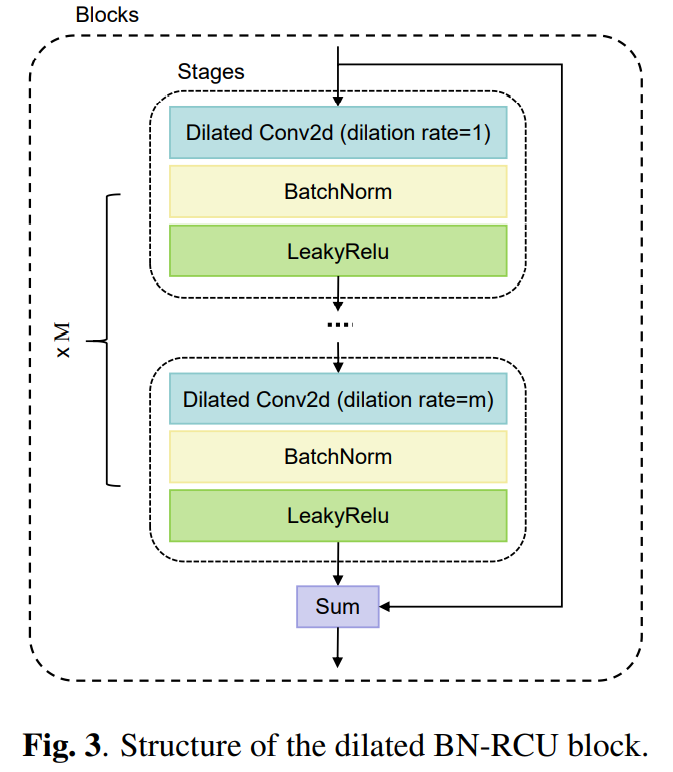
如[16, 17]所示,大的感受野对于提供更丰富的信息以理解图片至关重要。因此,我们设计了一个轻量级的双编码器,有效地提取两幅图像的代表性特征。在每个编码器中,我们设计了一个扩张BN-RCU模块来扩大RDISNet的感受野,以在拼接图像中保留大型物体的结构。扩张BN-RCU模块遵循RefineNet[18]中残差转换单元(RCU)的基本结构,它使用级联的残差块进行特征细化。具体来说,我们用扩张卷积替换了RCU中的卷积。此外,我们在块中的卷积和激活函数之间添加了一个批量归一化层,以帮助深度网络快速收敛。扩张BN-RCU模块的总体结构如图3所示。此外,双编码器分别将两个输入图像下采样到较低的分辨率,以节省网络的计算成本。
2.2. 局部-全局上下文融合模块
在以前的方法中,深度学习网络通常用于计算从初始图像到目标图像的单应性矩阵,这是图像拼接的第一步。因此,拼接过程自然地分为两个阶段:对齐和融合。实际上,transformer可以完全胜任这两个阶段,这是设计端到端学习方案的关键。我们采用了视频修复的思想,专注于相邻帧之间的内容融合,并使用FuseFormer[19]作为RDISNet的主干。使用transformer而不是纯粹的卷积神经网络(CNN)[8, 9, 20]是为了利用多头注意力机制来捕获局部-全局上下文,这对于特征融合至关重要。为了解决融合阶段的伪影和错位问题,我们采用了软分割和软合成操作,以实现特征图的精确次标记级别融合。具体来说,我们使用软分割将双编码器的连接输出分割成512长度的标记,这些标记在结合位置编码后输入到主干网络中。软合成在主干的输出上执行,以实现标记和特征图之间的高效映射,帮助在相邻标记之间传播特征。
2.3. 卷积解码器
为了获得矩形拼接图像结果,我们设计了一个简单的卷积解码器,其中包含多个上采样和卷积层。我们采用卷积跟随插值上采样的策略,以减少结果中的棋盘格伪影。最终,特征图被均匀恢复到384×512的大小。.
3. 改进数据集
为了训练一个端到端的模型,我们构建了一个包含多个待拼接图像及其相应拼接矩形真值的数据库,分为两个步骤进行。
3.1. 拼接图像生成
受到[12]的启发,我们设计了一种拼接标签图像生成方法,可以最大化原始图像信息的利用。图4展示了一个例子。这种方法从任何图像数据集中生成一组待拼接的图像()和标签拼接图像(
)。在制作我们的数据库过程中,我们使用MS-COCO[21]作为基础数据集。

首先,我们定义了算法中使用的参数,一个是重叠区域比例(),即
相对于
的覆盖率,设置为0.2到0.9之间的随机数。另一个是
四个角坐标的扰动量(
),它影响第二个输入图像的角度变换程度。接下来,我们需要计算生成的输入图像的适当大小(
)。为了充分利用MS-COCO中的图像内容,拼接
的结果应该尽可能覆盖原始图像的宽度,这可以表示为:
其中,是原始图像的宽度,
是水平方向上的扰动量。我们计算原始
区域和扰动后的
(
)之间的单应性矩阵
,使用h将原始图像变形以获得最终的
。
在原始图像中所在的区域是拼接图像。在这个阶段,我们获得了一个包含62400张图像的拼接数据集。
3.2. 真值获取
在第二步中,我们将标签拼接图像输入到矩形化方法[5]中以获得矩形拼接图像。然而,由于算法的学习能力有限,需要进行大量的手动筛选。首先筛选出内容模糊和明显失真的图像。其次,过滤掉带有白边的图像,因为白边很容易误导模型认为是不规则的边界。手动筛选一张图片需要大约5-30秒。最终,保留了52000张图像,包括在不同光照条件下室内外场景下的广泛类别。
4. 实验
4.1. 实现细节
在实验中,我们使用RDIS-D和UDIS-D[22]来评估性能。对于RDIS-D,训练集和测试集按照4:1的比例划分。每个输入图像的分辨率是随机的,每个真值图像的分辨率为384×512。我们的模型通过Adam优化器[23]进行训练,学习率设置为。所有实验都在Ubuntu 20.04、PyTorch 1.8.2和单个GeForce RTX 3090上执行。
4.2. 与两阶段方法的比较
为了验证RDISNet的有效性,我们将其与两阶段SOTA方法[22, 5]进行比较。对于UDIS[22]和DIR[5],我们采用作者提供的预训练模型来评估性能。所有方法都在UDIS-D[22]的测试集上进行比较。从表1可以看出,我们的RDISNet在拼接后接矩形化输出的两阶段方法中表现更好。

我们还对RDISNet与两阶段方法进行了定性比较。如图5所示,RDISNet更好地满足了矩形输出的要求,并且对视差失真和结构保持具有良好的鲁棒性。

图5. 拼接和矩形化质量的视觉比较。第1行:输入。第2行:Nie等人的UDIS[22]。第3行:Nie等人的DIR[5]。第4行:RDISNet。
4.3. 消融研究
我们在RDIS-D上进行了消融研究,以验证所提出的带有扩张BN-RCU块的双编码器的有效性。表2显示了所提出的模块带来了合理的性能提升。使用两个编码器可以更好地提取图像特征。扩张卷积在保持特征图大小不变的情况下扩大了网络的感受野,这提高了基线10.4%的PSNR和15.0%的SSIM。此外,在生成数据集时,我们使用了数据增强方法,允许模型自主学习颜色一致性。如图6所示,如果没有使用数据增强方法,结果中会出现不合适的明亮区域。


图6. 使用数据增强保持颜色一致性的实验比较,左侧是输入,右上角的图像是使用数据增强方法的输出,底部是没有使用数据增强方法的输出。
5. 结论
本文提出了一个端到端的矩形输出深度图像拼接网络(RDISNet),它直接将两张图像拼接成一个标准的矩形图像,同时学习颜色一致性并保持内容的真实性。RDISNet的主要贡献在于设计了带有扩张BN-RCU块的双编码器和局部-全局上下文融合模块。前者有助于在特征提取阶段保存大型物体的结构,后者学习次标记级别的特征融合。此外,我们提出了一种新颖的数据合成流程,并构建了第一个矩形输出深度图像拼接数据集(RDIS-D),用于学习和基准测试图像拼接和矩形化的新的联合任务。实验结果证明了我们提出的方法的有效性,并验证了矩形输出图像拼接的可行性。