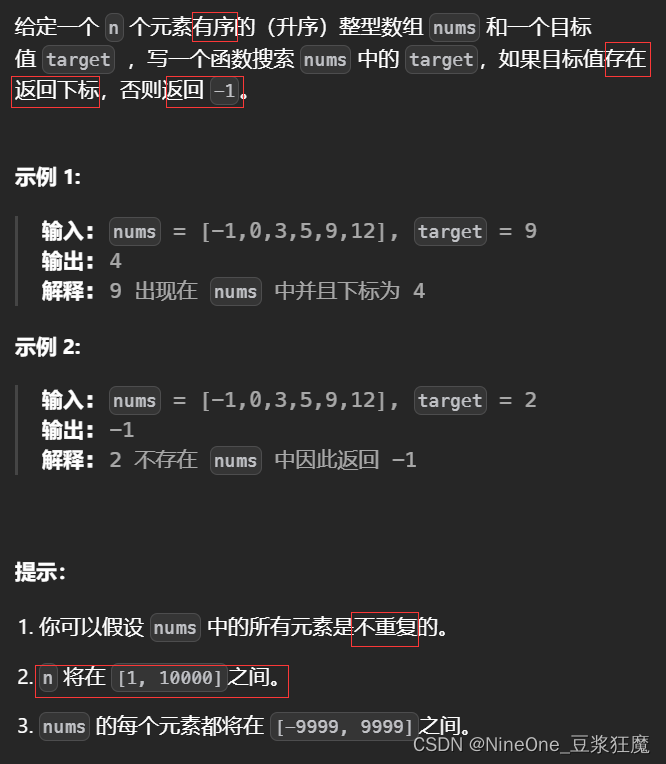
元二分搜索(Steven Skiena 在《算法设计手册》第 134 页中也称为单边二分搜索)是二分搜索的一种修改形式,它以增量方式构建数组中目标值的索引。与普通二分搜索一样,元二分搜索需要 O(log n) 时间。
元二分搜索,也称为单边二分搜索,是二分搜索算法的一种变体,用于搜索有序列表或元素数组。该算法旨在减少在列表中搜索给定元素所需的比较次数。
元二分搜索背后的基本思想是从包含整个数组的大小为 n 的初始区间开始。然后,该算法像二分搜索一样计算中间元素,并将其与目标元素进行比较。如果找到目标元素,则搜索终止。如果中间元素大于目标元素,则算法将新区间设置为前一个区间的左半部分,如果中间元素小于目标元素,则将新区间设置为前一个区间的右半部分间隔。但是,与二分搜索不同,元二分搜索不会对循环的每次迭代执行比较。
相反,该算法使用启发式方法来确定下一个间隔的大小。它计算中间元素的值与目标元素的值之间的差值,并将差值除以预定常数(通常为2)。然后将该结果用作新区间的大小。该算法将继续进行,直到找到目标元素或确定它不在列表中。
元二分搜索相对于二分搜索的优势在于,它在某些情况下可以执行更少的比较,特别是当目标元素接近列表开头时。缺点是在其他情况下,该算法可能比二分查找执行更多的比较,特别是当目标元素接近列表末尾时。因此,当列表的排序方式与目标元素的分布一致时,元二分搜索是最有效的。
这是元二分搜索的伪代码:
function meta_binary_search(A, target):
n = length(A)
interval_size = n
while interval_size > 0:
index = min(n - 1, interval_size / 2)
mid = A[index]
if mid == target:
return index
elif mid < target:
interval_size = (n - index) / 2
else:
interval_size = index / 2
return -1
例子:
Input: [-10, -5, 4, 6, 8, 10, 11], key_to_search = 10
Output: 5
Input: [-2, 10, 100, 250, 32315], key_to_search = -2
Output: 0
确切的实现有所不同,但基本算法有两个部分:
1、计算出存储最大数组索引需要多少位。
2、通过确定索引中的每个位应设置为 1 还是 0,增量构造数组中目标值的索引。
方法:
1、在变量 lg 中存储表示最大数组索引的位数。
2、使用 lg 在 for 循环中开始搜索。
3、如果找到该元素,则返回 pos。
4、否则,在 for 循环中增量构造索引以达到目标值。
5、如果找到元素,则返回 pos,否则返回 -1。
下面是上述方法的实现:
// C++ implementation of above approach
#include <iostream>
#include <cmath>
#include <vector>
using namespace std;
// Function to show the working of Meta binary search
int bsearch(vector<int> A, int key_to_search)
{
int n = (int)A.size();
// Set number of bits to represent largest array index
int lg = log2(n-1)+1;
//while ((1 << lg) < n - 1)
//lg += 1;
int pos = 0;
for (int i = lg ; i >= 0; i--) {
if (A[pos] == key_to_search)
return pos;
// Incrementally construct the
// index of the target value
int new_pos = pos | (1 << i);
// find the element in one
// direction and update position
if ((new_pos < n) && (A[new_pos] <= key_to_search))
pos = new_pos;
}
// if element found return pos otherwise -1
return ((A[pos] == key_to_search) ? pos : -1);
}
// Driver code
int main(void)
{
vector<int> A = { -2, 10, 100, 250, 32315 };
cout << bsearch(A, 10) << endl;
return 0;
}
// This implementation was improved by Tanin
输出:
1
时间复杂度: O(log n),其中 n 是给定数组的大小
辅助空间: O(1) ,因为我们没有使用任何额外空间