真题13
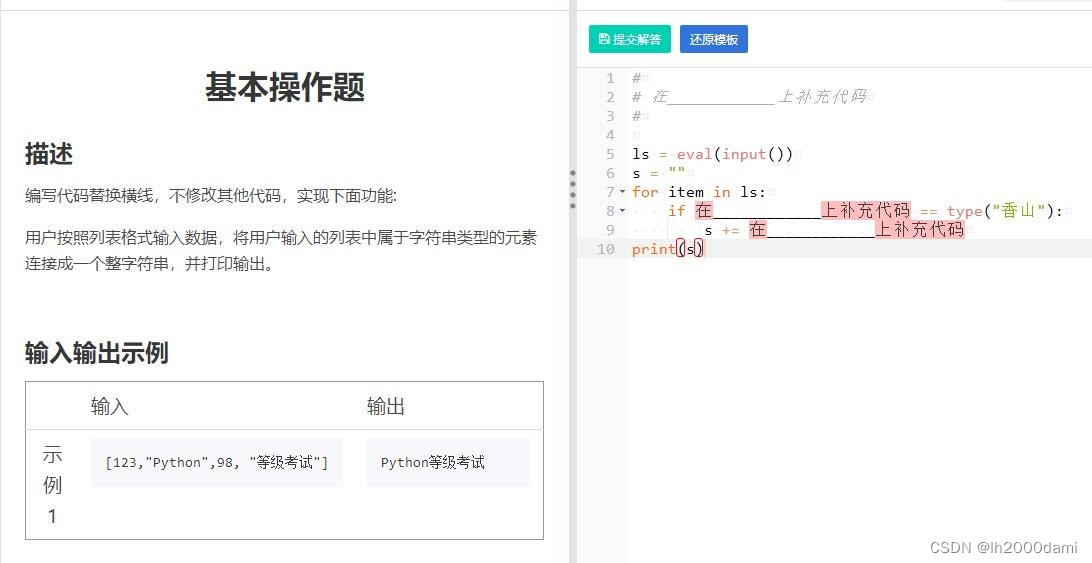
1、编写代码替换横线,不修改其他代码,实现下面功能
用户按照列表格式输入数据,将用户输入的列表中属于字符串类型的元素连接成一个整字符串,并打印输出。
输入
[123,“Python”,98, “等级考试”]
输出
Python 等级考试
代码
ls = eval(input())
s = ""
for item in ls:
if type(item) == type("香山"):
s += item
print(s)
2、请编写代码替换横线,不修改其他代码,实现下面功能
以 25 为种子,随机生成 1 个 1~100 之间的整数,让用户来猜,用户最多只能猜 6 次。接收用户输入的数字,输入的数字和随机数相同时,则打印“恭喜你,猜对了! “,然后程序结束。若输入的数比随机数小,则打印小了,请再试试”,程序继续;若输入的数比随机数大,则打印大了,请再试试”,程序继续;若 6 次还没猜对,在评判大小后,输出“谢谢!请休息后再猜”,然后程序退出。
代码
import random
random.seed(25)
n = random.randint(1,100)
for m in range(1,7):
x = eval(input("请输入猜测数字:"))
if x == n:
print("恭喜你,猜对了!")
break
elif x>n:
print("大了,再试试")
else:
print("小了,再试试")
if m == 6:
print("谢谢!请休息后再猜")
3、请编写代码替换横线,不修改其他代码,实现下面功能,让用户输入一个自然数 n。
如果 n 为奇数,输出表达式 1+1/3+1/5+…+1/n 的值。
如果 n 为偶数,输出表达式 1/2+1/4+1/6+…+1/n 的值。
输出结果保留两位小数。
输入
4
输出
0.75
代码
def f(n):
s = 0
if n%2==1:
for i in range(1, n+1, 2):
s += 1/i
else:
for i in range(2, n+1, 2):
s += 1/i
return s
n = int(input())
print("{:.2f}".format(f(n)))
4、不修改其他代码,实现下面功能
使用 turtle 库绘制三个彩色的圆,圆的颜色按顺序从颜色列表 color 中获取,圆的圆心位于(0,0)坐标处,半径从里至外分别是 10 像素,30 像素,60 像素。

代码
import turtle as t
color = ['red','green','blue']
rs = [10,30,60]
for i in range(3):
t.penup()
t.goto(0, -rs[i])
t.pendown()
t.pencolor(color[i])
t.circle(rs[i])
t.done()
5、用户输入一首诗的文本,包含中文逗号和句号。
用 jieba 库的精确模式对输入文本分词。
1.将分词后的词语输出并以"/ "分隔并统计中文词语数并输出
2.以逗号和句号将输入文本分隔成单句并输出,每句一行, 每行 20 个字符宽,居中对齐。
在 1 和 2 的输出之间,增加一个空行。
示例输入:
床前明月光,疑是地上霜。
输出:
床前/明月光/疑是/地上/霜/
中文词语数是:5
床前明月光
疑是地上霜
代码
import jieba
s = input("请输入一段中文文本,句子之间以逗号或句号分隔:")
slist = jieba.lcut(s)
m = 0
for i in slist:
if i in ",。":
continue
m+=1
print(i,end="/")
print("\n中文词语数是:{}\n".format(m))
word = ''
for j in s:
if j in ",。":
print("{:^20}".format(word))
word = ""
continue
word+=j
6、data.txt 是由学生信息构成的数据文件,每行是一个学生的相关信息, 包括姓名、班级和分数。
姓名和其他信息之间用英文冒号隔开,班级和分数之间用英文逗号隔开,班级由“系名+班级序号"组成,如“计算 191"。
本题作答第一问
读取 data.txt,输出学生的姓名和分数到文件 studs.txt,每行一条记录,姓名和分数用
英文冒号隔开,示例如下:
示例输入:
王一:计算 191,340
张二:经济 191,450
…(略)
输出:
王一:340
李四:450
…(略)
本题作答第二问
选出分数最高的学生,打印输出学生的姓名和分数,中间用英文冒号隔开,示例如下:
李四:450
示例输入:
王一:计算 191,340
张二:经济 191,450
…(略)
输出:
李四:450
本题作答第三问
计算每个班级的平均分,打印输出班级和平均分,平均分小数点后保留 2 位,中间用英文冒
号隔开,示例如下:
示例输入:
王一:计算 191,340
张二:经济 191,450
…(略)
输出:
计算 191:447.55
经济 191:460.08
(略)
第一问代码
f_data = open('data.txt', 'r')
f_studs = open('studs.txt', 'w')
for student in f_data:
ls = student.split(':')
name = ls[0]
score = ls[1].split(",")[1]
f_studs.write("{}:{}".format(name,score))
f_data.close()
f_studs.close()
第二问代码
f_data = open('data.txt', 'r')
L = []
for student in f_data:
ls = student.strip('\n').split(':')
name = ls[0]
score = ls[1].split(",")[1]
L.append((name,eval(score)))
L.sort(key=lambda x:x[1],reverse=True)
L = "{}:{}".format(L[0][0],L[0][1])
print(L)
f_data.close()
第三问代码
f_data = open('data.txt', 'r')
d = {}
for student in f_data:
s = student.strip('\n').split(':')[1]
subject = s.split(',')[0]
score = s.split(',')[1]
d[subject] = d.get(subject,[])+[eval(score)]
for i in d.items():
print("{}:{:.2f}".format(i[0],sum(i[1])/len(i[1])))
f_data.close()
真题14
1、请编写代码替换横线,可修改其他代码,实现下面功能:
获得用户输入的一个整数n,输出一个n-1行的数字三角形阵列。该阵列每行包含的整数序列为从该行序号开始到n-1,例如第1行包含1到n-1的整数,第i行包含从i到n-1的整数;数字之间用英文空格分隔。
示例如下(其中数据仅用于示意):
输入
8
输出
1 2 3 4 5 6 7
2 3 4 5 6 7
3 4 5 6 7
4 5 6 7
5 6 7
6 7
7
代码
n = eval(input("请输入一个整数:"))
for i in range(1,n):
for j in range(1,n):
if j>=i:
print(j,end=' ')
print()
2、请编写代码替换横线,可修改其他代码,实现下面功能:
获得用户输入的5个小写英文字母,将小写字母变成大写字母,并逆序输出,字母之间用逗号分隔。
示例如下(其中数据仅用于示意):
输入:
gbcde
输出:
E,D,C,B,G
代码
s = input("请输入5个小写字母:")
s = s.upper()
print(','.join(s[::-1]))
3、请写代码替换横线,可修改其他代码,实现如下功能:
获得用户输入的一个整数,记为n,以100为随机数种子,随机生成10个1到n之间的随机数,输出生成的随机数,数字之间以逗号分隔。
示例如下(其中数据仅用于示意):
输入
900
输出
150,471,466,790,777,723,403,750,359,444
代码
import random
n = eval(input('请输入一个整数:'))
random.seed(100)
for i in range(1,11):
if i<10:
print(random.randint(1,n),end=',')
else:
print(random.randint(1,n))
4、请编写代码替换横线,不修改其他代码,实现以下功能:
使用turtle库函数绘制4个等距排列的正方形,边长为40像素,间距宽度为40。最左边的正方形左上角坐标为(0,0)。
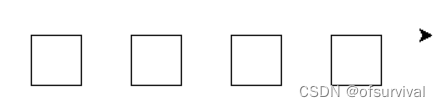
代码
import turtle
n = 4
for j in range(n):
turtle.pendown()
for i in range(4):
turtle.fd(40)
turtle.right(90)
turtle.penup()
turtle.fd(80)
turtle.done()
5、请编写代码替换省略号,不可以修改已有代码,实现以下功能:(1)定义一个列表persons,里面有一些名字字符串;
(2)在该列表中查找用户输入的一个名字字符串;如果找到,则生成一个四位数字的随机数组成的验证码,输出找到的名字字符串和验证码;如果找不到该字符串,则输出提示信息“对不起,您输入的名字不存在。”;如果用户输入一个字母’q’,则退出程序;
(3)显示提示信息后,再次显示“请输入一个名字:”,提示用户输入,重复执行步骤2;执行3次后自动退出程序。
输入输出示例
输入
Alice
输出
Alice 1001
输入
bob
输出
对不起,您输入的名字不存在。
输入
q
输出
程序自动退出
代码
import random as r
r.seed(0)
persons = ['Alice', 'Bob','lala', 'baicai']
flag = 3
while flag>0:
flag -= 1
name = input('请输入一个名字:')
if name == 'q':
print('程序自动退出')
break
elif name in persons:
num = r.randint(1000,9999)
print('{} {}'.format(name, num))
else:
print('对不起,您输入的名字不存在。')
6、该题目分为2个问题,附件有素材文件webpage.txt。
webpage.txt保存了某网站一个网页的HTML格式源代码。在该文件中,JPG图片以一个完整的URL表示,示例如下:

其中,与是一对组合,表示包含一个URL链接;<img …(略) …/>表示包含一个JPG图像文件的URL,每个URL用src=开头,以JPG图像文件名结束,如538.JPG表示JPG图像文件。
在考生文件夹编程实现如下功能
本题作答第一问
(1)统计并打印输出该页面中JPG图像文件的URL数量。注意,JPG扩展名都是大写字母,输出示例如下(其中数据仅用于示意):
输出:
15
本题做题第二问
(2)将webpage.txt页面中的JPG图像文件的URL提取出来,保存在文件images.txt中,每个URL一行。
输出格式示例如下:(其中数据仅用于示意)
http://image.ngchina.com.cn/2018/0829/20180829012548753.JPG
http://image.ngchina.com.cn/2018/0823/thumb_469_352_20180823121155508.JPG
…(略)
第一问代码
fi = open('webpage.txt')
datas = fi.readlines()
num = 0
for data in datas:
if '.JPG' in data:
num += 1
print(num)
fi.close()
第二问代码
fi = open('webpage.txt')
datas = fi.readlines()
fo = open('images.txt','w')
for data in datas:
if '.JPG' in data:
data = data.split('src="')[1].split('"')[0]
fo.write(data+'\n')
fi.close()
fo.close()
真题15
1、在考生文件夹下存在一个Python源文件PY101.py,请编写代码替换横线,不修改其他代码,实现下面功能:
让用户输入一个符号作为填充字符,将PYTHON字符串以30字符宽、居中、其余部分以填充字符的形式格式化输出。
示例如下:
输入:
输出:
############PYTHON############
代码
a = input("请输入填充符号:")
s = "PYTHON"
print("{0:{1}^30}".format(s, a))
2、在考生文件夹下存在一个Python源文件PY102.py,请编写代码替换横线,不修改其他代码,实现下面功能:
获取一个由英文逗号、字母、汉字、数字字符组成的输入,计算该输入中所有数字的和,并输出。
示例如下:
输入:
1,海淀区,ab,56,3,中关村
输出:
数字和是:60
代码
myinput = input("请输入:")
ls = myinput.split(',')
s = 0
for c in ls:
if c.strip(" ").isdigit():
s += eval(c)
print("数字和是:" + str(s))
3、在考生文件夹下存在一个Python源文件PY103.py,请完善代码,实现以下功能:
data1.txt文件保存了一组汉字,输出该文件不同字符的数量。
示例如下:
输出:
100
代码
f = open('data1.txt')
ls = []
for line in f:
for c in line:
if c not in ls:
ls.append(c)
f.close()
print(len(ls))
4、在考生文件夹下存在一个Python源文件PY201.py。请编写代码替换横线,不修改其他代码,实现下面功能:
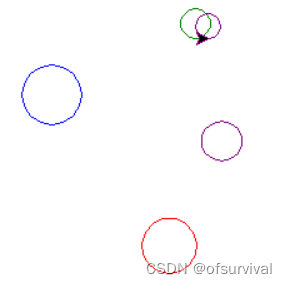
(1)使用turtle库和random库,在屏幕上绘制5个彩色的圆;
(2)圆的颜色随机从颜色列表color中获取;
(3)圆的起始坐标x和y值从范围[-100,100]之间选取,半径从范围[10,30]之间选取。
效果如下图所示。
代码
import turtle as t
import random as r
color = ['red','green','blue','purple','black']
r.seed(1)
for j in range(5):
t.pencolor(color[r.randint(0,4)])
t.penup()
t.goto(r.randint(-100,100),r.randint(-100,100))
t.pendown()
t.circle(r.randint(10,30))
t.done()
5、在考生文件夹下存在一个python源文件PY202.py。请编写代码替换省略号,可修改其他代码,实现下面功能:
(1)获取用户输入的一段文本,包含但不限于中文字符、中文标点符号及其他字符﹔
(2)用jieba的精确模式分词,统计分词后中文词语词频,具体为:将字符长度大于等于2的词语及其词频写入文件data2.txt,每行一个词语,词语和词频之间用冒号分隔。
示例如下:
输入:
借助平台优势,宣传推广相应产品,并为技术从业者提供更多学习、交流、探讨的机会,从而促进技术交流、企业互通、人才培养,促进技术的发展。
输出:
借助:1
平台:1
优势:1
宣传:1
推广:1
相应:1
产品:1
技术:3
从业者:1
…(略)
代码
import jieba
f = open('data2.txt','w')
s = input("请输入一个中文字符串,包含逗号和句号:")
k=jieba.lcut(s)
d1 = {}
for i in k:
if len(i) >= 2:
d1[i] = d1.get(i,0) + 1
for j in d1:
f.write(j+':'+str(d1[j])+'\n')
f.close()
6、在考生文件夹下存在2个Python源文件PY301-1.py、PY301-2.py和素材文件data3.txt。data3.txt文件内容示例如下:
商业模式价值链由三个环节组成:产品、工具、社区。我们团队以一站式系统开发为当前主要产品,利用XAMPP,PHPSTORM,微信开发者工具等软件根据客户要求提供合适的一体化管理系统。
…(略)
打开PY301-1.py,编程实现如下功能:
(1)统计文件中出现词频最多的前10个长度不小于2个字符的词语,将词语及其出现的词频数按照词频数递减排序后显示在屏幕上,每行显示一个词语,用英文冒号连接词语及其词频。示例如下:
我们:5
系统:3
微信:3
…(略)
打开PY301-2.py,编程实现如下功能:
(2)将文档以中文逗号及中文句号为分隔符分割成短句,将包含最高词频的词语的句子,输出到文件out.txt中,每句一行,示例如下:
以此为我们吸引更多的商机
同时普及我们的一站式开发技术
…(略)
第一问代码
import jieba
f = open('data3.txt')
datas = f.read()
data = jieba.lcut(datas)
d = {}
for i in data:
if len(i) >= 2:
d[i] = d.get(i,0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for j in ls[:10]:
print('{}:{}'.format(j[0],j[1]))
f.close()
第二问代码
import jieba
f = open('data3.txt')
fo = open('out.txt','w')
datas = f.read()
data1 = jieba.lcut(datas)
data2 = datas.replace(',','。')
data2 = data2.split('。')
d = {}
for i in data1:
if len(i) >= 2:
d[i] = d.get(i,0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for j in data2:
if ls[0][0] in j:
fo.write(j.strip('\n')+'\n')
f.close()
fo.close()
真题16
1、在考生文件夹下存在一个Python源文件PY101.py,请编写代码替换横线,不修改其他代码,实现下面功能:
获得用户输入的浮点数,以10字符宽度、靠右输出这个浮点数,小数点后保留2位数。
示例如下(其中数据仅用于示意):
请输入一个浮点数:2.4
浮点数是: 2.40
请输入一个浮点数:5.98320
浮点数是: 5.98
代码
f = eval(input("请输入一个浮点数:"))
print("浮点数是:{: >10.2f}".format(f))
2、在考生文件夹下存在一个Python源文件PY102.py,请编写代码替换横线,不修改其他代码,实现下面功能:
按照小写字母a到z顺序组成包含26个学母的字符表,其中,第一个字符a序号为0,依次递增。程序获得用户输入的起始字母序号及连续输出字母的个数,分别记为变量h和w,以逗号隔开,并根据字符表输出从起始字母序号h开始的连续w个字母。
示例如下(其中数据仅用于示意):
输入:
0,3
输出:
abc
代码
h,w = eval(input("请输入起始英文字母的序号和连续输出的个数,逗号隔开:"))
cstr = ''
for i in range(w):
c = chr(ord('a')+h+i)
cstr += c
print(cstr)
3、在考生文件夹下存在一个Python源文件PY103.py,请完善代码,实现以下功能:
获得用户输入的三个整数,以逗号分隔,分别记为: n、m、k,其中m>k。以1为随机数种子,产生n个在k和m之间的随机整数(包括k和m),将这些随机数输出,每个数一行。
示例如下(其中数据仅用于示意):
输入:
4,26,10
输出:
14
12
18
13
代码
import random as r
r.seed(1)
s=input("请输入三个整数 n,m,k:")
slist=s.split(",")
n,m,k = eval(slist[0]),eval(slist[1]),eval(slist[2])
for i in range(n):
print(r.randint(k,m))
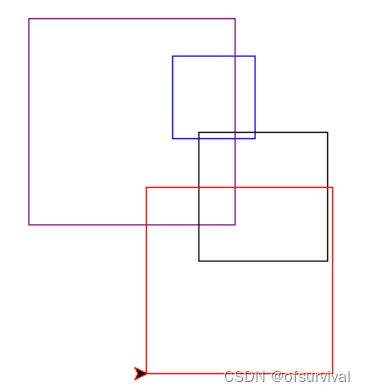
4、在考生文件夹下存在一个Python源文件PY201.py,请写代码替换横线,不修改其他代码,实现下面功能:
使用turtle库和random库,绘制四个彩色的正方形,正方形颜色随机从颜色列表color中获取;正方形边长从范围[50,200]之间选取,每个正方形左下角坐标x和y从范围[-100,100]之间选取。
示例如下:
代码
import turtle as t
import random as r
color = ['red','blue','purple','black']
r.seed(1)
for j in range(4):
t.pencolor(color[r.randint(0,3)])
t.penup()
t.goto(r.randint(-100,100), r.randint(-100,100))
t.pendown()
ra = r.randint(50, 200)
for i in range(1,5):
t.fd(ra)
t.seth(90*i)
t.done()
5、在考生文件夹下存在一个Python源文件PY202.py,请写代码替换横线,可修改其他代码,实现下面功能:
文件PY202.py里定义了一个字符串dela=‘-;:,.()"<>’,包含了需要去除的字符。获取用户输入的文本,去除字符串dela中的字符,用jieba精准分词后,统计并输出其中词语的个数。
示例如下:
输入:
请参考“论语-原文-输出示例.txt"文件
输出:
里面有8个词语。
此外,模板程序还将输出其他一些调试信息,请保留并按照提示给出相应输出,作为调试辅助。
代码
import jieba
dela = '-;:,.()"<>'
s = input("请输入一句话:")
print("\n这句话是:{}".format(s))
for i in dela:
s=s.replace(i,'')
word=jieba.lcut(s)
print("替换之后是:{}".format(s))
print("里面有 {}个词语。".format(len(word)))
6、在考生文件夹下存在2个Python源文件PY301-1.py、PY301-2.py和素材文件data301.txt。data301.txt文件是2020年5月2日的一个HTML页面源文件,里面包含了若干个地区的新冠确诊人数统计数据、地区及人数。
格式如下所示(其中数据仅用于示意):
(略)
{
“name”: “Montserrat”,
“value”: 0
},
{
“name”. “Saint Helena”,
“alue”:0
},
{
“name”. “Falkland Islands”,
“value”:0
},
(略)
打开Py301-1.py,编程实现下面功能:
问题1(10分):从data301.txt中提取地区名称及新冠确诊人数,输出地区的总数。
示例如下(其中数据仅用于示意):
一共有1000个地区
将地区名称和人数结果写入文件result301.tzxt,每行一个地区的信息。
示例如下:
(略)
Germany:183979
Thailand:3112
United Kingdom:284868
France:153634
(略)
打开Py301-2.py,编程实现下面功能
问题2(10分):读取问题1输出的文件result301.txt,对确诊人数进行排序,输出确诊人数最多的地区名称和人数。
示例如下(其中数据仅用于示意) :
新冠确诊人数最多的地区是United States,人数是1900000
新冠确诊人数超过1w的地区有20个
新冠确诊人数为0的地区有40个。
第一问代码
fi = open("data301.txt","r")
f = open("result301.txt","w")
cnumd = {}
name = ''
count = 0
flag = 1
for line in fi:
if '"name":' in line:
name = line.split('"')[-2]
flag = 1
elif '"value":' in line and flag == 1:
dx = line.split(': ')[-1][:-1]
cnumd[name] = dx
flag = 0
count+=1
for d in cnumd.items():
f.write("{}:{}\n".format(d[0],d[1]))
print("一共有{}个地区".format(count))
f.close()
fi.close()
第二问代码
lcnum = []
with open("result301.txt", "r") as fi:
for line in fi:
s = line.strip().split(':')
if len(s)<=1:
continue
lcnum.append([s[0],eval(s[1])])
lcnum.sort(key=lambda x:x[1], reverse= True)
lz = 0
lw = 0
for l in lcnum:
if l[1] > 10000:
lw += 1
elif l[1] == 0:
lz += 1
print("新冠确诊人数最多的地区是{},人数是{}".format(lcnum[0][0],lcnum[0][1] ))
print("新冠确诊人数超过1W的地区有{}个".format(lw))
print("新冠确诊人数为0的地区有{}个".format(lz))
真题来源:小黑课堂计算机二级python题库