FCN网络内容简介
FCN网络是第一个将深度学习应用于语义分割的网络,具有开创新和划时代的意义

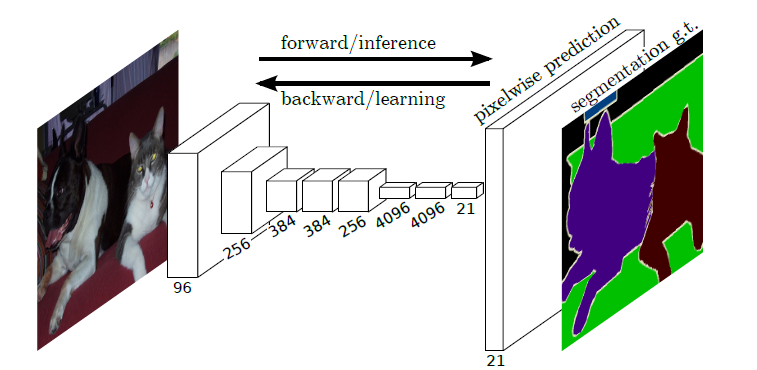
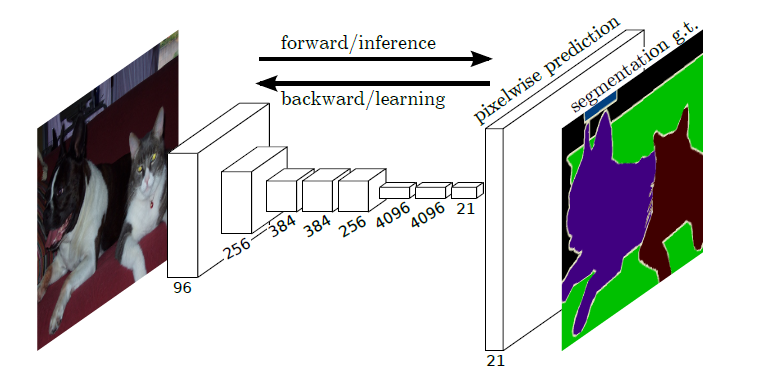
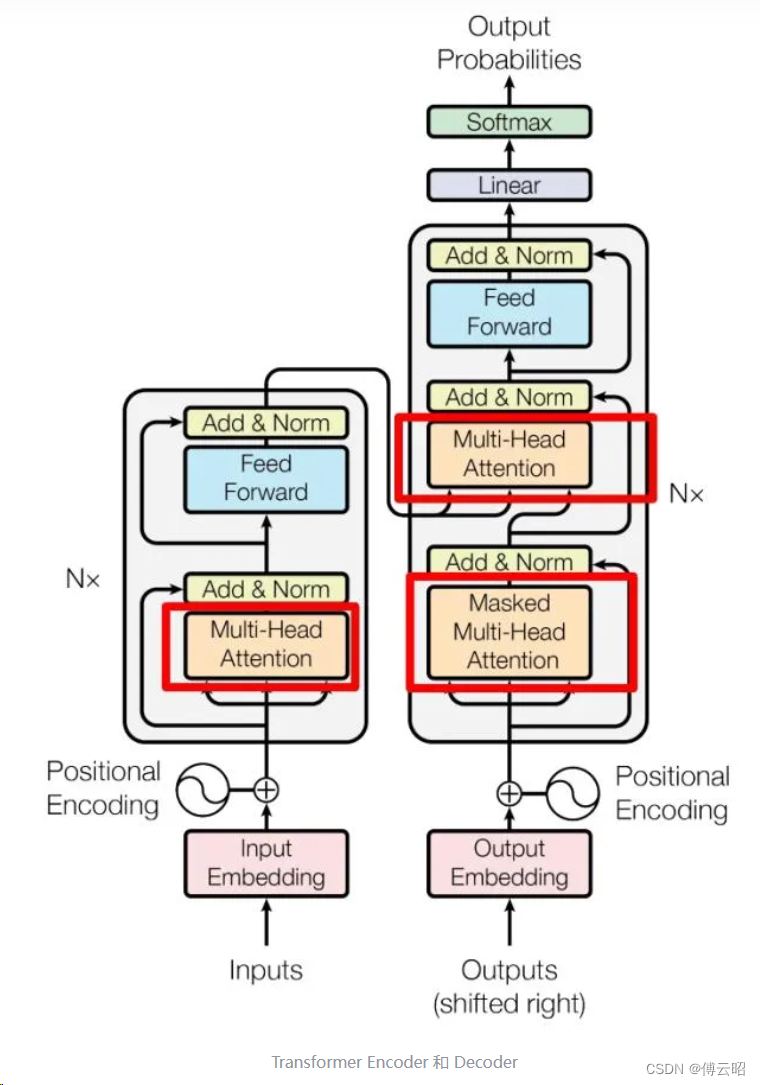
FCN网络在2015年效果是非常惊艳的,准确率提高了10%左右,并且推理时间非常快 。下面是网络结构示意图和实验数据。

最后进行放大的预测图有21个通道(20个类+背景),每个通道的值代表对于一个类的预测概率,取概率预测最大的类别作为该像素的预测类别
FCN网络卷积化过程详解
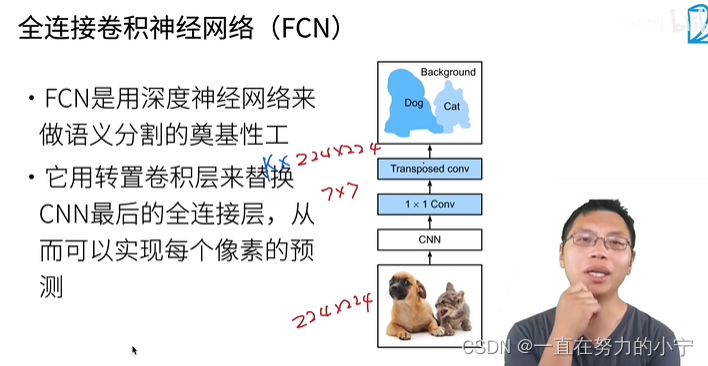
首先FCN中有一个很重要的创新点Convolutionalization结构
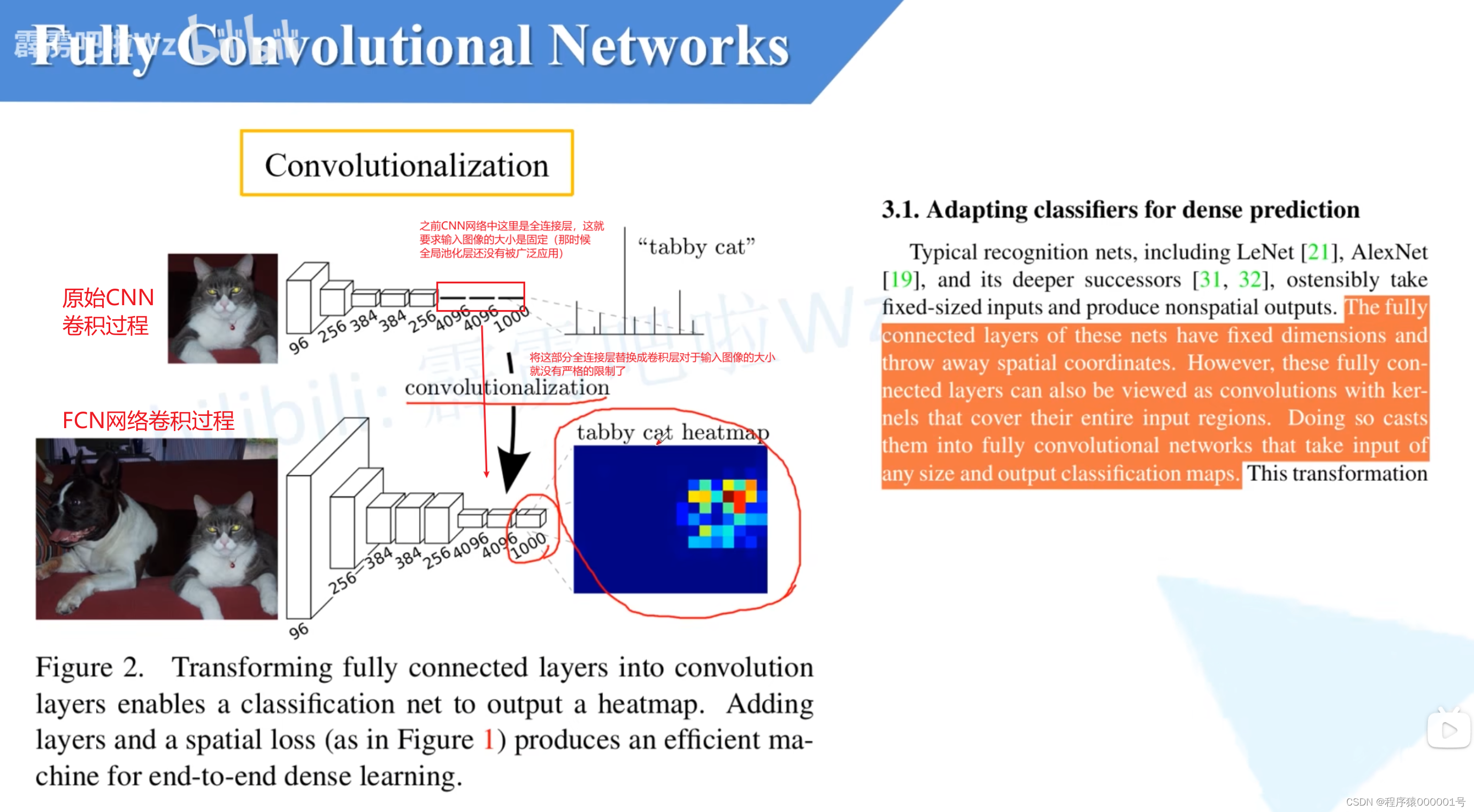
对于上图有以下几点:
为什么要将全连接层替换成卷积层:
1. 保留空间信息:全连接层将输入数据展平为向量,丢失了输入数据的空间信息。对于图像分割等任务,空间信息对于准确的像素级预测非常重要。通过使用卷积层替代全连接层,可以保留输入数据的空间结构,使得网络能够对每个像素进行预测。
2. 处理任意大小输入:全连接层要求固定大小的输入,而卷积层可以处理任意大小的输入。对于图像分割任务,输入图像的大小可能不同,使用全连接层需要将输入图像调整为固定大小,这可能导致图像的形状信息丢失。而卷积层可以处理不同大小的输入,使得网络可以适应不同尺寸的图像。
那么为什么目标检测任务可以将图片调整到相同尺寸然后输入进入模型,但是语义分割任务不能够这么干,反而需要通过调整网络结构,使得模型能够接受不同尺寸大小的输入?
在目标识别任务中,我们通常将输入的图片固定到相同的尺寸是因为目标识别任务的目标是对整个图像进行分类,而不需要对每个像素进行预测。因此,将输入图像调整为相同的尺寸可以方便地将其输入到全连接层或其他分类器中进行分类。
然而,在语义分割任务中,我们的目标是对每个像素进行分类,即为每个像素分配一个语义标签。每个像素都有其重要性,因此保留图像的空间信息对于准确的像素级预测非常重要。不同的图像可能具有不同的尺寸,例如自然图像数据集中的图像可以具有各种大小和长宽比。如果将输入的图像固定到相同的尺寸,可能会导致图像的形状信息丢失或扭曲,从而影响语义分割的准确性。
将全连接层转换为卷积层之后,对于网络输入大小就没有太严格的限制了
convolutionalization过程

简而言之就是通过7*7的卷积核进行卷积替换Flatten操作
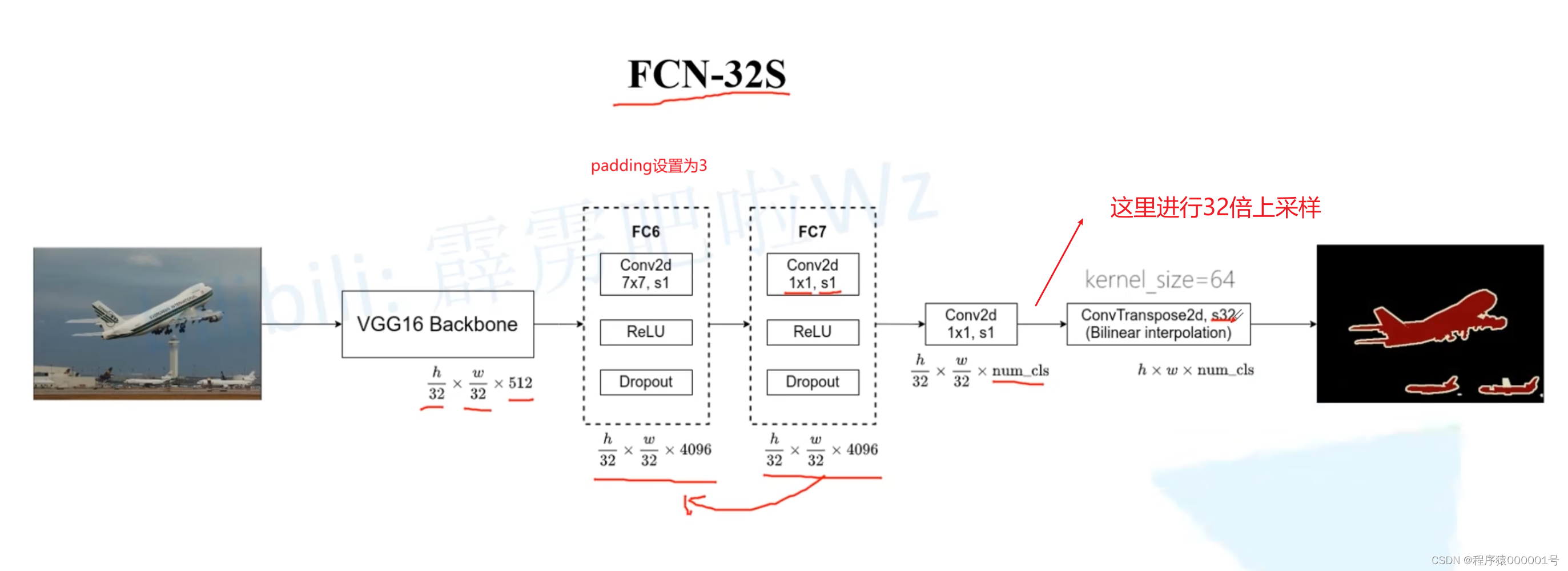
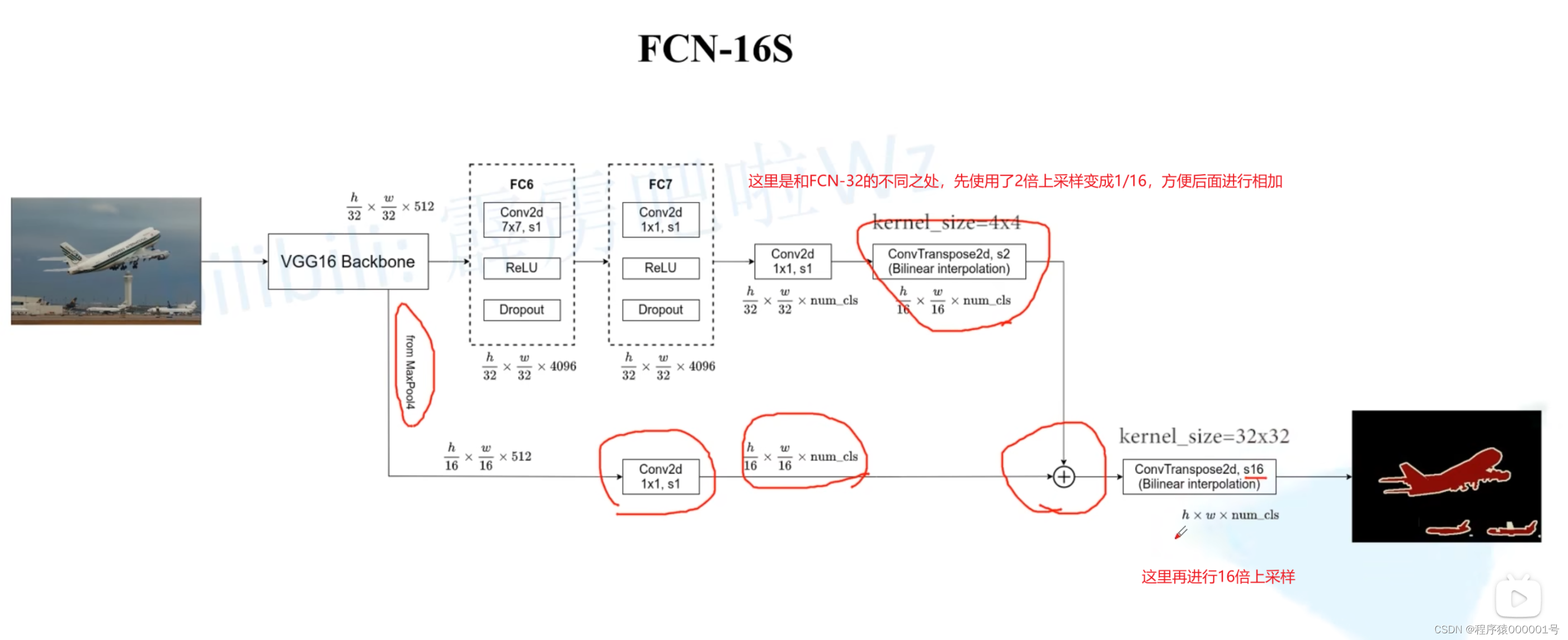
FCN三个版本的模型结构
首先FCN网络的主干网络使用了-VGG结构

FCN有三个版本结构:


到这类,FCN的基础知识就介绍完毕了,觉得对您有帮助,麻烦给我点个关注,感谢感谢