hive的小文件处理思路
小文件产生的原因
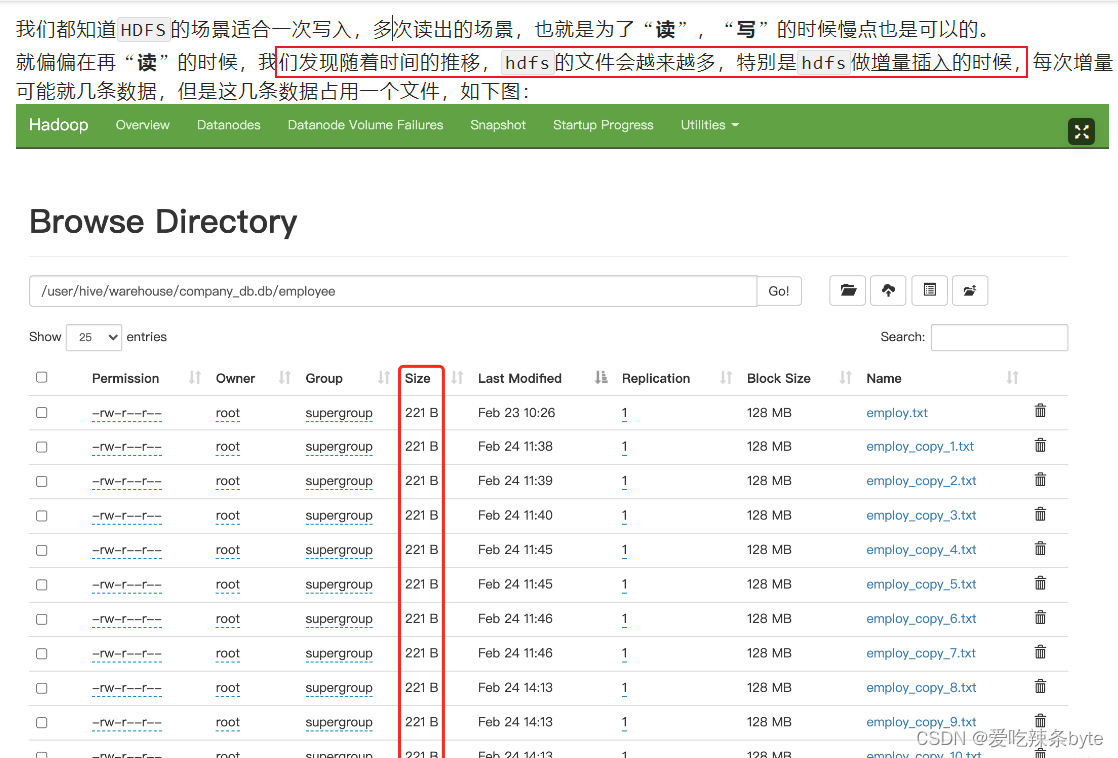
小文件肯定是向hive表中导入数据时产生的,所以先关注导入数据的几种方式
1.直接向表中插入数据
insert into table student values (1,‘xxx’,11),(2,‘xxxxx’,22);
每次插入都会产生一个小文件,这种方式基本没有用的
2.通过load的方式加载数据
load data local inpath ‘/export/score.csv’ overwrite into table A –
导入文件load data local inpath ‘/export/score’ overwrite into table A –
导入文件夹
这种方式导入一个文件就会产生一个文件,导入一个文件夹,就会产生文件夹里文件数量的文件
3.通过查询的方式加载数据
insert overwrite table A select s_id,c_name,s_score from B;
这种方式是比较常用的,
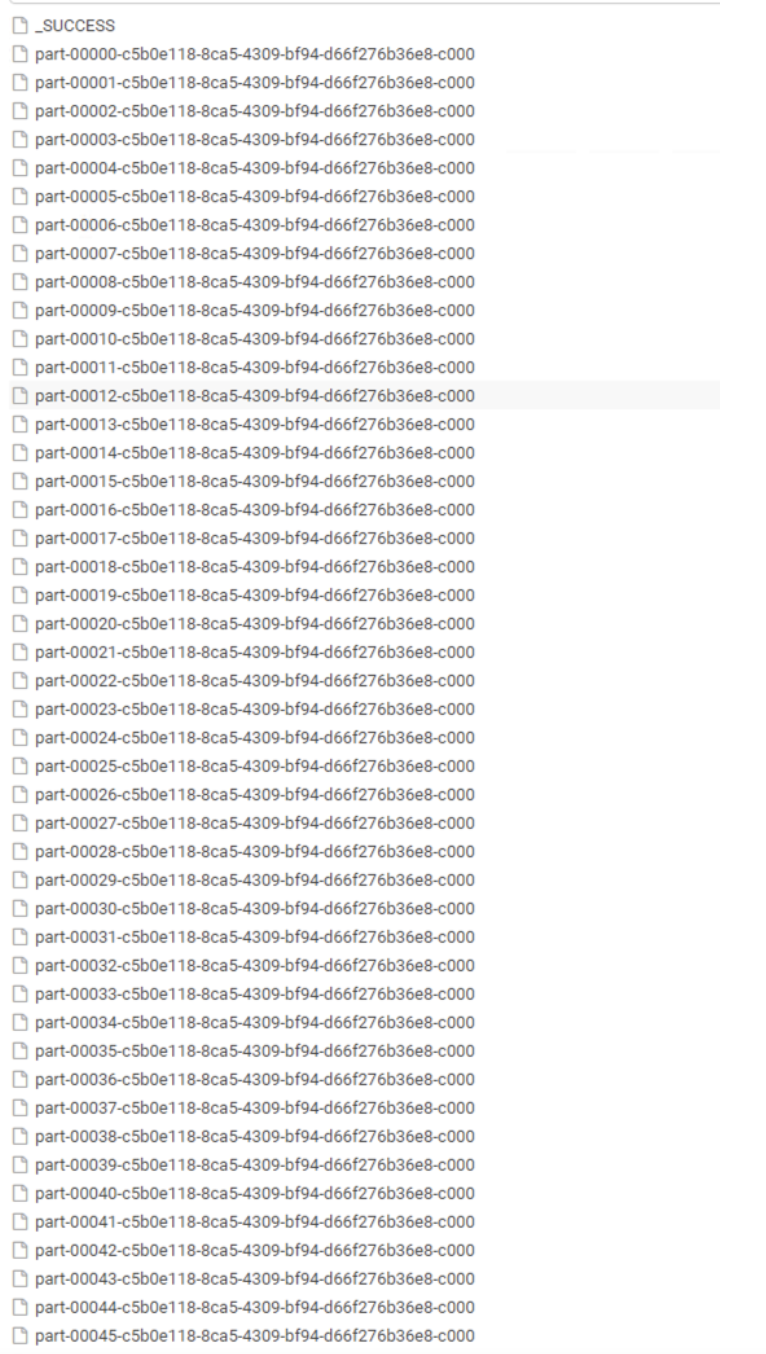
除了导入,还就是MR的任务也会产生小文件
insert 导入数据时会产生MR任务,有多少个reduce就有多少个文件,ReduceTask * 分区数
但简单的任务只有Map阶段,这时就 MapTask * 分区数
1.使用 hive 自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table A concatenate;
#对于分区表
alter table B partition(day=20201224) concatenate;
注意:
1、concatenate 命令只支持 RCFILE 和 ORC 文件类型。
2、使用concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
3、当多次使用concatenate后文件数量不在变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
2.调整参数减少Map数量
设置map输入合并小文件的相关参数
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认
#每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000; -- 100M
设置map输出和reduce输出进行合并的相关参数
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M
启用压缩
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
3.减少Reduce的数量
#reduce 的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#hive中的分区函数 distribute by 正好是控制MR中partition分区的,
#然后通过设置reduce的数量,结合分区函数让数据均衡的进入每个reduce即可。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;
#第二种是设置每个reduce的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=5120000000; -- 默认是1G,设置为5G
#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
解释:如设置reduce数量为10,则使用 rand(), 随机生成一个数 x % 10 ,
这样数据就会随机进入 reduce 中,防止出现有的文件过大或过小
4.使用hadoop的archive将小文件归档
#用来控制归档是否可用
set hive.archive.enabled=true;
#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
#控制需要归档文件的大小
set har.partfile.size=1099511627776;
#使用以下命令进行归档
ALTER TABLE A ARCHIVE PARTITION(dt='2020-12-24', hr='12');
#对已归档的分区恢复为原文件
ALTER TABLE A UNARCHIVE PARTITION(dt='2020-12-24', hr='12');
注意:
归档的分区可以查看不能 insert overwrite,必须先 unarchive
如果是新集群,没有历史遗留问题的话,建议hive使用 orc 文件格式,以及启用 lzo 压缩。
这样小文件过多可以使用hive自带命令 concatenate 快速合并.