Communicative Agents for Software Development(大模型驱动的全流程自动化软件开发框架)
| 会议 | arxiv 2023 |
|---|---|
| 作者 | Chen Qian Xin Cong Wei Liu Cheng Yang |
| 团队 | Tsinghua University |
| 论文地址 | https://arxiv.org/pdf/2307.07924.pdf |
| 代码地址 | https://github.com/OpenBMB/ChatDev/blob/main/ |
| 简介 | 一种基于聊天的软件开发框架ChatDev |
作者希望提出的自然语言到软件框架的潜力可以照亮将llm集成到软件开发中的新可能性,并标志着自然语言处理、软件工程和集体智能领域新前沿的曙光。
Introduction

软件工程需要一种有系统的、有纪律的方法来开发、操作和维护软件系统。近年来,深度学习技术的发展促使研究人员探索其在软件工程中的应用,旨在提高有效性、效率和降低成本。
在一步生成一个软件系统时,缺乏任务特异性会让llm感到困惑。软件开发中的细粒度任务,例如分析用户/客户需求和选择编程语言,提供了llm所处理的高级任务所缺乏的指导思想。其次,在决策过程中缺乏质证,造成重大风险。
ChatDev遵循经典的瀑布模型,将设计流程分为:设计、编码、测试和文档编写,每个阶段会有多个不同角色的代理。ChatDev利用一个chat chain,将每个阶段分为原子子任务,在聊天链中,每个节点代表一个特定的子任务,两个角色参与上下文感知、多回合讨论,以提出和验证解决方案。
Contributions
- 提出了一种基于聊天的软件开发框架ChatDev,仅通过指定一项任务,就会依次处理设计、编码、测试和文档编写。通过语言交流来统一过程,简化了软件开发,消除了每个阶段对特定模型的需求。
- 提出了聊天链来将开发分解成顺序的原子子任务,每个子任务需要两个角色之间的协作交互和相互检查。
- 为了缓解代码幻觉等问题,引入了一种叫“思想指导机制”,通过执行角色转换,指导者将特定代码修改思想注入到指令中,以实现更精确的指导。
- 实验结果证实了ChatDev带来的效率以及成本收益。
ChatDev
Main Problem
每个阶段需要多个角色之间进行有效的交流沟通,在确定交互顺序以及参与的相关个体等提出了较大的挑战。
Chat Chain
软件开发过程的四个不同的阶段:设计、编码、测试和文档化。在设计阶段,通过协作头脑风暴产生创新想法,并定义技术设计需求。编码阶段包括源代码的开发和检查,而测试阶段将所有组件集成到一个系统中,并利用解释器的反馈信息进行调试。文档化阶段包括环境规范和用户手册的生成。
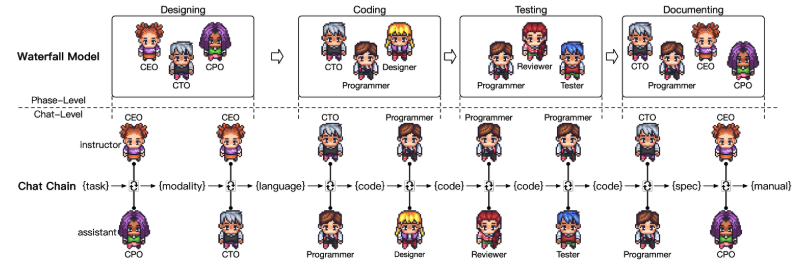
整个体系分为阶段级和聊天级,阶段级即软件开发过程的四个不同的阶段,聊天级在每个阶段会分为多个原子聊天对话,由当前阶段所需人员参与讨论。
Designing
Role Assignment
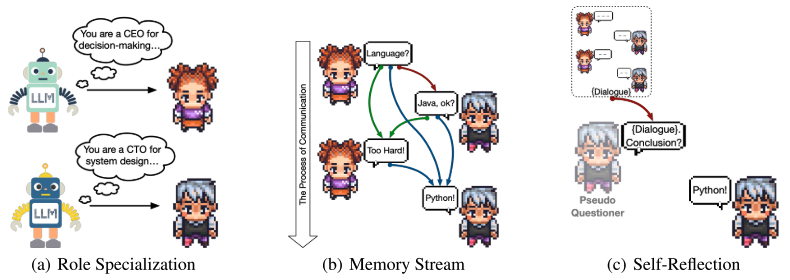
System prompts用于角色扮演过程中给每个代理分配角色,并且这些提示在对话开始前将角色分配给代理。Instructor最初扮演CEO的角色,参与互动,Assistant扮演CPO的角色,执行任务并提供回答。为了实现角色的专门化,还给代理提供了inception prompting,使代理能够履行其角色的设定。Instructor和Assistant包含有关指定任务和角色、通信协议、终止标准和防止不良行为(指令冗余、无信息响应、无限循环等)的约束。
Memory Stream
- 通过memory stream是一种机制,维护之前的对话记录。
- 通过提示来建立通信协议,如当双方达成一致时,会生成满足特定格式要求的结束信息()。
Self Reflection
总的来说就是,当观察到对话双方达成一致的时候,没有触发预定义的结束的通信协议(),这时需要进行reflection,让一个新的提问者发起一个新的聊天,将对话双方的聊天记录给Assistant,要求其从对话中获取信息摘要。
Coding
编码阶段有三个预定义的角色:CTO、programmer和art designer。聊天链将编码阶段分解为顺序的原子聊天任务,例如生成完整的代码(CTO和程序员)和设计图形用户界面(设计师和程序员)。
编程环节包括两个基本步骤:后端写代码,和前端设计交互界面。编程环节最大的难点就是如何避免模型幻觉,最大正度保证代码的正确性,以及在多轮对话中如何进行复杂长代码的编写和修改。
代码编写步骤的核心指令如下,CTO智能体给程序员智能体的指令是:以面向对象的编程语言python为基础,先给出核心类和方法。程序员智能体会按照指令以markdown为语法进行代码和注释的编写。之后代码编写环节会循环执行N次多轮对话,不断对代码进行更新优化。
Code Management
为了处理复杂的软件系统,ChatDev使用面向对象的编程语言。ChatDev引入了“版本演化”机制来限制角色之间对最新代码版本的可见性,而从内存流中丢弃较早的代码版本,版本逐步进化消除了代码幻觉。
Thought Instruction
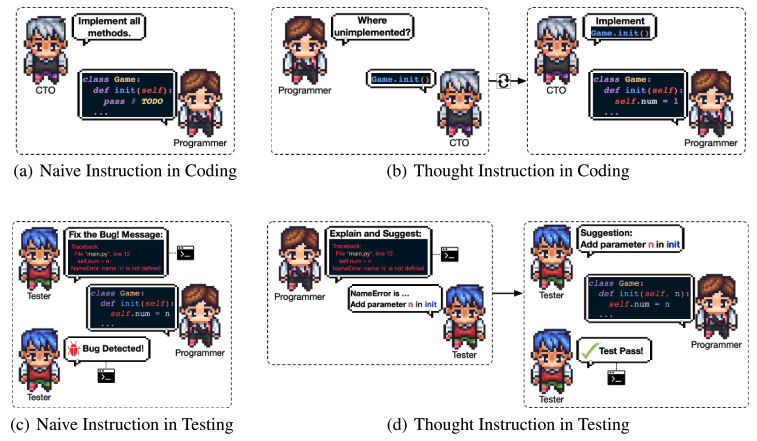
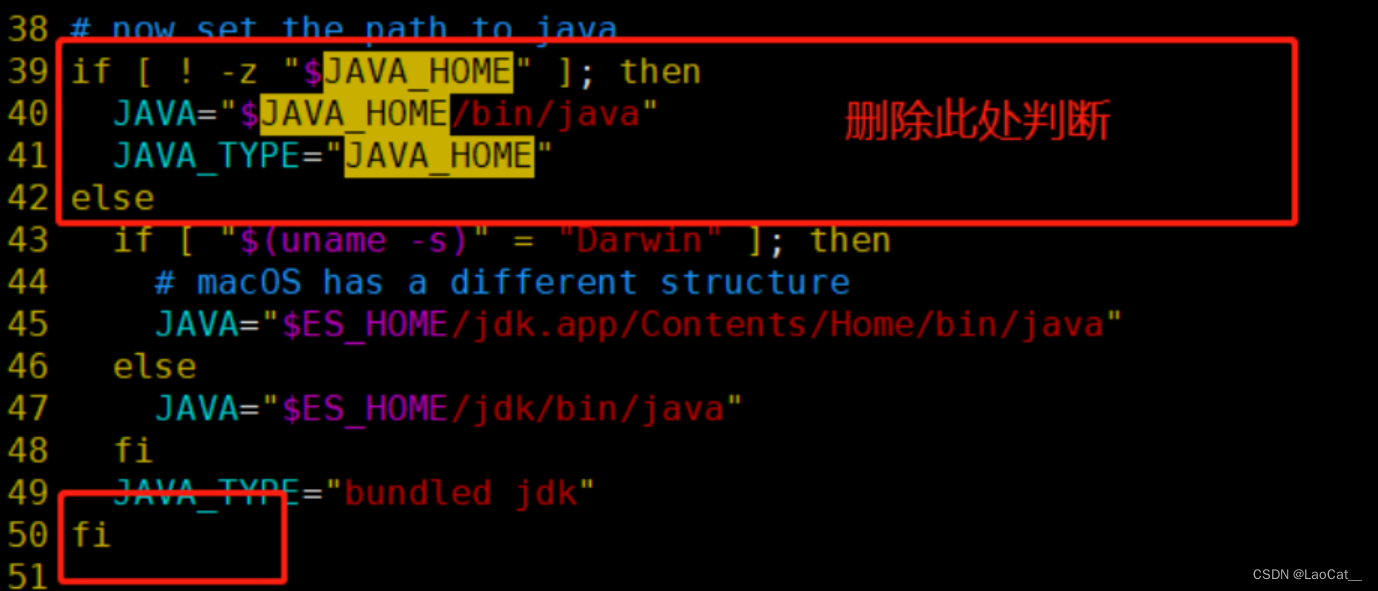
传统的回答问题可能导致不准确或不相关的信息,特别是在代码生成中,天真的指令可能导致意想不到的幻觉。在生成代码时,这个问题变得尤为严重。为了解决这个问题,提出了一种“思维指导”的机制,灵感来源于“思维链提示”。这种机制包括在指令中明确地解决特定的问题解决思想。(如交换角色,询问哪些没有实现,然后切换回来让其更精确的执行)
Testing
测试阶段分为三个角色:Programmer、Reviewer和Tester。该过程由顺序的原子聊天任务组成,包括同行评审(程序员和评审员)和系统测试(程序员和测试员)。
在实践中,观察到允许两个代理仅根据来自解释器的反馈消息进行通信并不能得到一个无bug的系统。程序员的修改可能不会严格遵循反馈,从而导致幻觉。为了解决这个问题,还是采用了Thought Instruction机制,不过这种是迭代进行,直到其认为潜在的错误已经被消除了,系统能够成功运行。(本质上是黑盒测试)
Documenting

文档编写阶段分为三个角色:CEO、CPO、CTO和Programmer。
CTO指示Programmer为环境依赖项提供配置说明,从而产生一个类似requirements.txt的文档。本文档支持用户独立配置环境。同时,CEO向CPO传达需求和系统设计,CPO生成用户手册。
Experiments
Setup
- 使用“gpt3.5-turbo-16k”,temperature设置为0.2
- 在编码阶段,最多允许5次代码完成尝试,评审者被允许5次聊天提出修改。
- 对于基于Python的系统,使用Python 3.8.16作为测试的解释器
Dataset
Camel组织了一个指令跟随对话数据集,它跨越了20种编程语言、50个领域和每个领域50个任务。从这个广泛的任务集中,随机选择了70个任务,包括具体的和相对抽象的案例。
Main Results
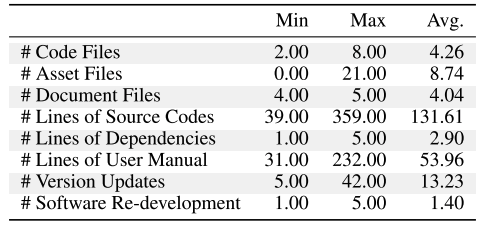
- #Code Files:代码文件夹数量
- #Asset Files:外部文件数量
- #Document Files:生成文档数量
- #Lines of Source Codes:生成源代码行数
- #Lines of Dependencies:环境依赖数(外部软件组件)
- #Lines of User Manual:软件用户手册行数
- #Version Updates:版本迭代次数
- #Software Re-development:开发周期
Duration Analysis
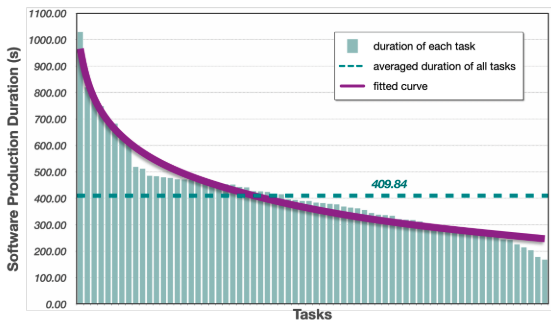
平均耗时为409.84秒,最长耗时为1030秒。
Dialogue Statistics

ChatDev开发一个软件需要36,902.23个提示token,11,567.37个完成token,以及总共48,469.60个token。软件生产的平均总成本大约是0.15693美元,平均每款软件的设计师成本为0.1398美元,而每款软件平均包含8.74个图形创作。因此,CHATDEV的平均软件开发成本为0.2967美元。
Reviewer-Programmer Dialogue Analysis
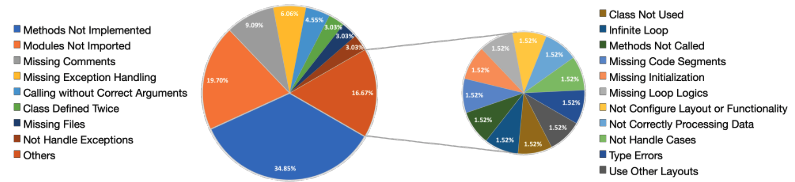
在代码审查期间,Reviewer和Programmer交流中最经常讨论的问题是“未实现的方法”(34.85%)。这种挑战通常出现在复杂模型的代码生成中,核心功能通常会接收占位符标签(如Python中的“pass”)以进一步完成。此外,对话框经常讨论“未导入的模块”的主题(19.70%)。这个问题源于代码生成的本质,生成的代码往往会忽略次要的细节。然而,在代码生成的上下文中,确保代码的可执行性变得至关重要。幸运的是,本文提出的thought instruction机制通过迫使Reviewer识别不完整的方法并要求Programmer填充它们,有效地解决了这些问题。这种机制可以应用于其他场景,在这些场景中,任务是基于大型模型完成的,但缺少某些部分。有趣的是,Reviewer还强调了代码健壮性的重要性。他们强调了将来处理潜在异常时的注意事项,并提供了避免重复类别的提示(3.03%)。此外,Reviewer还提供了关于代码中未使用类的建议(1.52%),识别无限循环(1.52%),并强调适当的环境初始化的必要性(1.52%)。
Tester-Programmer Dialogue Analysis
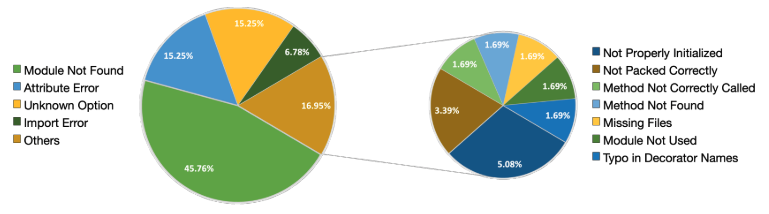
Tester和Programmer之间最常见的调试问题是“模块未找到”(45.76%),占了将近一半的情况。这反映了该模型忽略非常细微细节的倾向,尽管它们很简单。幸运的是,通过本文提出的thought instruction机制,通常可以通过导入所需的类或方法轻松解决此类错误。第二常见的错误类型是“属性错误”和“未知选项”,各占15.25%。“attribute error”是类属性使用错误,“unknown option”是方法调用参数错误。另一种常见的错误类型是“import error”,它类似于“未找到模块”,主要是由import语句中的错误引起的,比如导入了错误的类或使用了错误的导入路径。除了这些常见的错误类型外,ChatDev还能够检测相对罕见的错误类型,比如初始化不正确的GUI(5.08%)、错误的方法调用(1.69%)、缺少文件依赖关系(1.69%)、未使用的模块(1.69%)、装饰器语法错误(1.69%)等等。
Case Study
Gomoku
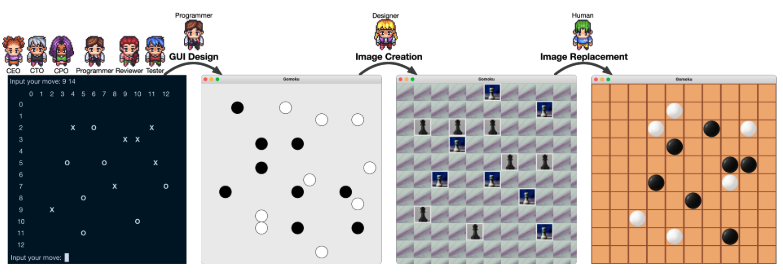
如果人类用户不满意art designer创建的图像,他们可以灵活地在ChatDev完成软件后手动替换原始图像。

The example of making programming language choices in designing.
Conclusion
Problems
- 即使将大模型的temperature设置为很低的值,仍然存在内部的随机性,所以这项技术比较适合开放和创造性的软件生产场景。
- 有些生成的软件无法满足用户需求,可能是因为不清楚用户的需求和文本或代码固有的随机性。
- 直接生成的图像可能不总是在逐渐增强GUI的美观性,过多的复杂性还可能影响用户体验。
- 大型语言模型可能会显示出固有的偏见,导致生成的代码模式不一定与真正的程序员解决问题的思路一致。此外,生成的软件目前缺乏对敏感文件操作的恶意意图识别。
- 这项研究可能会对初级程序员来说有帮助,但对于复杂或大规模的软件,存在非常大的挑战性。
ChatDev利用LLMs来促进软件开发过程中涉及的多个角色之间的有效通信和协作。通过使用聊天链将开发过程分解为顺序的原子子任务,其支持细粒度焦点,并促进每个子任务的期望输出。此外,Thought Instruction机制通过在代码完成、检查和测试期间指导程序员进行特定的代码修改,减轻了与代码幻觉相关的挑战。
Practice
Quick Start
- clone code
git clone https://github.com/OpenBMB/ChatDev.git
项目结构:
├── CompanyConfig # Configuration Files for ChatDev, including ChatChain, Phase and Role config json.
├── WareHouse # Folder for generated software
├── camel # Camel RolePlay component
├── chatdev # ChatDev core code
├── misc # assets of example and demo
├── online_log # Demo Folder
├── run.py # Entry of ChatDev
├── requirements.txt
├── README.md
└── wiki.md
- set up environment
conda create --name chatdev_env python=3.9 -y -i https://pypi.tuna.tsinghua.edu.cn/simple
conda activate ChatDev_conda_env
cd ChatDev
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- set openAI API Key
# macos or linux
export OPENAI_API_KEY="your_OpenAI_API_key"
# windows
$env:OPENAI_API_KEY="your_OpenAI_API_key"
- build software
# macos or linux
python3 run.py --task "[description_of_your_idea]" --name "[project_name]"
# windows
python run.py --task "[description_of_your_idea]" --name "[project_name]"
all params
usage: run.py [-h] [--config CONFIG] [--org ORG] [--task TASK] [--name NAME] [--model MODEL]
argparse
optional arguments:
-h, --help show this help message and exit
--config CONFIG Name of config, which is used to load configuration under CompanyConfig/; Please see CompanyConfig Section below
--org ORG Name of organization, your software will be generated in WareHouse/name_org_timestamp
--task TASK Prompt of your idea
--name NAME Name of software, your software will be generated in WareHouse/name_org_timestamp
--model MODEL GPT Model, choose from {'GPT_3_5_TURBO','GPT_4','GPT_4_32K'}
- run software
# macos or linux
cd WareHouse/project_name_DefaultOrganization_timestamp
python3 main.py
# windows
python run.py --task "[description_of_your_idea]" --name "[project_name]"
所有生成的软件都在WareHouse/NAME_ORG_timestamp下:
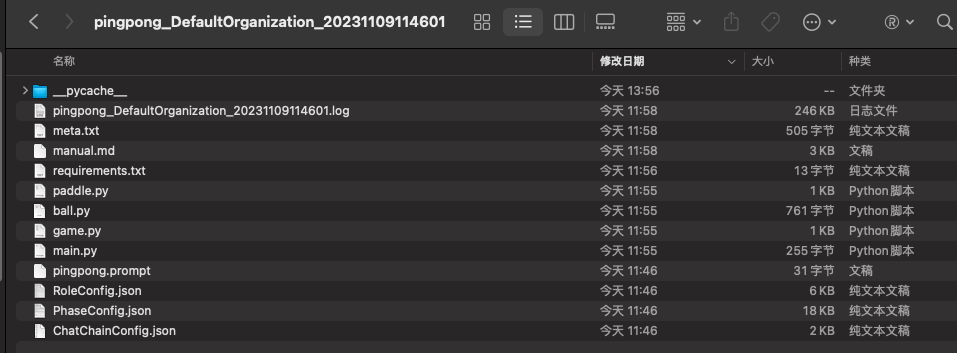
目录结构:
├── 20230822165503.log # log file
├── ChatChainConfig.json # Configuration
├── PhaseConfig.json # Configuration
├── RoleConfig.json # Configuration
├── todo.prompt # User query prompt
├── meta.txt # Software building meta information
├── main.py # Generated Software Files
├── manual.md # Generated Software Files
├── todo_app.py # Generated Software Files
├── task.py # Generated Software Files
└── requirements.txt # Generated Software Files
Multi-Agent
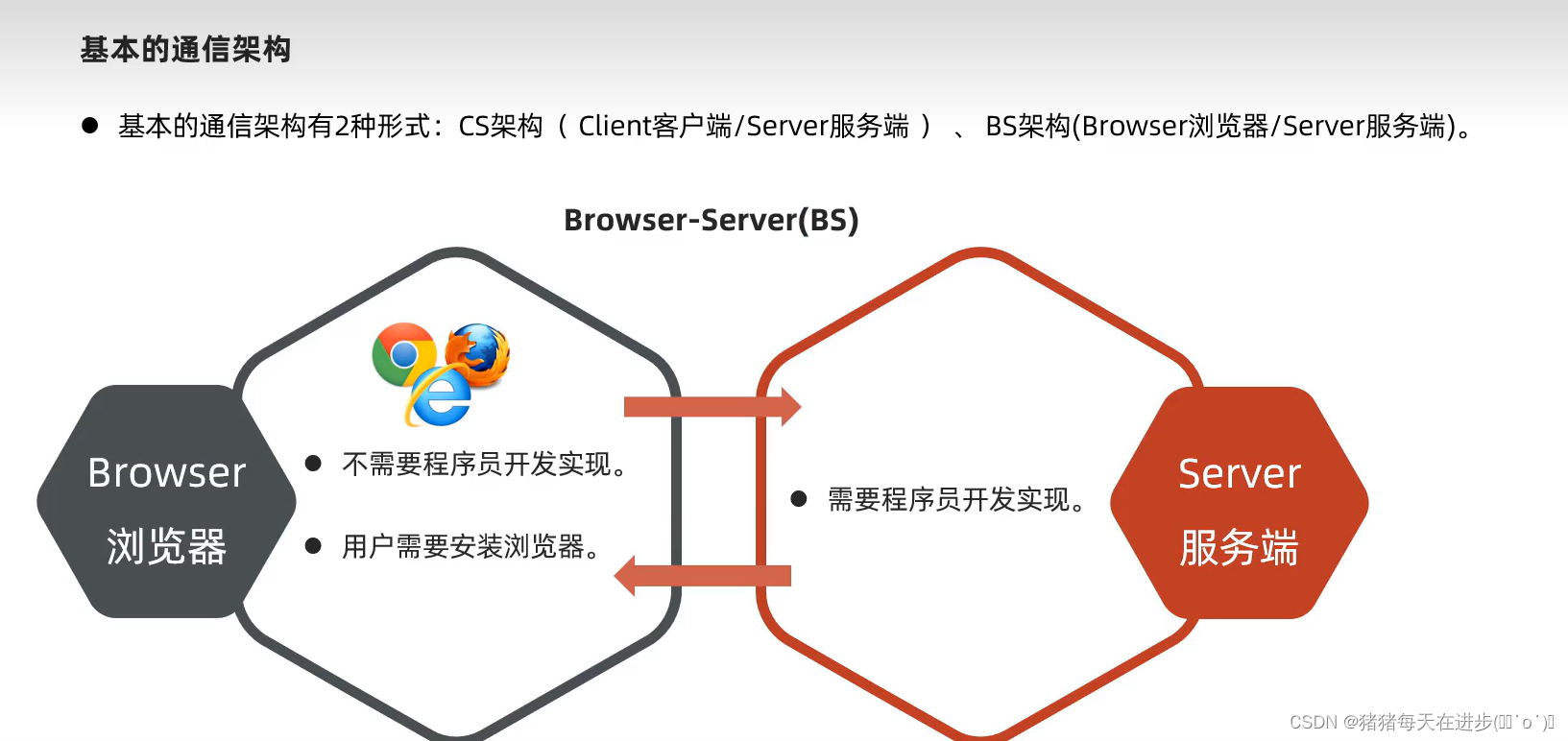
目前LLM应用上主要分为三个方面:
- 直接回复用户的问题(主要使用的是模型的“内部知识”)
- 通过外部知识库或搜索引擎结果来结合上下文去进行回复(主要使用的是模型分析总结的能力)
- 让模型作为一个智能体,结合Prompt以及外部工具或多个智能体交互来完成特定任务
第三种Agent现如今非常火,是目前LLM应用上的一个重要方向。其本质是通过结合大量预定义的Prompt(角色扮演、职责之类的)以及指导式的Prompt(流程控制,协作之类的)来完成多个智能体的交互,以及结合外部工具来完成各种复杂的任务。
大部分Agent项目的共同点:
- CoT Prompt:思维链Prompt,对任务进行拆分。
- Self-Reflection:自反思机制,比如ChatDev的自反思机制,在智能体对话双方达成一致的时候,正常情况下会触发“通信协议”,然后进行终止对话,而其自反思机制会介入第三方,让第三方智能体去提出进行总结的问题,将这个问题还有两个智能体的对话历史记录交给Assistant这个智能体去回答总结之后的决策。(这一做法能够有效的让Assistant反思整个对话流程所产生的结论)
- Memory Stream:记忆可以看成“长期记忆”以及“短期记忆”,可以把Prompt里的内容看成“短期记忆”,“长期记忆”就是那些外部存储的对话记录。(由于LLM输入信息有长度限制,当聊天进行比较久的时候,模型容易遗忘之前对话的内容,所以需要将对话内容进行外部存储。获取长期记忆的方法最常见的有“语义搜索”,通过embedding模型,对所有的对话信息进行向量化,之后进行交互的时候同样将其进行向量化,然后通过相似度匹配来获取最相似的“记忆”文本)
- Divide and Conquer:将大任务拆分成多个原子子任务,就像ChatDev将任务流程化,每个流程又有多个原子任务;这种做法可以让模型更好的完成任务。
Agent在其他方向的应用:
- Behaviour simulation(行为模型)
Generative agents: Interactive simulacra of human behavior(利用沙盒环境创建多个生成代理来模拟可信的人类行为)
Recagent: A novel simulation paradigm for recommender systems(使用多个代理来模拟推荐场景下用户的行为)
- Data construction(数据构建)
Multi-party chat: Conversational agents in group settings with humans and models(通过分配不同角色的agent来收集和评估多方对话)
CAMEL: communicative agents for “mind” exploration of large scale language model
society(提出了一个角色扮演框架,利用代理为复杂任务生成多样化和详细的指令)
- Performance improvement(性能提升)
In-context impersonation reveals large language models’ strengths and biases(发现让agent承担不同的角色可以提高其性能)
Improving factuality and reasoning in language models through multiagent debate(通过利用多agent体辩论提高了事实正确性和推理准确性)
Encouraging divergent thinking in large language models through multi-agent debate(利用多agent相互辩论来解决自我反省中的思维退化问题)
更多的Agent Paper:https://github.com/zjunlp/LLMAgentPapers
开源多智能体项目:
- AutoGPT:比较早期的一个项目
- Generative Agents:斯坦福小镇
- AgentSims:国内开源的类似斯坦福小镇(在类似ChatGPT的LLM在社区流行之后,如何评估大语言模型(LLM)的能力是一个悬而未决的问题。现有的评估方法存在以下缺点:(1)评估能力有限;(2)基准脆弱;(3)指标不客观。我们建议基于任务的评估,即LLM代理在模拟环境中完成任务,是解决上述问题的一劳永逸的解决方案)
- MetaGPT:类似ChatDev的软件开发多智能体框架
- CAMEL:任务导向型,沟通式多智能体协同框架,ChatDev的基础
引用
Github ChatDev Readme
解密Prompt系列18. LLM Agent之只有智能体的世界 - 风雨中的小七 - 博客园
GitHub - DSXiangLi/DecryptPrompt: 总结Prompt&LLM论文,开源数据&模型,AIGC应用
AutoGPT与LLM Agent解析
大模型应用的另一范式:大模型智能体