1 Title
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection(Yukun Su, Jingliang Deng, Ruizhou Sun, Guosheng Lin, and Qingyao Wu)【ransactions On MultiMedia (TMM) 2023】
2 Conclusion
This paper introduce a unified framework to tackle these issues from a unified view, term as UFGS (Unified Framework for Group-based Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch-structured similarities among the relevant objects.Furthermore, this paper propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation.
3 Good Sentences
1、To jointly address the aforementioned drawbacks. Specifically, to better reflect the relationships among group-based images, we first introduce a transformer block to insert into our network.(The motive of this method)
2、 As it is common that the encoder of the network only focuses on the most discriminative part of the objects,in order to avoid partial activation, we add the intra-MLP operation to produce global receptive fields. For each query pixel, it will match with its top-K potentially corresponding
pixels, which can help the network learn divergently.(The shortcomings and how to improve it)
3、Although transformer is not specially designed for image matching, it has the intrinsic ability to capture global cues across all input patch tokens and the transformer parallelizes the patch tokens, which is faster than some of the serial processing methods and can achieve real-time performance(The advantage of transformer block)
Introduction:
对象分割和目标检测是计算机视觉的核心任务。海量的基于群组的数据和动态的多帧数据的不断出现。因此,越来越多的研究集中在共同分割(CoS)、共同显著性检测(CoSD)和视频显著对象检测(VSOD)。在给定一组相关图像或视频中的几个相邻帧内,这些任务都共享具有相同属性的公共对象。它们本质上都旨在通过模仿人类视觉系统来发现和分割共同存在的物体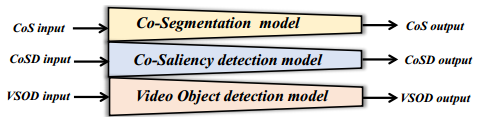 如图所示,以前的方法可能导致深度学习框架的易用性降低。可移植性和适用性也相对较差。
如图所示,以前的方法可能导致深度学习框架的易用性降低。可移植性和适用性也相对较差。
大多数共同对象分割和显著性检测网络都基于匹配策略,这使得网络能够提取和传播特征表示,不仅可以表达图像的个体属性,还可以反映基于组的图像之间的相关性和相互作用。但是这存在一些缺陷。比如说最近的一些工作利用光谱聚类来挖掘相应的对象区域。然而,这种方法是不稳定的,并且它们严重依赖于上游提取的特征。一些研究采用距离度量来对图像像素之间的关系进行建模,但它们只能处理成对的信息,并且很难处理成组的关系。一些研究试图使用基于细胞神经网络的注意力技术来建立基于组的图像之间的关系。然而,卷积运算会产生局部感受野,并且难以捕捉像素之间的长距离特征相关性,这可能会影响共同对象区域的学习表示。一些VSOD方法在光流的帮助下捕获帧之间的成对特征,这大大增加了网络运行成本并降低网络易用性。
本文设计了一个统一的框架,以解决上述所有缺陷。这个框架简称UFO (Unified Framework for CoObject Segmentation) 为了更准确地表达基于组的图像之间的关系,首先引入了一个transformer block,将图像特征分割为patch token。随后,通过自关注机制和多层感知器(MLP)结构,捕捉这些patch的全局依赖性。这样的设计有助于网络学习复杂的空间特征,并显现长程语义相关性,从而挖掘相关对象之间的patch结构的相似性。视觉Transformer固有的全局特征交互能力使得不用计算比较复杂的相似度矩阵。因此UFO算法的实时性比较强。
为了更准确地表达基于组的图像之间的关系,首先引入了一个transformer block,将图像特征分割为patch token。随后,通过自关注机制和多层感知器(MLP)结构,捕捉这些patch的全局依赖性。这样的设计有助于网络学习复杂的空间特征,并显现长程语义相关性,从而挖掘相关对象之间的patch结构的相似性。视觉Transformer固有的全局特征交互能力使得不用计算比较复杂的相似度矩阵。因此UFO算法的实时性比较强。
除了transformer block,还提出了一个MLP内学习模块( intra-MLP learning module)来增强单个图像。由于网络的编码器通常只关注对象中最不同的部分,所以为了避免部分激活,添加了intra-MLP模块以产生全局感受野。对于每个query像素,它将与其前K个潜在对应像素匹配,这可以帮助网络发散学习。然后产生自掩码并将其添加到解码器中以增强网络。
本文的主要贡献如下:
- 提出了一个基于组的图像协同对象分割(UFO)的统一框架,并尝试在不使用额外先验知识的情况下,使用相同的网络结构完成三个不同的任务(协同分割、协同显著性检测、视频显著对象检测)
- 引入了transformer块,通过自注意机制来捕捉基于组的图像之间的特征长程依赖关系。此外,还设计了一个MLP内部学习模块,以避免部分激活,从而进一步增强网络。
- 在不同任务中的四个CoS基准、三个CoSD基准和四个VSOD基准上的实验表明了我们提出的方法的有效性。它可以实现最先进的性能,实时达到140 FPS
Related Works:
联合分割(CoS):旨在同时分割多个图像中共同的物体或目标。这种技术的目标是在一组图像中找到共享相似性的区域,并将它们标记为同一对象或目标。Co-Segmentation通常用于处理包含相似物体的图像集,例如同一场景中的多个图像或包含相同物体的不同图像。
联合显著性检测(CoSD):旨在检测一组图像中共同显著的区域。与传统的显著性检测不同,CoSD关注的是多个图像中同时显著的区域,而不仅仅是单个图像中的显著性。目标是找到在一组图像中引起观察者共同关注的区域,这些区域可能对于整体场景的理解或者多图像的联合分析具有重要意义。这种技术在处理包含相似内容的多图像集合时很有用,例如同一场景的不同视角、同一对象的多个图像
视频突出目标检测(VSOD):旨在检测视频序列中显著的目标或区域。与静态图像的显著性检测类似,VSOD专注于在视频中找到引起观众注意的关键目标,这有助于理解视频内容、视频编辑、目标跟踪等应用。
METHODOLOGY:
整体框架:
给定一组包含共存对象的N个图像,记作 ,目标是产生准确的掩模输出,代表共享前景,记作
。为了实现目标,本文提出了UFO框架。
 如图所示,UFO框架是基于编码器(比如VGG16)来提取多尺度层特征{
如图所示,UFO框架是基于编码器(比如VGG16)来提取多尺度层特征{ },最后两层中的变换器块负责匹配多分辨率特征图中的共同对象相似性,生成增强的共同注意力图
。具体操作是将同类别嵌入响应α乘以解码器特征,并将帧内自掩码β添加到解码器特征。网络中的编码器-解码器结构类似于特征金字塔网络,其顶层特征通过跳跃连接中的低层特征上采样来融合。此外,UFO网络的输入不仅可以是一组具有相关对象的图像,还可以是多帧视频。
Transformer Block:
Preliminaries:在视觉转换器中,为了处理2D图像,输入图像将被划分为一系列平坦的2D patches。transformer中的所有层中针对每个token嵌入使用恒定的潜在向量size,记作D。每层由一个多头自注意层和一个多层感知器(MLP)操作组成。
transformer块有两个主要优点:(1)虽然transformer不是专门为图像匹配而设计的,但它具有捕获所有输入patch tokens的全局线索的内在能力(2)transformer将patch tokens并行化,这比一些串行处理方法更快,实时性能更好。
Semantic Patch Collaboration:transform模块的工作流程如下图所示。
在多分辨率特征图中的层上都使用transform块。为了方面描述,下面的介绍中省略
具体流程如下:首先要重塑(w和h表示特征图的空间大小,C是特征维度,B和N分别表示批量大小和组大小),将其转换为序列平整patch token
(P=N*h*c)。然后所有的token被送到transformer模块中去,并通过以下公式产生更新用的patch嵌入
。
 ,其中可训练线性投影将patch从原始C维映射到D维,再映射回C维。之后再把
,其中可训练线性投影将patch从原始C维映射到D维,再映射回C维。之后再把重塑回类似图像的特征图
。
由于卷积的归纳偏差,编码器卷积层提取的特征对特征的全局位置不敏感,只关心决定性的特征,这个模块可以增强卷积,增强全局联合对象区域的表示。
What it learns: 上图展示了transformers模块学习的内容,如在第三行中可以看到的,与第二行相比,transformers模块操作后,联合对象区域的相应图像块被高度激活,这说明变换器投影函数中的注意力机制可以自适应地关注目标区域,并分配更多的权重来从所有图像中捕获全局线索。此外,图片还可视化了所选图像patch的query注意力(即“香蕉”和企鹅“头”的端点),以显示它将匹配什么。第三行中的定性可视化进一步验证了transformers块可以帮助网络对不同位置像素之间的长程依赖性进行建模
上图展示了transformers模块学习的内容,如在第三行中可以看到的,与第二行相比,transformers模块操作后,联合对象区域的相应图像块被高度激活,这说明变换器投影函数中的注意力机制可以自适应地关注目标区域,并分配更多的权重来从所有图像中捕获全局线索。此外,图片还可视化了所选图像patch的query注意力(即“香蕉”和企鹅“头”的端点),以显示它将匹配什么。第三行中的定性可视化进一步验证了transformers块可以帮助网络对不同位置像素之间的长程依赖性进行建模
Intra-MLP module:

除了图像间联合,本文还提出了一个MLP内学习模块来激活单个图像内更多的自对象区域。如图所示,编码器的顶层特征图被视为不同的patches。本文认为,不同的patch不会像CNN(局部感受野)那样只与最近的patch匹配,因为长距离patch特征可能共享一些相似的响应(即颜色和纹理)受此启发,可以通过融合非局部语义信息来改进对象学习表示。
具体而言,顶层特征被重塑成
,其中Q=h*w是patch的数量。然后,构建一个矩阵
,表示单个图像中每个patch的相似性。具体来说,使用
2-距离来测量两个任意patches之间的关系。由于使用归一化的信道特征,通过去除常数,矩阵M可以表示为
![]() 为了避免与自身匹配的情况发生,M的对角线上的元素被设置为负无穷大。对于每个query patch,通过对矩阵执行KNN运算,可以选择其潜在对应的target patch。然后,它将输出Q×K形状的张量,该张量表示patch及其前K个语义相关的patches。之后就可以得到
为了避免与自身匹配的情况发生,M的对角线上的元素被设置为负无穷大。对于每个query patch,通过对矩阵执行KNN运算,可以选择其潜在对应的target patch。然后,它将输出Q×K形状的张量,该张量表示patch及其前K个语义相关的patches。之后就可以得到然后用MAX(·)运算对其进行MLP以获得更新的特征
,
![]() 其中MAX是元素最大运算。这保证了MLP和对称函数的组合可以近似任何连续集合函数。
其中MAX是元素最大运算。这保证了MLP和对称函数的组合可以近似任何连续集合函数。
该步骤的目的是将目标特征与其前K个特征的外观变化信息相结合,并通过感知器进行学习。最后,把重塑成
并使用Sigmoid(·)对Z产生自掩模β。
Network Training:
由于还可以使用同类别信息,因此顶层通过卷积层在GAP层之后产生载体α,FC层对嵌入α进行分类以预测联合类别标签
。然后,将α和自掩码β结合起来,以条件归一化的方式增强解码器层,该方式使用学习的尺度(scale)和偏差(bias)进行调制。具体来说,变量α是通过使用丰富的语义感知线索来排除联合对象区域中的干扰物的学习尺度调制参数。变量β作为偏置参数,通过赋予空间感知信息来补充和突出目标。解码器利用跳跃连接结构来融合来自编码器的低分辨率层特征。最终,它输出联合对象掩码。
Objective Function:
首先,利用分类损失对语义信息的梯度传播进行更新:![]() ,其中
,其中是交叉熵损失,y是ground-truth类的标签,
是预测的标签。
然后,用加权二值交叉熵(WBCE)损失进行逐像素分割:
其中H和W表示图像的高度和宽度,是ground truth掩码,P(i,j)是预测概率,γ是图像中所有正像素与所有像素之比。
再然后,IoU损失也被广泛用于评估分割精度,如下:
通过对上述所有损失函数进行端到端的整合,对整个框架进行优化:
EXPERIMENTS
Datasets:
在PASCAL-VOC、iCoseg、Internet和MSRC四个联合分割基准上进行了实验。而对于联合显著性检测,该方法在三个最大和最具挑战性的基准数据集上进行了评估,包括Cosal2015, CoCA和CoSOD3k。在视频显著目标检测方面,在四个公共数据集上对该方法进行基准测试,即DAVIS16(30个视频训练和20个视频验证),FBMS(29个训练视频和30个测试视频),ViSal包含17个用于测试的视频序列)和SegV2(包含13个用于测试的片段)。
评价指标:
对于目标联合分割的性能评估,采用精度(P)和Jaccard指数(J)。
对于联合显著性检测和视频显著性检测,采用平均绝对误差MAE、F-measure 、E-measure
和S-measure
四个评价指标进行比较。
训练细节:
输入图像组I包含N = 5张图像。小批量大小设置为8 ×N。为了公平比较,严格遵循与[34],[9]相同的设置,使用VGG16作为主干,除非另有说明,否则训练和测试的图像都调整为224 ×224。使用4个transformer模块,有4个多头,K默认设置为4。transformer线性投影函数的特征维数为782。
在联合分割(co-segmentation, CoS)和联合显著性检测(co-saliency detection, CoSD)任务上,遵循[38],[13]使用COCO-SEG进行训练,其中包含了属于78组的20万张图像。每个图像都有一个手动标记的带有联合分类标签的二值掩码,并利用Adam算法作为优化策略,β1 = 0.9, β2 = 0.999。学习速率最初设置为1e-5,每25,000步减少一半。整个训练大约需要20个小时,总共需要10万步。
在视频显著性检测任务(VSOD)上,大多数方法首先在静态显著性数据集上进行预训练。本文首先在CoS和CoSD任务上加载预训练的权值,并使用DUT数据集来训练网络,以避免过拟合。然后,由于VSOD任务中没有类标签,因此本文冻结了联合分类层,在DAVIS16(30个片段)和FBMS(29个片段)的组合数据集上训练,耗时约4小时。
所有实验都是在RTX 3090 GPU上进行的。对于所有的运行时分析,本文报告了在Titan Xp GPU上测试的结果进行公平比较。
实验结果就不说了,反正对于以前的方法都有提升,另外就是本文还进行了消融实验