
Abstract
影响力最大化是在社交网络中选择个体子集以最大化网络中传播的影响力的问题。随着社交网站的普及和病毒式营销的发展,这个问题的重要性已经增加。在社交网络图中找到最具影响力的顶点(称为种子)是一个 NP 难题,因此非常耗时。人们提出了许多启发式方法,以在更短的时间内找到近乎完美的解决方案。
在本文中,我们提出了两种启发式算法来找到好的种子集。我们在几个知名数据集上评估我们的算法,结果表明我们的启发式方法在更短的时间内(运行时间提高了 10%)针对该问题取得了最佳结果(影响力传播提高了 800 倍)。
I. INTRODUCTION
社交网络中人们的互动提供了大量有关他们的行为和社交图结构的信息。它还使社交网络成为传播信息、信仰、创新等的良好平台。社交网络影响力传播的重要应用之一是病毒式营销。例如,考虑一家想要在社交网络中营销其产品的公司。一种简单且低成本的方法是选择一部分人向他们提供产品,这样他们就会鼓励他们的朋友购买该产品。这种行为就像在社会中传播病毒一样。此类营销的重要部分是最初选择最有影响力的个人。这个问题被称为影响力最大化。
影响力最大化问题首先由 Domingos 和 Richardson 提出[1]、[2]。肯佩等人。 [3]正式定义了该问题并证明它是NP-hard问题。他们还引入了两种用于影响力传播的单调和子模扩散模型,即独立级联模型和线性阈值模型,并证明贪婪爬山算法将这些模型的解逼近于最优解的 63% 以内。
由于贪心算法需要运行数千次模拟来找出每个顶点的边际影响,因此非常耗时,因此提出了许多启发式方法来提高其性能。尽管启发式方法减少了运行时间,但在大规模网络中它们仍然很耗时,大多数社交网络都是如此。另一方面,即使在大规模网络上,基于度中心性的启发式方法也非常快。尽管它们不保证解的准确性,但它们找到的解与贪心算法的解一样好。
在本文中,我们提出了两种基于最大程度的启发式方法,它们运行时间非常快,并改进了所有先前基于程度的启发式方法的结果。换句话说,我们的算法的结果接近贪心算法产生的结果,而其运行时间接近基于度的启发式算法。
本文的其余部分安排如下。相关工作在第二部分进行回顾。第三节描述了问题的正式定义。我们在第四节中提出了我们的启发式方法,并在第五节中介绍了实验结果。最后,我们在第六节中总结了本文。
II. RELATED WORK
Kempe 等人正式定义了影响力最大化问题。 [3]并被证明是NP困难的。他们提出了一种贪婪爬山算法,该算法可以为他们引入的两个模型提供最优解的 (1 − 1 e − ε) 因子内的解。在算法的逼近比中,e是自然对数的底数,ε是任意正实数,是蒙特卡罗模拟的误差。选择较小的 ε 值会增加运行时间,而选择较大的 ε 值会降低结果质量。在他们的算法中,最有影响力的顶点是根据其估计的边际影响力来选择的。由于估计的边际影响是通过大量模拟计算的,因此该算法效率低下。
为了提高计算效率,人们进行了许多研究。莱斯科维奇等人。 [4] 提出了 CostEffective Lazy Forward (CELF) 优化,可减少使用目标函数的子模块性属性计算影响力传播的成本。
陈等人。 [5]针对独立级联和加权级联模型提出了新的贪婪算法。他们通过将自己的算法与 CELF 相结合,使贪婪算法变得更快。他们还提出了度折扣启发式算法,它可以对贪婪算法产生密切的影响传播,同时比简单的度数和距离中心性启发式算法更快并且返回更好的解决方案。
为了避免重复运行影响传播模拟,Borgs 等人。 [6]根据原图中顶点的反向可达概率生成随机超图,并选择超图中被超边覆盖最多的k个顶点。它们保证解的近似比为 (1 − 1 e − ε),概率至少为 1 − 1/nl。唐等人。 [7]、[8]提出了TIM和IMM来弥补Borgs等人算法[6]的缺点,并改进了其运行时间。
Bucur 和 Iacca [9] 以及 Kr ̈ omer 和 Nowakov ́ a [10] 使用遗传算法来解决影响力最大化问题。 Weskida 和 Michalski [11] 在他们的遗传算法中使用 GPU 加速来提高其效率。
有一些基于社区的算法用于影响最大化问题,将图划分为小子图并从每个子图中选择最有影响力的顶点。陈等人。 [12] 使用 H-Clustering 算法和 Manaskasemsak 等人。 [13]使用马尔可夫聚类算法进行社区检测。宋等人。 [14]将图划分为社区,然后通过动态规划算法选择最有影响力的顶点。
III. PROBLEM DEFINITION
在本节中,我们正式定义影响最大化问题和独立级联扩散模型。
我们将社交网络视为无向图 G = (V, E),其中 V 是大小为 n 的个体集合,E 是大小为 m 的关系集合。
令 S 为被选择来启动影响延长的顶点的子集,I(S) 为 S 传播的影响。
A. Diffusion Model
影响力传播有多种扩散模型。在本文中,我们重点关注独立级联模型(ICM)。在每条边 (u, v) 的独立级联模型中,新激活的顶点 u 可以以概率 pu,v ∈ [0, 1] 激活 v。扩散过程如下:设 Si 为时间戳 i 中激活的顶点集合,在时间戳 i +1 中,每个顶点 u ∈ Si 有机会激活其每个不活动的邻居。一旦你尝试激活邻居v,无论成功与否,你都不会在后续步骤中尝试激活v。此外,每个激活的顶点在所有后续时间戳中保持活动状态。当不再有可能的激活时,该过程终止。
B. Influence Maximization Problem
在影响力最大化问题中,给定一个图 G、一个常数 k 和一个扩散模型 M,我们需要一个具有最大影响力传播的 k 个顶点的集合 S,I(S)。在本文中,我们关注独立级联模型为M,并将算法扩展到其他模型留待将来的工作。
IV. PROPOSED ALGORITHMS
在本节中,我们将描述独立级联(IC)模型下影响最大化问题的启发式方法。尽管贪心算法及其变体在近似率方面保证了解的优良性,但它们在大规模社交网络上非常耗时。由于启发式方法速度更快并且适用于大型网络,因此我们提出了两种基于度中心性的新颖启发式方法,它们在短时间内运行时几乎与现有技术的解决方案相匹配。
度中心启发法选择具有最大度数的 k 个顶点作为最有影响力的个体。 Chen 等人提出的另一种清晰且更准确的方法称为单一折扣。 [5]的工作原理如下。当选择顶点 u 作为种子时,每个邻居 v 的度根据它们具有的公共边的数量而减小。
尽管这些启发式方法具有很大的影响范围,但它们不会返回适当的解决方案,因为当选择顶点 u 作为种子时,其邻居 v 将受到 u 的影响。此外,当概率 p 较高时,u 的影响甚至对其多跳邻居的影响也是显着的 Chen 等人。 [5]在度折扣启发式中,忽略了对多跳邻居的间接影响,并根据预期的相邻活动顶点数量来折扣邻居的度。由于在他们的算法中激活的顶点数量和度数折扣量很小,所以它仍然不能很好地工作。我们提出的基于度的算法考虑了社交网络的一些特征,包括最大度数的顶点的接近度和多边的数量,改善了影响力的传播。
在社交网络中,度数最大的顶点是相邻的。换句话说,当选择度数最大的顶点u时,向其邻居传播影响的概率就很高。随着 u 与其邻居之间的跳数增加,对它们的影响量减少。我们的启发法利用了这个问题。
我们算法的目标是选择具有最大度数的 k 个顶点,避免选择有可能受到先前选择的种子影响的顶点。为了达到这个目标,我们提出了两种方法:忽略邻居和递减邻居的度数。
A. Ignoring The Neighbors
在该方法的第一步中,我们选择度数最大的顶点 u 作为种子。由于 u 的可达邻居将受到它的影响,与它们具有最大度数不同,我们将它们从顶点列表中删除,并从剩余的顶点中选择具有最大度数的下一个种子文章。当选择了 k 个种子时,该过程终止。为了更多描述,当在每个步骤中选择种子 u 时,其具有 h 跳的邻居是通过广度优先搜索确定的。然后,我们将它们从顶点列表中删除,以避免在下一步中选择它们,并从剩余的顶点中选择下一个种子。如前所述,当 u 与其可达邻居 v 之间的跳数增加时,对 v 的影响范围会减小。因此,我们删除了可到达的邻居,这些邻居与种子之间有 h 跳。 h是根据独立级联模型中考虑的影响扩散概率来确定的。根据我们在不同数据集上的实验,h的合适值可以是由方程1计算的四舍五入的数字。因此,增加p会导致h增加。

B. Descending Degree Decrease
在该方法中,第一步选择度数最大的顶点u作为种子。下一步,降低其可达邻居的程度以降低其优先级。下一个种子是在具有更新度数的顶点中选择的。该过程持续进行,直到在种子集中选择了 k 个顶点。对于每个可达邻居 v,其度数的减少是根据 v 和所选种子之间的跳数来计算的。由于跳数越多,激活概率越少,因此在该方法中,跳数越多,度数的下降就越少。
更详细地说,对于每个选定的种子 u,其度数减小到常数值 α。
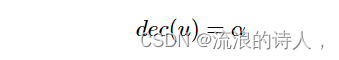
其中 dec(u) 是顶点 u 的度数减少量,对于每个可达邻居 v,其度数减少量计算公式为 2,其中 c 是 u 和 v 之间的多重边数,f (p) 是函数影响概率 p
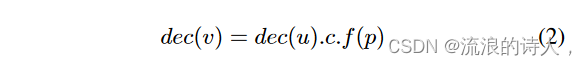
f (p) 是概率 p 的函数,我们考虑如下:

因为少量的 dec 不会对输出产生太大影响。我们忽略 dec < 0.1。因此,可达邻居的程度不断降低,直到 dec 值大于误差值 e。根据我们的实验,e的合适值为0.1。
α 和 β 是常数值,我们的实验表明值 50 和 10 可能是随后它们的合适值。
V. EXPERIMENTS
在本节中,我们将利用之前在几个现实数据集上的一些工作来评估最大程度启发式的实验。我们表明,我们的最大程度启发式方法在以下方面优于先前基于程度的启发式方法:影响力在短时间内扩散,同时输出接近 (1 − 1 e ) 近似算法的解。我们还研究了 p 值对启发式操作的影响
A. Experiment setup
我们在相关研究中常用的两个现实数据集上评估我们的实现,包括[5]。第一个数据集是 NetHEPT,n = 15233,m = 58891,第二个数据集是 NetPHY,n = 37154,m = 231584。
我们将 NeighborsRemove 和 DegreeDecrease 所代表的算法与作者提供的名为 SingleDiscount、DegreeDiscount [5]、TIM [7] 和 IMM [8] 的四种算法进行比较。我们的算法用 c 语言实现,并使用 gcc 6.2.1 编译,并在具有 3.60 × 4 GHz Core i7-3820 Intel 和 32G 内存的系统上运行。
我们使用独立级联模型来计算实验中影响的传播,考虑概率 p = 0.01 和 p = 0.1。
B. Experiment results
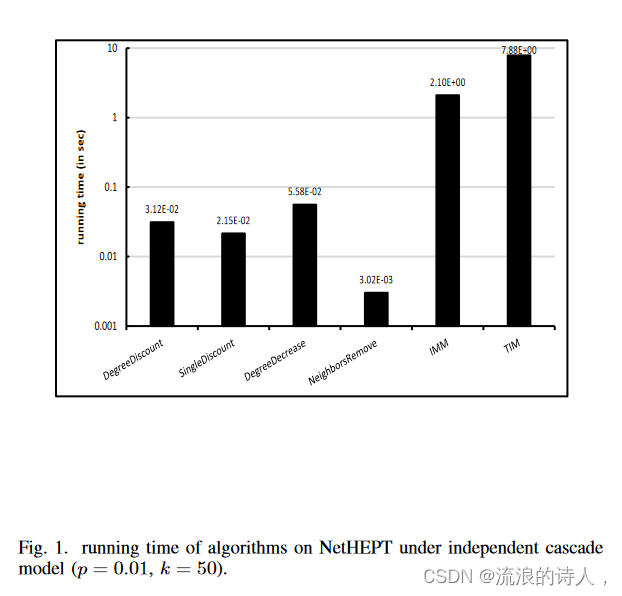
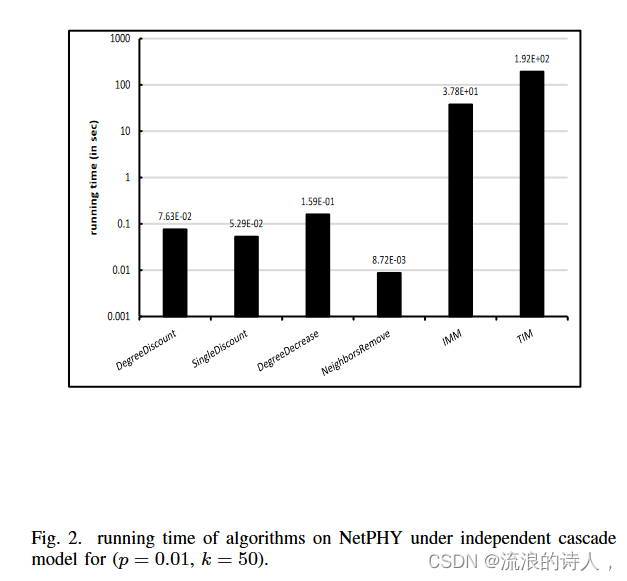
图 1 和图 2 显示了不同算法在独立级联模型下的运行时间,p = 0.01 随后在 NetHEPT 和 NetPHY 上。我们发现,度中心启发法比 TIM 和 IMM 快得多。 DegreeDecrease 算法的运行时间接近 DegreeDiscount 和 SingleDiscount,而 NeighborsRemove 的运行速度比所有算法快 10%。
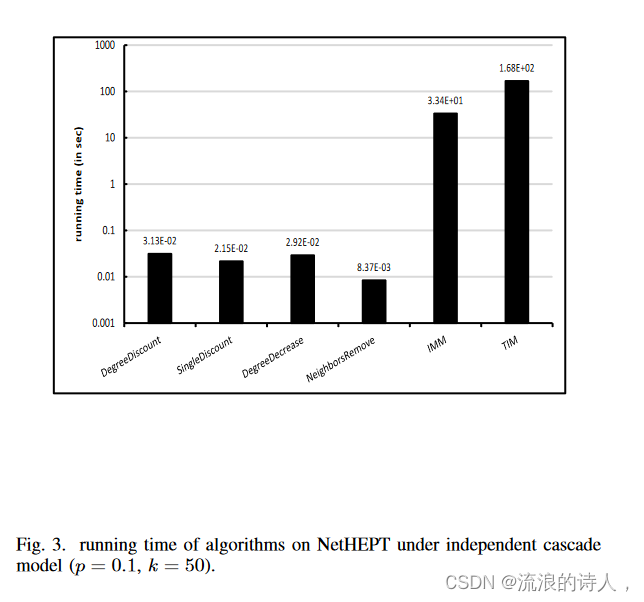
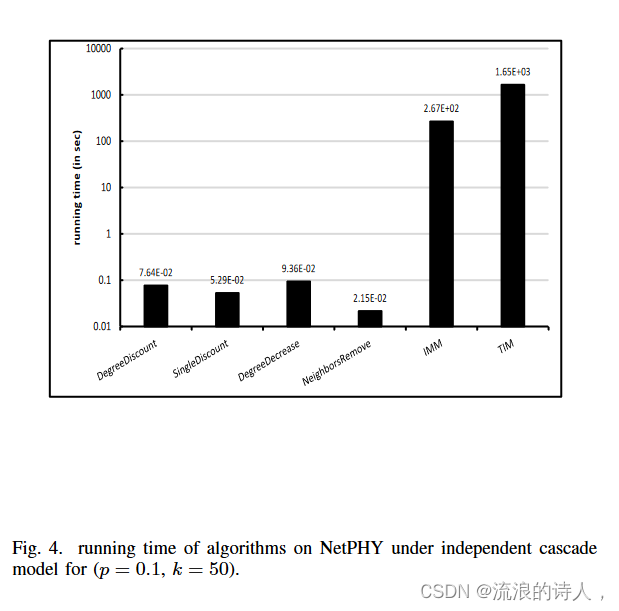
图 3 和图 4 显示了 p = 0.1 时所有算法的运行时间,并证实了我们的算法在 p 值更大时具有良好的效率。
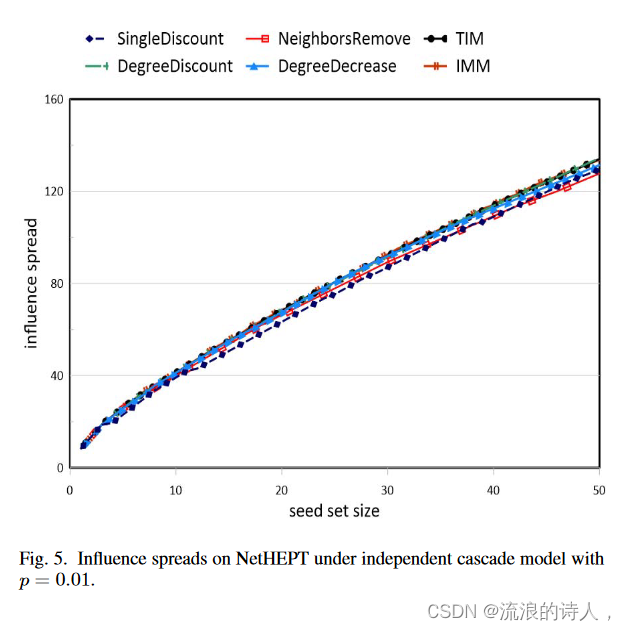
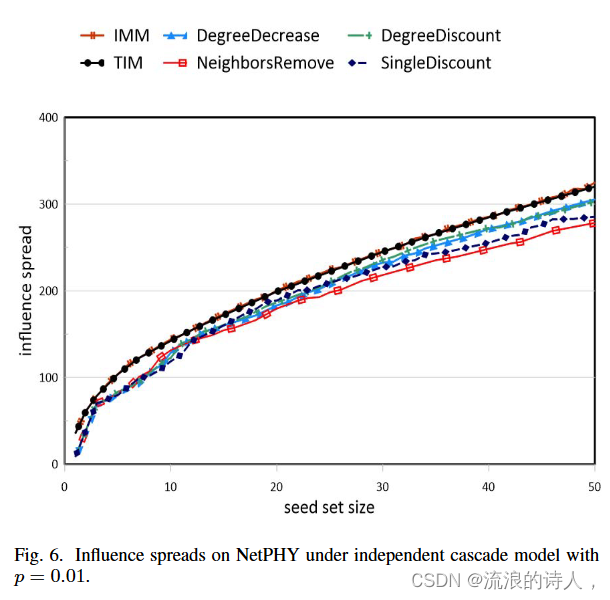
图 5 和图 6 报告了在 p =0.01 的独立级联模型下不同算法的影响力分布。可以看出,虽然我们的算法在 p 值较大时表现良好,但即使在 p = 0.01 时它们也能很好地工作,并且返回与 TIM 和 IMM 的解接近的解。
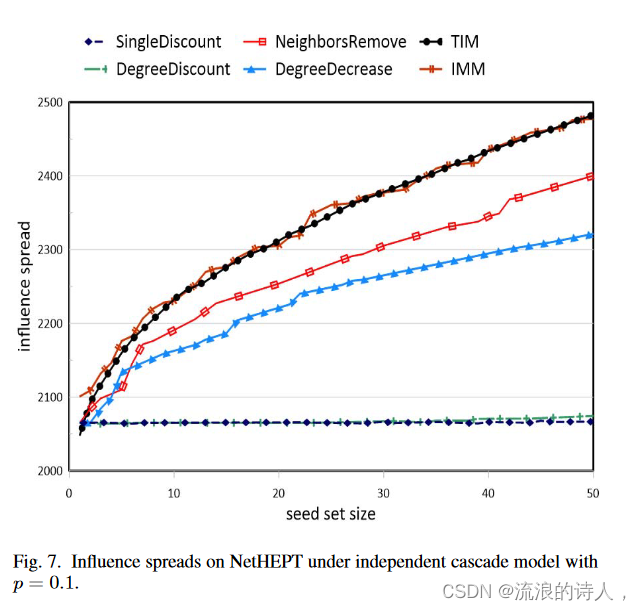

图7和图8显示了p=0.1的ICM模型下算法的影响力分布。很明显,我们基于最大程度的启发式算法在 NetPHY 上的影响力传播方面明显优于 DegreeDiscount,提高了近 800 倍。这种显着改进的原因是 p 值的增加导致我们的算法效率更高。当 p 的值较高时,影响的传播会增加,我们的策略是避免选择受影响概率较高的顶点。因此所选择的种子集将是一个合适的解决方案。一般来说,当考虑独立级联模型中的高影响传播概率时,我们的算法的效率更加明确。而且,在没有任何复杂的计算的情况下,NeighboersRemove和DegreeDecrease的影响范围接近TIM和IMM。我们的算法的总体良好性能得到了清晰的体现。
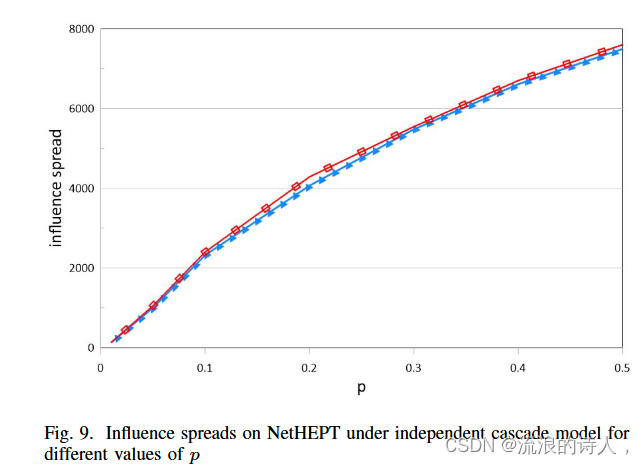
图9显示了我们的算法在不同p值的独立级联模型下的影响扩散。可以看出,我们的算法的影响扩散随着独立级联模型中概率值p的增加而显着增加。
VI. CONCLUSION
在本文中,我们针对独立级联模型下的影响最大化问题,提出了考虑最大度顶点的接近度的基于最大度的启发式方法。实验表明,我们的启发式方法在网络影响力的传播方面优于以前的度中心启发式方法,它接近于近似保证解决方案的算法的输出。而且,它们运行的时间很短。由于保证输出准确性的算法在大规模网络中非常耗时,因此提出速度快的启发式方法可能是一种有效的解决方案。在未来的工作中,我们将研究其他级联模型的基于最大度的启发式方法。此外,我们还将研究更精准的策略,以提高影响力的快速传播。























![【自然语言处理】NLP入门(八):1、正则表达式与Python中的实现(8):正则表达式元字符:.、[]、^、$、*、+、?、{m,n}](https://img-blog.csdnimg.cn/direct/d103bc5a3e714415bfee0b61cd6a5090.png)




