什么是ClickHouse?
官方给出的回答是,它是一个高性能、列式存储、基于SQL、供在线分析处理的数据库管理系统
当然这边不得不提到OLAP(Online Analytical Processing)概念的出现
随着大数据的风吹起,传统数据库在险中求生,新生的大数据分析引擎如雨后春笋般出现。
为了更好地利用数据,发挥数据的价值,让静默的数据会"说话",就需要分析引擎具备能够快速读取、分析、产出统计结果的能力,那么大数据量、快速实时查询此外还需要尽可能低成本使用成为市场需求。
与ClickHouse类似的市场产品有:
- Apache Cassandra(特别是配合CQL查询时,用于大规模分布式环境)
- Apache Kylin(针对大数据OLAP分析而设计,与Hadoop生态集成紧密)
- IBM Db2 BLU(支持列式存储和内存计算,适用于数据仓库场景)
- Actian Vector(高性能列式数据库,专为快速数据分析打造)
- Kyligence(基于Apache Kylin构建的企业级智能数据平台)
- Apache Pinot(实时 OLAP 数据库,面向低延迟和高并发场景)
- Druid(专为实时事件流处理和快速聚合查询设计的列式数据库)
- Vertica(HP开发的列式MPP数据库,后被Micro Focus收购)
- Presto(开源的分布式SQL查询引擎,适合交互式分析查询)
- Cloudera Impala(在Hadoop之上提供快速SQL查询功能)
- Oracle Exadata(Oracle优化的数据库机器,特别针对数据仓库场景
- Microsoft SQL Server Analysis Services (SSAS) 或 Azure Synapse Analytics
- Teradata(专长于大规模数据仓库解决方案)
- Greenplum Database(开源MPP数据仓库系统)
那么ClickHouse有哪些历史,在市场竞争力上又有哪些优劣势呢?
关于发展历史
ClickHouse是由俄罗斯搜索引擎巨头Yandex内部开发的数据存储和分析系统。
该项目始于2008年,其初始设计目标是为了支持Yandex Metrica产品,这是一个Web流量分析服务,需要处理海量数据并实现快速的在线分析查询(OLAP)。随着技术的发展和完善,ClickHouse逐渐成为一个独立且功能强大的列式数据库管理系统。
在2016年6月15日,Yandex正式将ClickHouse作为开源项目对外发布
截至2024年,ClickHouse持续保持快速迭代,定期发布新版本,它已成为OLAP领域的重要参与者之一,与Apache Druid、Vertica、Greenplum以及其他现代数据仓库解决方案共同竞争市场,并在许多实际应用案例中展现出卓越的性价比和稳定性。
存在的优势与劣势
正如官网简单介绍的突出几点
优势1:高性能查询处理
特别适合大数据分析场景下的实时或近实时 OLAP 查询。它通过列式存储、向量化执行引擎和高度优化的数据压缩算法,能够快速处理大规模数据集。
优势2:列式存储与高效压缩
数据按列存储,使得在进行聚合计算时仅需读取相关列,大大减少了I/O成本,并且同列数据类型相同的情况下可以实现高倍率的压缩,进一步减少存储空间和提升读取速度。
优势3:分布式架构
分布式无主架构,支持灵活的扩缩容,成为企业生产的重要考量之一。
优势4:SQL兼容性
相较于传统大数据引擎,对SQL的兼容性不足上,ClickHouse 提供了丰富的 SQL 支持,积极与SpringBoot大框架靠拢,能够像查询传统数据库那样查询ClickHouse,降低技术门槛,更快地获得市场的认可。此外针对数据分析需求增加了许多高级特性,比如窗口函数、数组和其他复杂数据类型的支持,以及用于数据预处理的内置聚合函数和表引擎。
优势5:开源
ClickHouse 是活跃的开源项目,允许用户根据具体业务需求自由定制,这绝对是中小型企业生产选型的重要考量之一。

对于它的不足也是情理之中
劣势1:不支持事务
它无法做到传统数据库的事务特性,它更适合那些对最终一致性容忍度较高的分析型工作负载。
劣势2:DML的效率不高
正如它的自我介绍,它是适用于OLAP的引擎,数据分析引擎主要面向大数据读进行优化,对于写入、更新、删除的DML操作生效效率都是相对偏低的,不适合于大数据量实时写入的场景。
劣势3:管理、监控与安全性功能不足
总体发展的时间还不长,对于外围的管理、监控与安全性上面稍显不足,但是相信用的人、贡献的人越多,会发展地越来越完善。
什么是它风靡的原因?
OLAP引擎那么多,列式存储的数据库也很多,到底为什么它的受众如此之多?Github star 33.3K
核心的两个原因体现在了官网:查询快 & 占用小
查询快是OLAP技术选型首要考虑的点,不快怎么能做在线实时分析呢?查询快取决于几点:
列式存储:ClickHouse采用了列式存储格式,相比于传统的行式存储,列式存储在进行大数据分析时具有显著优势。当查询仅涉及部分列时,只需要读取相关的列数据,大大减少了磁盘I/O和内存带宽消耗
向量化执行引擎:ClickHouse使用向量化执行模型,在处理查询时一次性操作一整批数据,更充分地利用CPU缓存,提高计算效率。
高度优化的算法与代码库:由C++编写,代码经过深度优化以追求极致性能,包括但不限于高效的压缩算法、索引结构以及函数库等。
稀疏索引与并发处理能力:支持稀疏索引,采用MPP架构
SQL解析,查询优化,预聚合表和物化视图
占用小则是另一个重要的点。对于传统的存储,冷数据尝尝放起来备份不被使用,占用很多存储介质,一旦要用就还需要经历痛苦的恢复,这也是历史数据用不起来,数据分析受限的点。相比市面其他的分析引擎,它可以在有限的存储内放下更多的数据,数据分析范围扩大,分析结果的准确性和全面性一定会有所提升,那就在有限空间带来更大的价值。占用小则取决于:
- 依旧是列式存储,不仅结合查询的特点做到了查询效率的提升,还更有效地利用了数据块的存储,数据在物理上是连续存放的,同类型数据具有更好的局部性规律,更适合进行高效的压缩
- 高效的压缩算法:支持多种压缩算法,如LZ4、ZSTD等
- 排序和字典编码优化:利用排序和字典编码技术进一步压缩数据量
- 数据块压缩:每个数据块独立进行压缩
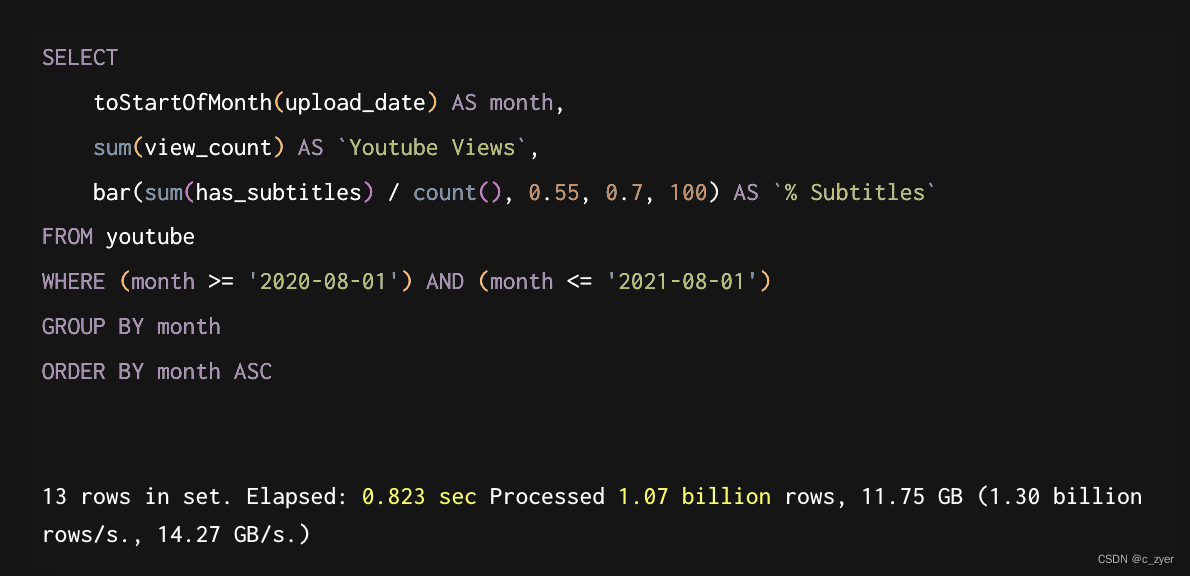
关于列式和行式DB的写入性能的比对官网有详细的数据,可以移步了解点这里>>
如果喜欢我的文章的话,可以去GitHub上给一个免费的关注吗?






















![BUU [MRCTF2020]套娃](https://img-blog.csdnimg.cn/img_convert/98480b49cebbce4191102671ab736d0a.png)