摘要
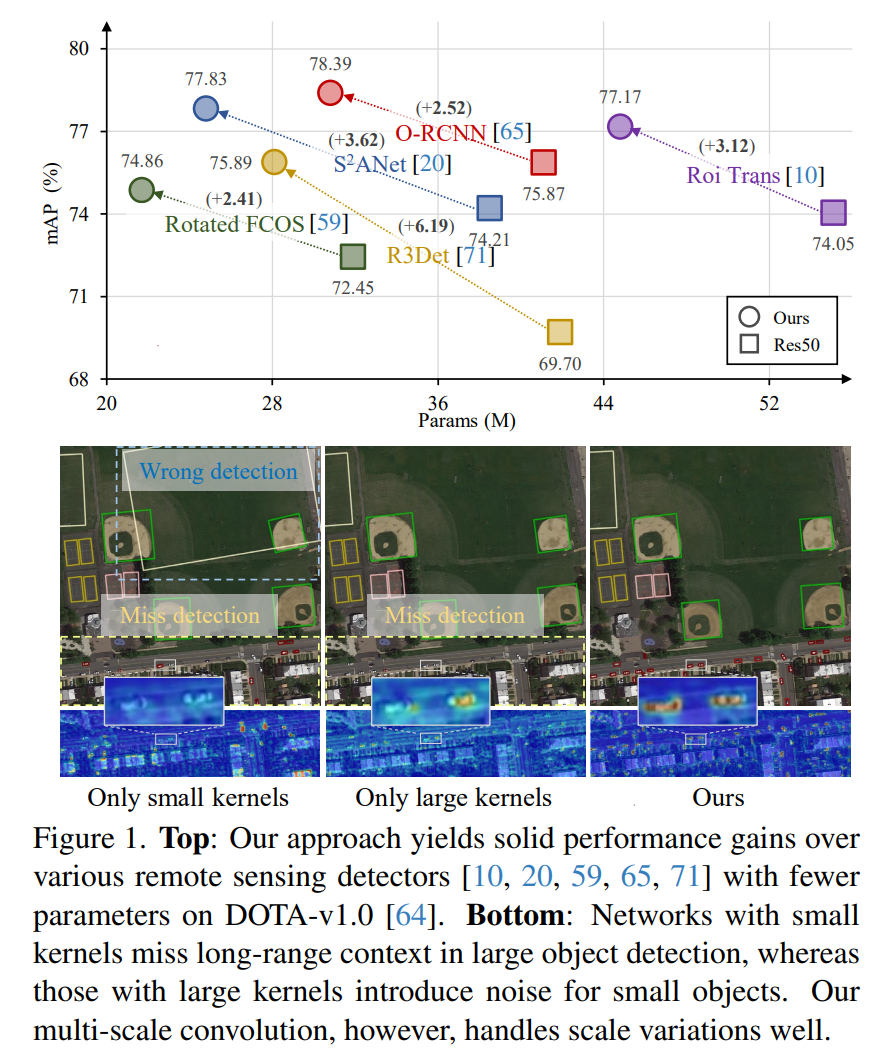
本文使用HWD改进下采样,在YoloV8分割测试中实现涨点。改进简单容易理解,推荐大家使用!
论文解读
在卷积神经网络(CNNs)中,极大池化或跨行卷积等下采样操作被广泛用于聚合局部特征、扩大感受野和最小化计算开销。然而,对于语义分割任务,在局部邻域上汇集特征可能会导致重要空间信息的丢失,这对于逐像素预测至关重要。为了解决这个问题,作者引入了一个简单而有效的下采样操作,称为基于Haar小波的下采样(HWD)模块。该模块可以很容易地集成到CNN中,以增强语义分割模型的性能。HWD的核心思想是利用Haar小波变换降低特征图的空间分辨率,同时尽可能多地保留信息。所提出的HWD模块能够(1)有效地提高不同CNN架构下不同模态图像数据集的分割性能;(2)与传统下采样方法相比,可以有效降低信息的不确定性。
亮点:
• 为卷积神经网络(CNNs)提出了一种新颖的基于小波的下采样模块(HWD)。首次尝试探索在深度卷积神经网络(DCNNs)的下采样阶段禁止(或阻碍)信息丢失的可行性,以改善语义分割任务的性能。
• 探索了卷积神经网络中信息不确定性的度量方法,并提出了一种新的指标,即特征熵指数(FEI),用于评估下采样特征图与预测结果之间的信息不确定性或特征重要性。
• 提出的HWD模块可以直接替换跨行卷积或池化层,而不会显著增加计算开销,并且可以轻松地集成到当前的分割架构中。与七种最先进的分割方法相比,综合实验证明了HWD模块的有效性。

过大量的实验证明,本研究提出的下采样新方法可以轻松的整合到目前主流的深度学习语义分割模型中,在多个公开及私有数据集中都获得分割性能的显著提升,且整体计算效率没有显著区别。此外,对采样后的特征图质量进行独立评估表明,相对于传统的下采样操作,本研究提出的无损下采样技术在分割模型中保留了目标物体的更多的上下文信息,从而间接证明了下采样操作中最大限度保留特征信息对于深度学习语义分割任务的重要性。
YoloV8官方结果
YOLOv8l summary (fused): 268 layers, 43631280 parameters, 0 gradients, 165.0 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 29/29 [
all 230 1412 0.922 0.957 0.986 0.737
c17 230 131 0.973 0.992 0.995 0.825
c5 230 68 0.945 1 0.995 0.836
helicopter 230 43 0.96 0.907 0.951 0.607
c130 230 85 0.984 1 0.995 0.655
f16 230 57 0.955 0.965 0.985 0.669
b2 230 2 0.704 1 0.995 0.722
other 230 86 0.903 0.942 0.963 0.534
b52 230 70 0.96 0.971 0.978 0.831
kc10 230 62 0.999 0.984 0.99 0.847
command 230 40 0.97 1 0.995 0.811
f15 230 123 0.891 1 0.992 0.701
kc135 230 91 0.971 0.989 0.986 0.712
a10 230 27 1 0.555 0.899 0.456
b1 230 20 0.972 1 0.995 0.793
aew 230 25 0.945 1 0.99 0.784
f22 230 17 0.913 1 0.995 0.725
p3 230 105 0.99 1 0.995 0.801
p8 230 1 0.637 1 0.995 0.597
f35 230 32 0.939 0.938 0.978 0.574
f18 230 125 0.985 0.992 0.987 0.817
v22 230 41 0.983 1 0.995 0.69
su-27 230 31 0.925 1 0.995 0.859
il-38 230 27 0.972 1 0.995 0.811
tu-134 230 1 0.663 1 0.995 0.895
su-33 230 2 1 0.611 0.995 0.796
an-70 230 2 0.766 1 0.995 0.73
tu-22 230 98 0.984 1 0.995 0.831
Speed: 0.2ms preprocess, 3.8ms inference, 0.0ms loss, 0.8ms postprocess per image
改进方法
安装pytorch_wavelets,执行命令:
pip install pytorch_wavelets -i https://pypi.tuna.tsinghua.edu.cn/simple
安装
pip install pywavelets -i https://pypi.tuna.tsinghua.edu.cn/simple
修改lowlevel.py,路径如下图:
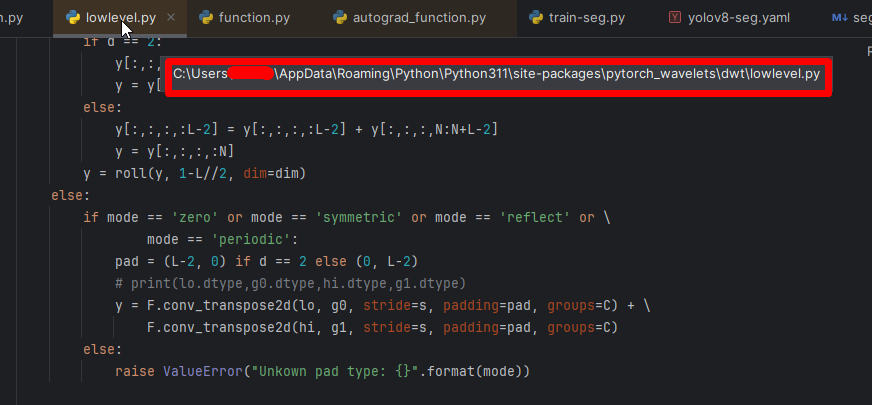
如果找不到也不用担心,训练的时候回报错,根据报错的信息也能找到。
修改lowlevel.py的sfb1d函数,在250左右,如下图:
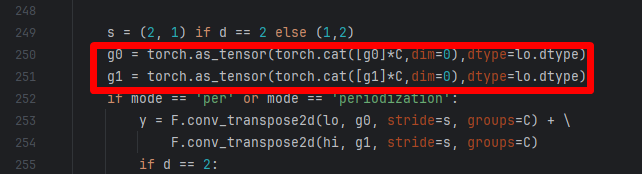
代码如下:
g0 = torch.as_tensor(torch.cat([g0]*C,dim=0),dtype=lo.dtype)
g1 = torch.as_tensor(torch.cat([g1]*C,dim=0),dtype=lo.dtype)
g0和g1的类型和lo的类型保持一致。否则,无法使用半精度混合训练。
如果这样不行,则需要下载pytorch_wavelets,在pytorch_wavelets源码中修改后,编译安装。
github链接:https://github.com/fbcotter/pytorch_wavelets,下载后,解压,找到lowlevel.py,如下图:
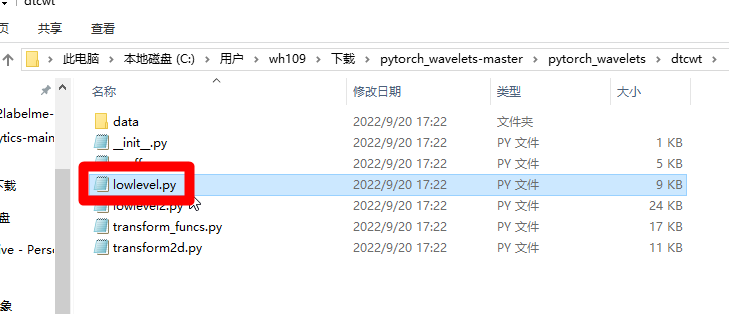
修改方法同上。
在block.py中加入HWD模块,如下图:
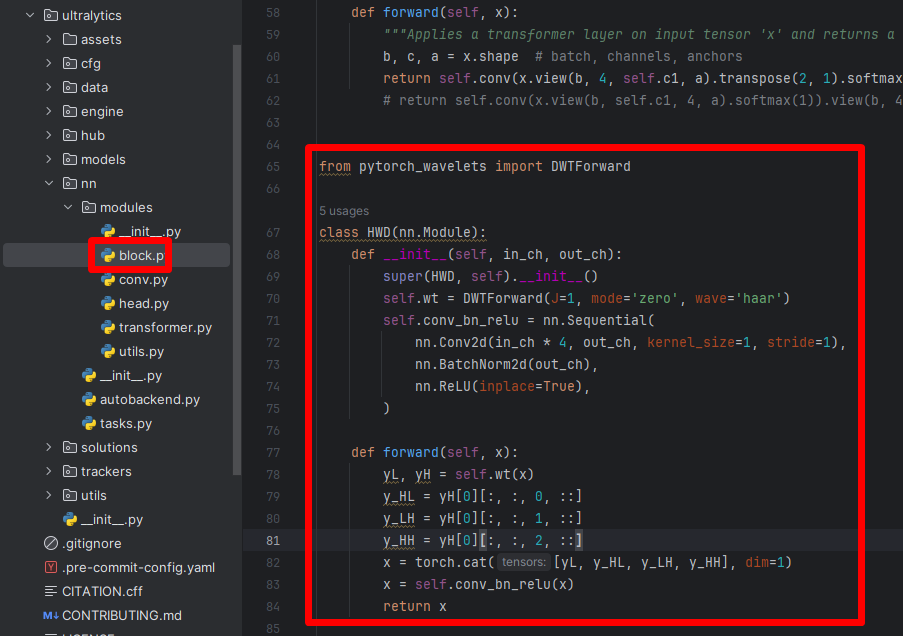
代码:
from pytorch_wavelets import DWTForward
class HWD(nn.Module):
def __init__(self, in_ch, out_ch):
super(HWD, self).__init__()
self.wt = DWTForward(J=1, mode='zero', wave='haar')
self.conv_bn_relu = nn.Sequential(
nn.Conv2d(in_ch * 4, out_ch, kernel_size=1, stride=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
def forward(self, x):
yL, yH = self.wt(x)
y_HL = yH[0][:, :, 0, ::]
y_LH = yH[0][:, :, 1, ::]
y_HH = yH[0][:, :, 2, ::]
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)
x = self.conv_bn_relu(x)
return x
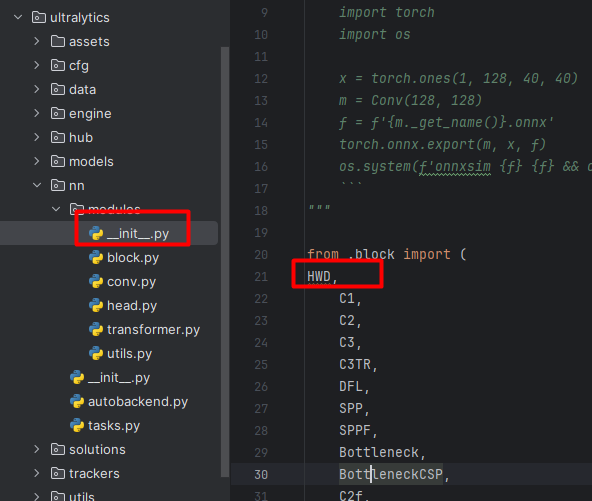
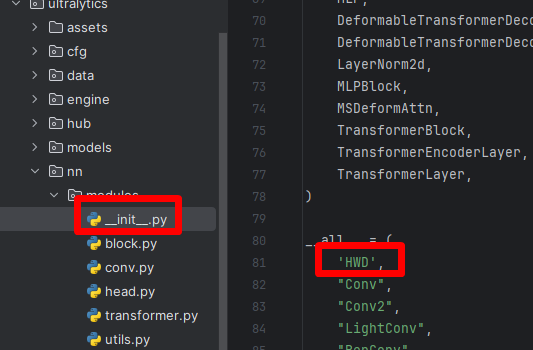
在__init__.py中导入HWD,如下图:
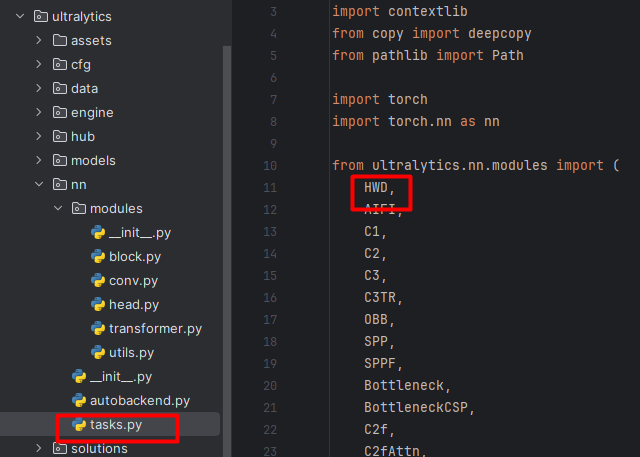
在task.py中导入HWD模块,如下图:
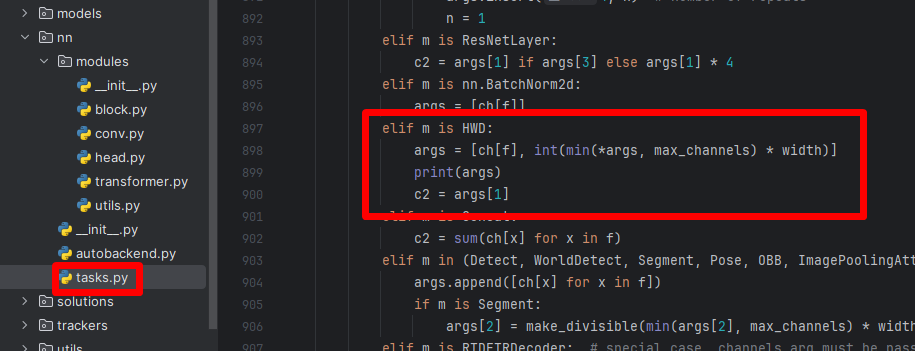
在task.py的parse_model函数中,加入HWD模块,如下图:
代码:
elif m is HWD:
args = [ch[f], int(min(*args, max_channels) * width)]
print(args)
c2 = args[1]
修改ultralytics/cfg/models/v8/yolov8-seg.yaml配置文件,代码如下:
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, HWD, [256]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, HWD, [512]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, HWD, [1024]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, HWD, [256]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, HWD, [512]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
在项目的根目录添加train.py脚本,代码如下:
from ultralytics import YOLO
import os
if __name__ == '__main__':
# 加载模型
model = YOLO(model="ultralytics/cfg/models/v8/yolov8m-seg.yaml") # 从头开始构建新模型
print(model)
# Use the model
results = model.train(data="seg.yaml", epochs=200, device='0', batch=8, seed=42) # 训练模
训练完成后,就可以看到测试结果!
在项目的根目录添加val.py脚本,代码如下:
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO('runs/segment/train7/weights/best.pt') # load a custom model
print(model)
# Validate the model
metrics = model.val(split='val') # no arguments needed, dataset and settings remembered
split='val’代表使用验证集做测试,如果改为split=‘test’,则使用测试集做测试!
在项目的根目录添加test.py脚本,代码如下:
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
# model = YOLO('yolov8m.pt') # load an official model
model = YOLO('runs/segment/train6/weights/best.pt') # load a custom model
results = model.predict(source="ultralytics/assets", device='0',show=True,save=True,save_txt=True,save_conf=True) # predict on an image
print(results)
test脚本测试assets文件夹下面的图片,save设置为true,则保存图片的测试结果!
测试结果
YOLOv8m-seg summary (fused): 257 layers, 25661442 parameters, 0 gradients, 106.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 164/164 [00:24<00:00, 6.58it/s]
all 2621 11379 0.328 0.225 0.2 0.106 0.273 0.233 0.183 0.0872
person 2621 8517 0.574 0.484 0.496 0.275 0.489 0.489 0.462 0.219
car 2621 1547 0.461 0.234 0.235 0.12 0.368 0.243 0.216 0.0957
cup 2621 728 0.25 0.0879 0.0644 0.0355 0.209 0.0934 0.065 0.0338
bicycle 2621 260 0.0682 0.0154 0.00983 0.00392 0.0816 0.0253 0.00588 0.00147
dog 2621 167 0.275 0.21 0.156 0.0836 0.211 0.228 0.149 0.075
cat 2621 160 0.342 0.319 0.239 0.116 0.28 0.319 0.201 0.0986
Speed: 0.1ms preprocess, 3.1ms inference, 0.0ms loss, 0.9ms postprocess per image
总结
将下采样改为HWD后,涨点明显。欢迎大家在自己的数据集上做尝试!