视图
视图的理解
视图只是对基表的映射,本身不存储数据。视图本质是存储下来的select语句,简化查询同时控制数据的访问。
视图类似于指针,通过视图修改数据就可以修改基表中的数据。
视图相关操作
创建
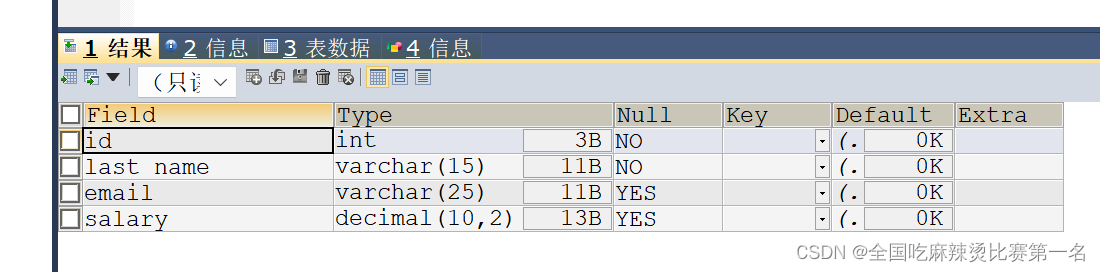
针对单表的创建示例:注意筛选后的子表,字段的命名
#如何创建视图
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;
SELECT * FROM vu_emp1;
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary#查询语句中字段的别名可以作为视图中字段出现的一种方式
FROM emps
WHERE salary>8000;
CREATE VIEW vu_emp3(emp_id,lname,monthly_sal)#字段列表个数要与select中个数一致
AS
SELECT employee_id,last_name,salary
FROM emps;
SELECT * FROM vu_emp1;
CREATE VIEW vu_emp_sal(dept_id,avg_sal)
AS
SELECT department_id,AVG(salary)
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_emp_sal;针对多表的创建:
create view vu_emp_dept
as
select e.employee_id,e.department_id,d.department_name
from emps e join depts d
on e.`department_id` = d.`department_id`;利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',department_name,')') emp_info
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept1;基于视图创建视图:
create view vu_emp4
as
select employee_id,last_name
from vu_emp1;查看
#查看视图
#查看数据库的表,视图对象
show tables;#查看的是表和视图
#查看视图的结构
describe vu_emp1;
#查看视图的属性信息
show table status like 'vu_emp1';
#查看视图的详细定义信息
show create view vu_emp1;DML操作
和对表操作类似
当view中的字段是由基表计算得出,在基表中并不存在,更新失败
#当view中的字段是由基表计算得出,在基表中并不存在,更新失败。
CREATE VIEW vu_emp_sal(dept_id,avg_sal)
AS
SELECT department_id,AVG(salary)
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_emp_sal;
UPDATE vu_emp_sal
SET avg_sal = 5000
WHERE department_id =30;修改视图
#方式1
create OR replace view vu_emp1
as
select employee_id,last_name,salary,email
from emps
where salary>7000
#方式2
alter view vu_emp1
as
select employee_id,last_name,hire_date
from emps;删除视图
SHOW TABLES;
DROP VIEW IF EXISTS vu_emp4;
DROP VIEW IF EXISTS vu_emp_dept,vu_emp_dept1;存储过程与函数
存储过程
存储过程会在预先编译好存储在服务器上,客户端只需要发送调用存储过程的命令,服务器就可以把存储好的一系列SQL语句执行。
分类示例:
不带参数存储过程
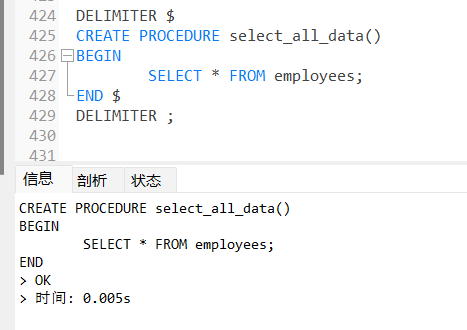
#不带参数创建存储过程
DELIMITER //
CREATE PROCEDURE select_all_data()
BEGIN
SELECT*FROM emps;
END//
DELIMITER ;
#调用
CALL avg_employee_salary();
只带OUT参数
#带OUT存储过程
desc emps;
delimiter //
create procedure show_min_salary(out min_sal double)
begin
select min(salary) into min_sal
from emps;
end//
delimiter;
#调用
CALL show_min_salary(@min_sal);
#查看变量值
SELECT @min_sal;只带IN参数
#带IN存储过程
delimiter //
create procedure show_someone_salary(in empname varchar(20))
begin
select salary
from emps
where last_name = empname;
end//
delimiter;
#调用方式1
call show_someone_salary('Abel');
#调用方式2
set @empname = 'Abel';
call show_someone_salary(@empname);同时带OUT和IN参数
#带IN和OUT的存储过程
delimiter //
create procedure show_someone_salary2(in empname varchar(20),out empsalary decimal(10,2))
begin
select salary into empsalary
from emps
where last_name=empname;
end//
delimiter;
#调用
set @empname='Abel';
call show_someone_salary2(@empname,@empsalary);
select @empsalary;带INOUT参数
#带INOUT
DELIMITER //
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(20))
BEGIN
SELECT last_name
FROM emps
WHERE employee_id = (
SELECT manager_id
FROM emps
WHERE last_name=empname
);
END//
DELIMITER;
#调用
SET @empname = 'Abel';
CALL show_mgr_name(@empname);
SELECT @empname;存储函数
无传入参数;
#空参函数
DELIMITER //
CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
DETERMINISTIC#出现报错要么加上特性
CONTAINS SQL
READS SQL DATA
BEGIN
RETURN(
SELECT email
FROM emps
WHERE last_name ='Abel'
);
END//
DELIMITER;
#调用
SELECT email_by_name();有传入参数;
#传入参数
#出现报错要么在创建函数前加上此语句
set global log_bin_trust_function_creators=1;
delimiter//
create function email_by_id(emp_id int)
returns varchar(25)
begin
return(
select email
from emps
where employee_id = emp_id
);
end//
delimiter ;
#调用
select email_by_id(100);
#调用方式2
set @emp_id =102;
select email_by_id(@emp_id);二者区别:
当返回值是多个时,可以当作传入参数处理,在存储过程中计算好后写入此OUT型参数,所以存储过程真正意义上没有返回值。存储函数则是实打实的返回值,但只能返回一个。
所以存储函数可以在查询语句中使用,但是存储过程不行。
查看,修改和删除
查看
#存储过程,函数的查看
#方式1 show create
SHOW CREATE PROCEDURE select_all_data;
SHOW CREATE FUNCTION count_by_id;
#方式2 show status
SHOW PROCEDURE STATUS;
SHOW PROCEDURE STATUS LIKE 'show_max_salary';#查看指定的
SHOW FUNCTION STATUS LIKE 'count_by_id';
#方式3通过information_schema查看
SELECT* FROM information_schema.`ROUTINES`
WHERE routine_name = 'email_by_id' AND ROUTINE_TYPE = 'FUNCTION';
SELECT* FROM information_schema.`ROUTINES`
WHERE routine_name = 'show_mgr_name' AND ROUTINE_TYPE = 'PROCEDURE';修改
修改不修改存储过程或函数功能,只修改特性
相关特性:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
- CONTAINS SQL ,表示子程序包含SQL语句,但不包含读或写数据的语句。
- NO SQL ,表示子程序中不包含SQL语句。
- READS SQL DATA ,表示子程序中包含读数据的语句。
- MODIFIES SQL DATA ,表示子程序中包含写数据的语句。
- SQL SECURITY { DEFINER | INVOKER } ,指明谁有权限来执行。
- DEFINER ,表示只有定义者自己才能够执行。
- INVOKER ,表示调用者可以执行。
- COMMENT 'string' ,表示注释信息。
alter procedure show_max_salary
sql security invoker
comment '查询最高工资';
删除
drop function if exists email_by_id;
drop procedure if exists show_max_salary;优缺点
优点:
- 封装成模块,代码更加清晰,复用性高
- 只需一次编译多次使用,提高SQL效率
- 存储过程的安全性强。因为可以设置用户访问权限
缺点:
- 难以调试,扩展和移植性
- ·不适用高并发场景
变量,流程控制与游标
变量:
1)系统变量:
global全局变量和session会话系统变量
系统变量以@@为开头
#查看系统变量
SHOW GLOBAL VARIABLES;
SHOW SESSION VARIABLES;
SHOW VARIABLES;#默认查询会话系统变量
#查询部分系统变量
SHOW GLOBAL VARIABLES LIKE 'admin_%';
SHOW VARIABLES LIKE 'character_%';
#查看指定系统变量
SELECT @@global.max_connections;#限制服务器连接的最大连接数,仅是全局变量
SELECT @@session.character_set_client;#用于设置客户端字符集,既是全局又是会话变量
SELECT @@session.pseudo_thread_id;#用于标记当前会话的MySQL连接id
SELECT @@character_set_client;#先查询会话系统变量,后查询系统变量
#修改系统变量默认值
#方式1:修改配置文件,重启MySQL服务
#方式2:用set命令重新设置
SET @@global.max_connections=161;
SET GLOBAL max_connections=171;
#针对当前数据库实例是有效的,一旦重启MySQL服务就失效了
#会话系统变量
SET @@session.character_set_client = 'utf8';
SET SESSION character_set_client = 'utf8';
#针对当前会话是有效的,一旦新建连接在新会话中就失效了。
2)用户变量
用户变量以@开头,分为会话用户变量和局部变量
会话用户变量:只对当前连接会话有效
局部变量:只在BEGIN和END语句中有效,局部变量只能在存储过程与函数中使用。
会话用户变量的创建
#变量的声明和赋值
#方式1:
SET @m1=1;
SET@m2 := 2;
SET @sum := @m1+@m2;
SELECT @sum;
#方式2
SELECT @count := COUNT(*) FROM employees;
SELECT @count;
SELECT AVG(salary) INTO @avg_sal FROM employees;
SELECT @avg_sal;局部变量的创建:
只能放在BEGIN 和END中,而且必须放在首行,使用DECLARE声明。
delimiter //
create procedure test_var()
begin
#声明
declare a int default 0;
declare b int;#没有赋值默认为null
declare c,d decimal DEFAULT 1.0;#合并
declare emp_name varchar(25);
#赋值
set a=1;
set b := 2;
select last_name into emp_name from employees where employee_id =101;
#使用
select a,b,emp_name;
end//
delimiter;
#调用存储过程
call test_var();
定义条件与处理程序
定义条件就是给错误码命名
实例代码:
#举例1:定义“Field_Not_Be_NULL”错误名与MySQL中违反非空约束的错误类型是“ERROR 1048 (23000)”对应。
#方式1:使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1048;
#方式2:使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE '23000';
#举例2:定义"ERROR 1148(42000)"错误,名称为command_not_allowed。
DECLARE command_not_allowed CONDITION FOR 1148;
DECLARE command_not_allowed CONDITION FOR SQLSTATE '42000';处理程序:
#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';关于处理程序的示例
DELIMITER //
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
#声明处理程序
#处理方式1:
declare continue handler for 1048 set @prc_value = -1;
#处理方式2:
#declare continue handler for sqlstate '23000' set @prc_value = -1;
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';#在这做了一个捕获,继续向下执行
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END //
DELIMITER ;流程控制
分支语句之IF
#分支结构之IF
DELIMITER//
CREATE PROCEDURE test_if()
BEGIN
DECLARE stu_name VARCHAR(15);
IF stu_name IS NULL
THEN SELECT 'stu_name is null';
END IF;
END//
DELIMITER;
CALL test_if();