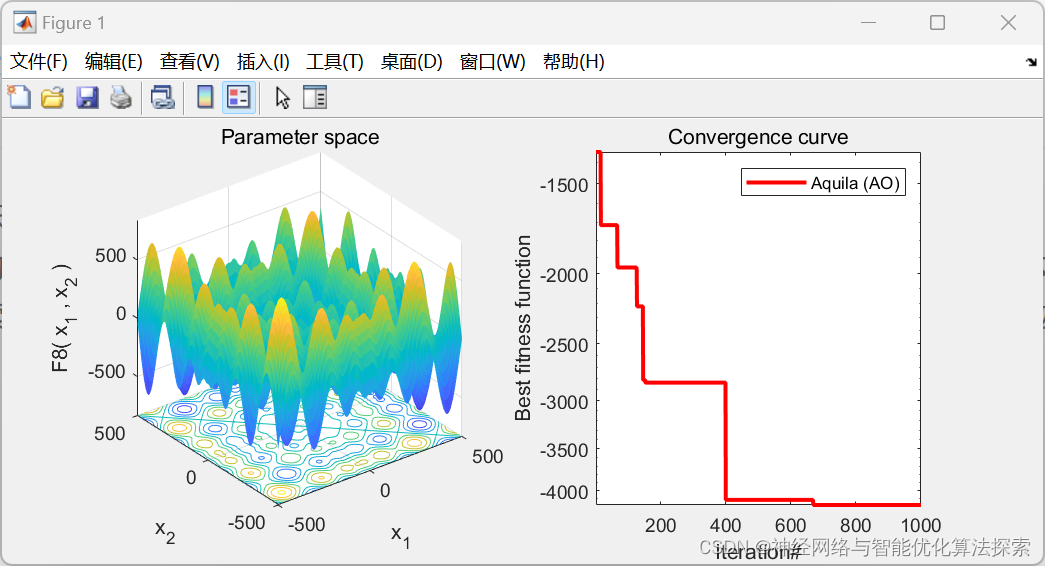
假设有:
待优化的目标函数为 f ( w ) f(w) f(w),使用优化算法来最小化目标函数 f ( w ) : a r g m i n w f ( w ) f(w):argmin_wf(w) f(w):argminwf(w)
在时间步t的梯度 g t = ∇ f ( w t ) g_t= \nabla f(w_t) gt=∇f(wt)
模型参数为 w w w, w t w_t wt为时刻t的参数, w t + 1 w_{t+1} wt+1是时刻t+1的参数
在时刻t的学习率为 α t \alpha_t αt
平滑项 ϵ \epsilon ϵ
SGD
SGD(Stochastic gradient descent)只考虑当前时间步的梯度,其更新方式为
w t + 1 = w t − α t g t w_{t+1} = w_t - \alpha_t g_t wt+1=wt−αtgt
pytorch 对应的类为torch.optim.SGD
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
SGD with momentum
对于非凸目标函数,可能会存在多个局部极小值,使用SGD求解时,在这些局部极小值附近的梯度很小,使得优化算法陷入到局部最优解。
而带动量的SGD算法不仅仅使用当前梯度,也会考虑到历史梯度,设动量参数为 μ \mu μ,其参数更新方式为:
b t = μ b t − 1 + g t w t + 1 = w t − α t b t b_t = \mu b_{t-1} + g_t \\ w_{t+1} = w_t - \alpha_t b_t bt=μbt−1+gtwt+1=wt−αtbt
pytorch 对应的类也为torch.optim.SGD,可以设置momentum参数。
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
SGD with Nesterov Acceleration
SGD with Nesterov Acceleration是对SGD with momentum的改进,先根据累积梯度进行一次参数更新。
g t = ∇ f ( w t − μ b t − 1 ) b t = μ b t − 1 + g t w t + 1 = w t − α t b t g_t = \nabla f(w_{t} - \mu b_{t-1}) \\ b_t = \mu b_{t-1} + g_t \\ w_{t+1} = w_t - \alpha_t b_t gt=∇f(wt−μbt−1)bt=μbt−1+gtwt+1=wt−αtbt
pytorch 对应的类也为torch.optim.SGD,在设置momentum参数后,设置nesterov参数为True。
AdaGrad
AdaGrad(Adaptive Gradient Algorithm)是在每次迭代时自适应地调整每个参数的学习率,出自2021年的论文《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》。
若有d个参数
v t = d i a g ( ∑ i = 1 t g i , 1 2 , ∑ i = 1 t g i , 2 2 , ⋯ , ∑ i = 1 t g i , d 2 ) w t + 1 = w t − α t g t v t + ϵ v_t = diag(\sum^t_{i=1}g^2_{i,1}, \sum^t_{i=1}g^2_{i,2}, \cdots,\sum^t_{i=1}g^2_{i,d} ) \\ w_{t+1} = w_t - \alpha_t \frac{g_t}{\sqrt{v_t} + \epsilon} vt=diag(i=1∑tgi,12,i=1∑tgi,22,⋯,i=1∑tgi,d2)wt+1=wt−αtvt+ϵgt
相比于SGD,每个参数的学习率是会随时间变化的,即对于第j个参数,学习率为 α t v t , j + ϵ = α t s u m i = t t g i , j 2 + ϵ \frac{\alpha_t}{\sqrt{v_{t,j}} + \epsilon} = \frac{\alpha_t}{\sqrt{sum^t_{i=t}g_{i,j}^2} + \epsilon} vt,j+ϵαt=sumi=ttgi,j2+ϵαt。并且AdaGrad使用了二阶动量。
pytorch 对应的类为torch.optim.Adagrad
RMSprop
AdaGrad考虑过去所有时间的梯度累加和,所以学习率可能会趋近于零,从而使模型在没有找到最优解时就终止了学习。 RMSprop对AdaGrad进行了改进,该算法出自 G. Hinton的 lecture notes 。RMSprop相比于AdaGrad只关注过去一段时间窗口的梯度平方和:
v t = β 2 v t − 1 + ( 1 − β 2 ) d i a g ( g t 2 ) w t + 1 = w t − α t g t v t + ϵ v_t = \beta_2 v_{t-1} + (1- \beta_2) diag(g^2_t) \\ w_{t+1} = w_t - \alpha_t \frac{g_t}{\sqrt{v_t} + \epsilon} vt=β2vt−1+(1−β2)diag(gt2)wt+1=wt−αtvt+ϵgt
pytorch对应的类为torch.optim.RMSprop
AdaDelta
AdaGrad考虑过去所有时间的梯度累加和,所以学习率可能会趋近于零,从而使模型在没有找到最优解时就终止了学习。 AdaDelta对AdaGrad进行了改进,该算法出自论文《ADADELTA: An Adaptive Learning Rate Method》。AdaDelta相比于AdaGrad有两个改进:
- 只关注过去一段时间窗口的梯度平方和: v t = β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ d i a g ( g t 2 ) v_t = \beta_2 \cdot v_{t-1} + (1- \beta_2) \cdot diag(g^2_t) vt=β2⋅vt−1+(1−β2)⋅diag(gt2)(指数移动平均) ,一般取 β 2 = 0.9 \beta_2 = 0.9 β2=0.9(相当于关注过去10个时间步的梯度平方和)
- 引入每次参数更新差值 Δ θ \Delta \theta Δθ的平方的指数移动平均: Δ X t − 1 2 = β 1 Δ X t − 2 2 + ( 1 − β 1 ) Δ θ t − 1 ⊙ Δ θ t − 1 \Delta X^2_{t-1} = \beta_1 \Delta X^2_{t-2} + (1-\beta_1) \Delta \theta_{t-1} \odot \Delta \theta_{t-1} ΔXt−12=β1ΔXt−22+(1−β1)Δθt−1⊙Δθt−1
v t = β 2 v t − 1 + ( 1 − β 2 ) d i a g ( g t 2 ) Δ X t − 1 2 = β 1 Δ X t − 2 2 + ( 1 − β 1 ) Δ θ t − 1 ⊙ Δ θ t − 1 w t + 1 = w t − α t Δ X t − 1 2 + ϵ v t + ϵ g t v_t = \beta_2 v_{t-1} + (1- \beta_2) diag(g^2_t) \\ \Delta X^2_{t-1} = \beta_1 \Delta X^2_{t-2} + (1-\beta_1) \Delta \theta_{t-1} \odot \Delta \theta_{t-1} \\ w_{t+1} = w_t - \alpha_t \frac{\sqrt{\Delta X^2_{t-1} + \epsilon}}{\sqrt{v_t} + \epsilon}g_t vt=β2vt−1+(1−β2)diag(gt2)ΔXt−12=β1ΔXt−22+(1−β1)Δθt−1⊙Δθt−1wt+1=wt−αtvt+ϵΔXt−12+ϵgt
pytorch对应的类为torch.optim.AdaDelta
Adam
Adam出自论文《Adam: A Method for Stochastic Optimization》,它同时考虑了一阶动量和二阶动量。(公式中的纠正项 m ^ t \hat m_t m^t 和 v ^ t \hat v_t v^t只在初始阶段校正)
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) d i a g ( g t 2 ) m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t w t + 1 = w t − α t m ^ t v ^ t + ϵ m_t = \beta_1m_{t-1} + (1-\beta_1)g_t \\ v_t = \beta_2 v_{t-1} + (1- \beta_2) diag(g^2_t) \\ \hat m_t = \frac{m_t}{1-\beta_1^t} \\ \hat v_t = \frac{v_t}{1-\beta_2^t} \\ w_{t+1} = w_t - \alpha_t \frac{\hat m_t}{\sqrt{\hat v_t} + \epsilon} mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)diag(gt2)m^t=1−β1tmtv^t=1−β2tvtwt+1=wt−αtv^t+ϵm^t
pytorch对应的类为torch.optim.Adam
AdamW
AdamW是对Adam的改进,出自论文《Decoupled Weight Decay Regularization》,现在大模型训练基本上都是使用AdamW优化器。
AdamW改进的主要出发点是 L 2 L_2 L2正则和权重衰减(weight decay)对于自适应梯度如Adam是不一样的,所以作者们对Adam做了如下图的修改。

pytorch对应的类为torch.optim.AdamW
参考资料
- pytorch优化算法
- 知乎文章:从 SGD 到 AdamW —— 优化算法的演化
- https://www.fast.ai/posts/2018-07-02-adam-weight-decay.html
- Cornell University Computational Optimization Open Textbook
- 神经网络与深度学习
- 视频:从SGD到AdamW(后面的两个视频还讲了为什么transformer用SGD的效果不好)