目录
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第二章——CUDA编程入门,一起来学习 CUDA 中的线程与线程束
Note:线程束杜老师之前也讲过,感兴趣的可以看看 CUDA编程之基础,内存模型和线程束,另外也有一篇关于 CUDA 编程的教程 CUDA编程入门极简教程,非常建议大家看看
课程大纲可以看下面的思维导图

0. 简述
本小节目标:
1. 理解在 CUDA 中一维二维三维的 grid,block 的写法,以及遍历 thread 的方法2. 理解 .cu 和 .cpp 中相互引用时的注意事项,理解 Makefile 的写法
今天我们来讲解第二章节 CUDA 编程入门,从这一章节开始,我们会结合代码以及 PPT 里面的各种知识点,一起来把整个知识框架给搭建起来,第二章节内容主要分为以下五个部分:
- CUDA 中的线程与线程束
- 使用 CUDA 进行 matmul 计算
- 共享内存以及 bank conflict
- 使用 CUDA 进行预处理/后处理
- stream 和 event
首先第一个要讲的是 CUDA 中的线程和线程束,它们是 CUDA 中的一个很基本的概念,我们会教大家如何去理解 thread 和 block 这个概念,同时 CUDA 的 thread id 它这个索引是如何计算的
第二个是如何使用 CUDA 进行矩阵乘法的一个计算,这部分我们会根据 CPU 和 GPU 两个实现来进行一个速度比较,同时也会在 GPU 中使用各种不同策略的核函数来进行一个矩阵乘法的计算比较,来告诉大家如何去选择一个比较好的方式去加速
第三个也是比较重要的概念,共享内存以及 bank conflict,共享内存是大家在写核函数的时候经常会遇到的一个问题,就是如何去高效利用你的共享内存,以及 bank conflict 它什么时候会发生,它为什么会发生,以及发生之后我们如何去解决它
第四个部分是偏实际操作的一些东西,比如我们在利用 TensorRT 进行一个模型部署的时候,其实我们需要考虑如何利用 CUDA 来对 TensorRT 的一些预处理和后处理来进行一个加速,比如 resize、crop 等等这些东西它其实都是可以用 CUDA 来进行加速的,甚至像 3D 点云这些东西其实也是可以考虑 CUDA 来进行加速的,
第五个部分 stream 和 event,这个也是 CUDA 中的一个基本概念,我们会教大家如何利用 CUDA 写一个多流的程序来提高你的并发性
OK,我们来看第一章第一小节,CUDA 中的线程和线程束,这一章结束后希望大家能够理解 CUDA 中的一维、二维、三维的 Grid 和 Block 它的写法是什么样子的,以及如何去计算你的 thread id 的索引
1. 执行一下我们的第一个CUDA程序
我们来看第一个案例 2.1-dim_and_index,包含的文件内容如下:

Makefile、compile_commands.json 以及 Makefile.config 是用于编译过程中环境变量和一些参数的设置,src 文件夹下是我们的源文件,它包含一个 print_index.cu 的 CUDA 文件
这个案例是一个非常简单的打印索引的 CUDA 程序,具体实现我们先不看,先执行 make 编译一下,输出如下所示:

Note:我们也可以用 nvcc 相关指令进行编译,指令如下所示:
nvcc print_index.cu -o print_index.cu.o
nvcc 是 cuda 的编译器,定义和 gcc、g++ 是一样的
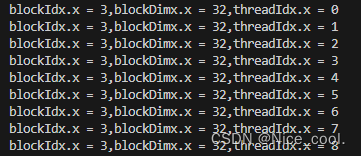
编译完成之后多了一个 trt-cuda 可执行文件,执行后输出如下:

程序会将各个维度上的 block idx 和 thread idx 给打印出来,我们来稍微简单看一下里面的部分代码,如下所示:
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
void print_two_dim(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
/* 这里建议大家吧每一函数都试一遍*/
// print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
主要有以下几个点和以往的 C/C++ 程序不同:
- 文件的后缀名是
.cu <<<>>>符号的出现__global__
2. CUDA中的grid和block
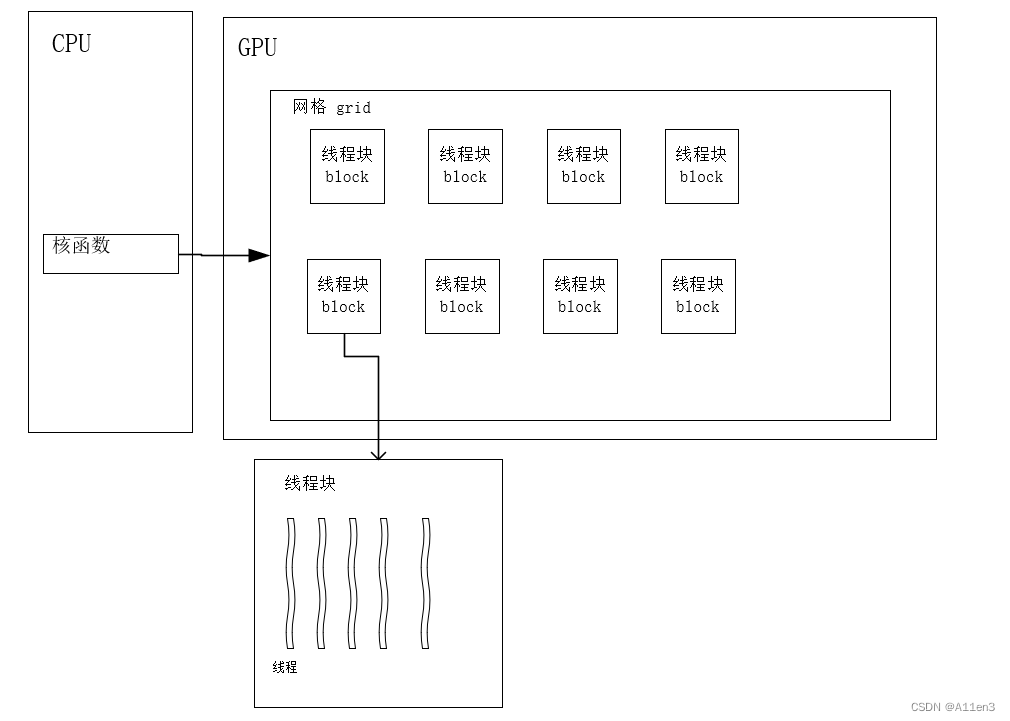
上面的程序里面其实有很多我们不清楚的概念,现在我们先简单介绍下 CUDA 编程中的一些基本概念,首先我们来看 CUDA 编程中的 grid 和 block,它们是大家在写 CUDA 程序时第一个要接触的概念,我们看下面这张图:

首先我们计算机里面有一个 host 和 device,我们可以认为 host 就是你的 CPU,device 就是你的 GPU,其实我们一般在写一个程序的时候肯定是从 CPU 开始执行的,然后执行到一定程度之后开始调用你的 device 做一些计算,这个时候我们的入口就是这个 kernel,kernel 它是一个函数,是一个以线程为单位来进行计算的一个函数,我们管它叫核函数
我们之前讲过 CUDA 编程它其实里面有大量的 thread,成千上万个 thread 来进行一些处理,这所有的 thread 它其实都是在执行同一个核函数,同一个 kernel。一般来说一个 kernel 它会分配一个 Grid,一个 Grid 里面有很多个 block,而一个 block 里面又有很多个 threa,它是一个层级的架构。
所以大家可以这么认为,grid 和 block 它其实都是属于大量 thread 的一个组合,它之所以这样去划分,比如把 Grid 分为好几个多维的 block,block 分为好几个多维的 thread,它其实就是为了能够帮助你进行一个快速的索引。另外值得注意的是 grid 和 block 它其实是属于逻辑意义上的东西,它并不是说在 GPU 硬件上实际存在的东西,比如说我们 GPU 里面有 SM,我们的 SM 它其实里面是没有 grid 和 block 这些东西的,它就是在编程里面方便使用的一个逻辑上的概念
grid 和 block 它是什么样的关系呢?block 里面有很多的 thread,每一个 thread 它都会有一个自己的 register 和一个自己的 local memory。同时我们可以看到每一个 block 里面的 thread 它们其实都是在共享一个 shared memory。我们一个 grid 里面的很多个 block 它其实都是在访问同一 global memory,constant memory 和 texture memory
这里面其实可以看到它又分了好几个 memory,这个在之前的课程中也讲过,它其实是分层级的一个 memory,就是离你的计算单元越近的 memory 越快,所以我们知道你的 register 是最快的,其次是你的 shared memory,再往下走就是 global memory 这些东西,所以说我们再写 CUDA 程序的时候就要想如何去高速的利用 shared memory,这个我们在之后的小节中会详细讲,这里先跳过
那我们接着看,一般来说:
- 一个 kernel 对应一个 grid
- 一个 grid 可以有多个 block,一维~三维
- 一个 block 可以有多个 thread,一维~三维
我们需要注意一下,其实当我们定义 grid 和 block 的时候,我们可以给分配一维二维或者三维的,上图给展示的是一个二维的
3. block和thread的遍历(traverse)
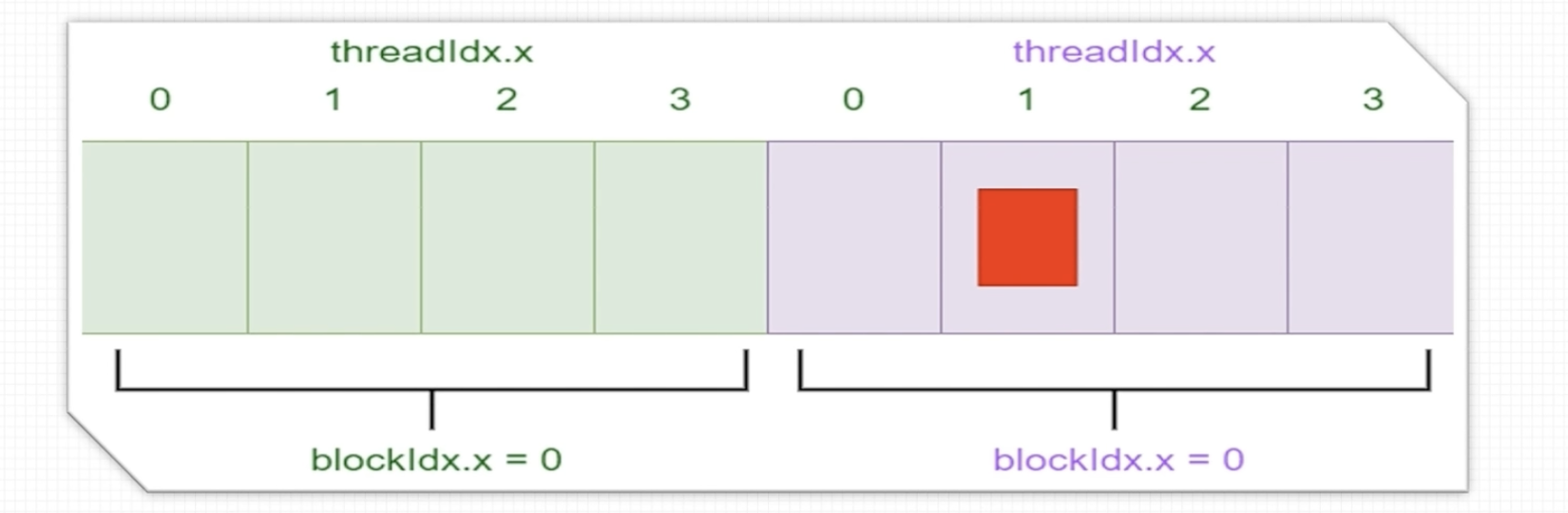
我们先从一维去考虑

比如说我们现在有一个数组,它有 8 个数据,现在我们想给它切分成两个 block 来进行访问,一个 block 我们有 4 个线程分别去访问不同的地址,如上图所示
那我们可以这么写:
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim;
dim3 block(blockDim);
dim3 grid(gridDim);
}
首先 input_size 等于 8,block_dim 等于 4,说明一个 block 是 4 个线程;之后 grid 是你的 input_size 除以 block_dim 等于 2,所以我们 dim3 block 它传入的参数就是 4,dim3 grid 传入的参数就是 2
我们看一下 dim3 是什么:
struct __device_builtin__ dim3
{
unsigned int x, y, z;
#if defined(__cplusplus)
#if __cplusplus >= 201103L
__host__ __device__ constexpr dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ constexpr dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ constexpr operator uint3(void) const { return uint3{x, y, z}; }
#else
__host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ operator uint3(void) const { uint3 t; t.x = x; t.y = y; t.z = z; return t; }
#endif
#endif /* __cplusplus */
};
typedef __device_builtin__ struct dim3 dim3;
dim3 它其实是 CUDA 内部的一个 struct,它里面有一个 int 类型的一个 x、y、z,所以就代表我们可以给设定为一维、二维、三维,根据你传入参数的不同,它会初始化成不同维度的一个 dim,这个是完全 OK 的
如果说一维是可以的,那么我们来看二维怎么定义:
void print_two_dim(){
int inputWidth = 8;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
/* 这里建议大家吧每一函数都试一遍*/
// print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
比如我们现在有一个 8x8 的二维数组,共 64 个数据,然后现在我们设定它的一个 blockDim 的宽度是 2,那就是一个 block 里面有 2x2 个线程(因为 block 设定为二维的),然后一个 grid 里面有 4x4 个 block
我们回到 print_one_dim 函数里面,我们看它的 thread id 是怎么打印出来的
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
因为你的 grid 和 block 它可以是三维,也可以是二维,也可以一维,所以你的 block id 和你的 thread id 它对应的其实是有各个维度的,当我们在进行索引的时候,它是先从你的 z 去索引,再去访问你的 y,最后再去访问你的 x。
运行打印输出如下:

每一个不同的维度它都有个自己的索引,因为数据一共是 8 个,所以它一共有 8 个不同的输出,在这里大家需要注意一下,之前我们说每一个 thread 它都会执行一个 kernel,所以你的 thread 它有自己的 id,所以它执行的结果它完全是不一样的。之后每一个 block 它都有一个自己的 thread,thread id 它是从 0~3 的一个个变化,你的 block id 它也是从 0~1 这样的变化
核函数需要注意一下,前面一定要写一个 __global__ 来表示它是一个核函数,这个大家写的时候需要注意
我们再看另外一个核函数 print_dim_kernel:
__global__ void print_dim_kernel(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
它是把你 grid 和 block 各个维度上的一个 dim 的大小给打印出来,我们执行一下输出如下:

因为你的 grid dim 和 block dim 的大小其实并不会根据你的 thread id 的变化而变化,所以它的结果都是一样的,grid 先是 z 再是 y 再是 x,维度是 1x1x2。block 也是先 z 和 y 方向,之后 x 方向是 4,维度是 1x1x4
我们现在这个索引,它其实是各个维度上的一个索引,这样只是看起来比较好看,但是如果我们希望这个索引它是按照一个一维的方式展现出来,我们应该怎么做呢?
我们看另一个核函数,print_thread_idx_per_block_kernel:
__global__ void print_thread_idx_per_block_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
这里索引计算这里需要大家记住一个诀窍,就是 thread 它有 x、y、z 维度,那我们先去访问你 z 维度上的 threadIdx 之后乘上你的 blockDim 的 x 和 y,然后再是你的 threadIdx.y 乘上 blockDim.x 那一行的数据,之后再是你 threadIdx.x 的一列
这么看可能看起来有点麻烦,我们结合图去理解一下:

我们假设 block 是三维的,先遍历 z 方向,每一个 z 方向它都有 blockDim.x * blockDim.y 这些量级的 thread,找到了 z 方向是第几个之后我们再看 y 方向,y 方向就是具体看它在哪一行,所以 threadIdx.y * blockDim.x,找到在哪一行之后,我们再去找它是哪一列也就是 threadIdx.x,最终我们就能找到图中红色点线程的一个索引了
我们执行一下输出如下:

可以看到我们现在已经能够以一维的方式去打印了
我们看另一个核函数,print_thread_idx_per_grid_kernel:
__global__ void print_thread_idx_per_grid_kernel(){
int bSize = blockDim.z * blockDim.y * blockDim.x;
int bIndex = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int tIndex = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int index = bIndex * bSize + tIndex;
printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n",
bIndex, tIndex, index);
}
我们如果说不是想要在一个 block 里面去寻找你的 thread id,而是在一个 grid 的空间下去寻找你的 thread,怎么办呢?这个我们也是结合着图去看一下可能会比较好理解:

grid 它可以是多维的 block,我们把图中每一个小方块给理解为一个 block,我们现在需要从这么大的空间里面去找这个红色的点,我们怎么做呢?我们肯定是先需要去找它的这个 block 到底是在哪一个,我们需要找 block id,它跟 thread id 的索引是一样的,先从 z 寻找之后,再去寻找你的 y 之后再去寻找你的 x,找到了你的 block id 之后,你再去寻找你的 thread id,也先是 z 再去 y 最后 x
找到之后怎么做呢?你的 index 它等于 bIndex * bSize + tIndex,而 bSize 也就是每个 block 的大小,它就等于 blockDim.z * blockDim.y * blockDim.x,,这样子就能够把你的 thread id 在 Grid 的空间下的索引给找出来
我们执行一下输出如下:

那这个小节的案例我们基本上看完了,这里注意一下有一个 cudaDeviceSynchronize,synchronize 是同步的意思,在 CUDA 编程中有几种同步的方式:
- cudaDeviceSynchronize:CPU 与 GPU 端完成同步,CPU 不执行之后的语句,直到这个语句以前的所有 cuda 操作结束
- cudaStreamSynchronize:跟 cudaDeviceSynchronize 很像,但是这个是针对某一个 stream 的。只同步指定的 stream 中的 cpu/gpu 操作,其他的不管
- cudaThreadSynchronize:现在已经不被推荐使用的方法
- __syncthreads:线程块内同步
如果我们把 cudaDeviceSynchronize 注释掉再去执行会发现终端上没有任何打印,这是因为我们核函数的执行它其实是异步的,我们 CPU 不会去等待它执行完成,所以我们如果要得到对应的结果需要做同步处理,确保 CPU 在执行下面的指令时当前核函数已经执行完成
我们最后看一个核函数,print_cord_kernel:
__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
我们之前在一个 grid 中找 thread id 时写得比较冗长,我们既需要计算 block 索引又需要计算 thread 索引,之后还需要拼在一起,最后才能得到整体上的一个全局索引,这个还是比较麻烦的,我们一般很少会这么用
我们一般怎么做呢?一般按照上面的方法计算 blockIdx.x * blockDim.x + threadIdx.x,同理 y 方向也是,这样就能找到对应点的 (x,y) 的坐标
我们执行一下输出如下:

这样它就能把你 4x4 大小的一个图像中的每一个索引打印出来,一般来说这个是我们比较常用的方式
第一个案例中还有一些关于二维的其它例子,大家可以自己尝试下
4. nvcc编译器
上面我们对第一个 CUDA 案例的内容进行了简单分析,下面我们来看下这个 CUDA 程序是怎么完成编译执行的呢?其中的 Makefile 文件里面又包含了哪些内容?下面我们一起来看下
我们都知道 C++ 程序的编译器是 g++,那么 CUDA 程序的编译器是什么呢?是 nvcc,它是 g++ 的一个扩展版,但是如果你用默认的 g++ 去编译 CUDA 程序时是会出错的,这是因为 CUDA 程序里面有很多标识符比如 __global__、dim3 等等 g++ 是无法识别的,因此编译 CUDA 程序我们需要用它对应的编译器 nvcc
下面我们对比了 g++ --help 和 nvcc --help,来看下两个编译器有什么不同:

g++ 和 nvcc 是两种不同的编译器,分别用于编译 C++ 程序和 CUDA C/C++ 程序。虽然两者都支持命令行选项来控制编译过程,它们的功能和用途有着显著的差异。以下是对它们输出内容的一般性对比,以及各自的特点介绍。(from ChatGPT)
g++ (–help 输出内容):
g++是 GNU Compiler Collection (GCC) 的一部分,专门用于编译 C++ 程序。当你使用 g++ --help 命令时,它会输出一系列的选项和用法说明,这些内容主要涵盖:
- 编译选项:控制编译阶段的行为,如优化级别(
-O1,-O2,-O3,-Os等)、调试信息生成(-g)等。 - 链接选项:指定链接行为,如静态链接(
-static)、链接库搜索路径(-L)和链接特定库(-l)。 - 预处理选项:控制预处理器行为的选项,如定义宏(
-D)、包含路径(-I)等。 - 警告控制:开启或禁用特定类型的警告(如
-Wall,-Wextra,-Werror等)。 - 语言选项:指定使用的 C++ 标准版本(如
-std=c++11,-std=c++14,-std=c++17等)。 - 其他杂项:包括文件输出控制、调试和优化辅助工具等。
nvcc (–help 输出内容):
nvcc 是 NVIDIA CUDA Compiler,用于编译 CUDA C/C++ 程序。nvcc 的命令行界面设计用于接受类似于传统 UNIX 编译器的选项,同时提供了许多专门针对 CUDA 编程的选项。使用 nvcc --help 时,你会看到:
- CUDA 相关编译选项:用于控制 GPU 代码生成的选项,如指定 GPU 架构(
-arch)、代码生成目标(-code)等。 - 包装选项:
nvcc实际上是一个包装器编译器,它可以调用gcc/g++来处理 C/C++ 源文件。因此,它允许指定传递给这些编译器的选项(如-Xcompiler)。 - 优化和调试:提供了用于优化 CUDA 代码和生成调试信息的选项(如
-O2,-G,-lineinfo等)。 - 库和链接选项:与
g++类似,nvcc也支持指定链接选项,如链接 CUDA 运行时库等。 - 预处理和宏定义:支持预处理器选项,允许定义宏、包含路径等。
- 警告和错误处理:控制编译时警告和错误显示的选项。
异同点总结:
- 相同点:两者都支持预处理、编译、链接等编译阶段的控制,包括优化级别、调试信息生成、警告控制等。
- 不同点:
nvcc专注于 CUDA C/C++ 程序的编译,提供了许多专门的 CUDA 相关选项,如 GPU 架构选择、CUDA 代码生成等。而g++主要用于普通 C++ 程序的编译,支持各种 C++ 标准。 - 包装器角色:
nvcc具有包装器的角色,能够调用g++或gcc来编译 C/C++ 代码部分,并将这部分与 CUDA 代码整合在一起。
nvcc 编译时常见的编译选项有:(from ChatGPT)
指定GPU架构和代码生成:
-arch=sm_xx:指定目标设备的计算能力。xx是一个数字,比如50表示计算能力 5.0。这个选项让nvcc知道生成的代码应该针对哪种类型的 GPU。-code=sm_xx,compute_xx:指定具体的 GPU 代码(sm_xx)和虚拟架构代码(compute_xx)。这允许在不同的 GPU 上有更好的兼容性和性能。
优化和调试:
-O0,-O1,-O2,-O3:设置优化级别。-O0表示无优化(方便调试),-O3表示最高优化级别。-G:启用调试模式,生成调试信息。-lineinfo:生成行信息,有助于性能调优和调试,而不需要像-G那样降低优化级别。
预处理器选项:
-Dname:定义宏name。-I:添加头文件搜索路径。
包装器选项:
-Xcompiler:后面紧跟要传递给底层 C/C++ 编译器的选项,如-Xcompiler -fPIC。
其他常用选项:
-c:编译源文件但不链接。生成目标文件(.o文件)。-o:指定输出文件的名称。-v:在编译时显示详细信息,帮助诊断问题。--use_fast_math:使用快速数学库。这可以提高性能,但可能牺牲一些精度。--ptxas-options=-v:显示 PTX/SASS 汇编优化信息,有助于深入了解代码是如何被优化的。
这些选项可以组合使用,以满足特定的编译需求和性能优化目标。
5. Makefile部分
OK,我们下面来看第一个案例的 Makefile 文件,来看它是如何通过 nvcc 编译我们的 CUDA 程序的,Makefile 完整内容如下:
CONFIG := ../../config/Makefile.config
CONFIG_LOCAL := ./config/Makefile.config
include $(CONFIG)
include $(CONFIG_LOCAL)
BUILD_PATH := build
SRC_PATH := src
CUDA_DIR := /usr/local/cuda-$(CUDA_VER)
KERNELS_SRC := $(wildcard $(SRC_PATH)/*.cu)
APP_OBJS += $(patsubst $(SRC_PATH)%, $(BUILD_PATH)%, $(KERNELS_SRC:.cu=.cu.o))
APP_DEPS += $(KERNELS_SRC)
CUCC := $(CUDA_DIR)/bin/nvcc
CUDAFLAGS := -Xcompiler -fPIC
INCS := -I $(CUDA_DIR)/include \
-I $(SRC_PATH)
LIBS := -L "$(CUDA_DIR)/lib64" \
ifeq ($(DEBUG),1)
CUDAFLAGS += -g -G -O0
else
CUDAFLAGS += -O3
endif
ifeq ($(SHOW_WARNING),1)
CUDAFLAGS += -Wall -Wunused-function -Wunused-variable -Wfatal-errors
else
CUDAFLAGS += -w
endif
all:
$(MAKE) $(APP)
update: $(APP)
@echo finished updating $<
$(APP): $(APP_DEPS) $(APP_OBJS)
@$(CUCC) $(APP_OBJS) -o $@ $(LIBS) $(INCS)
@echo finished building $@. Have fun!!
show:
@echo $(BUILD_PATH)
@echo $(APP_DEPS)
@echo $(INCS)
@echo $(APP_OBJS)
clean:
rm -rf $(APP)
rm -rf build
# Compile CUDA
$(BUILD_PATH)/%.cu.o: $(SRC_PATH)/%.cu
@echo Compile CUDA $@
@mkdir -p $(BUILD_PATH)
@$(CUCC) -o $@ -c $< $(CUDAFLAGS) $(INCS)
.PHONY: all update show clean
这个 Makefile 文件是用来编译 CUDA 程序的构建脚本,涉及多个关键部分,下面逐一解析它们的作用和含义:(from ChatGPT)
配置文件引入:
CONFIG := ../../config/Makefile.config
CONFIG_LOCAL := ./config/Makefile.config
include $(CONFIG)
include $(CONFIG_LOCAL)
这部分指定了两个配置文件的路径,通过 include 指令,Makefile 将读取并执行这些配置文件中定义的指令,允许你在这些配置文件中设置一些变量或者编译标志等。
基本路径设置:
BUILD_PATH := build
SRC_PATH := src
CUDA_DIR := /usr/local/cuda-$(CUDA_VER)
这里定义了构建目录(build)、源代码目录(src)和 CUDA 安装路径。
源文件和目标文件:
KERNELS_SRC := $(wildcard $(SRC_PATH)/*.cu)
APP_OBJS += $(patsubst $(SRC_PATH)%, $(BUILD_PATH)%, $(KERNELS_SRC:.cu=.cu.o))
KERNELS_SRC使用wildcard函数列出了所有在源代码目录下扩展名为.cu(CUDA 源文件)的文件。APP_OBJS通过patsubst函数将KERNELS_SRC中的源文件路径从src目录转换到build目录,并将扩展名从.cu改为.cu.o(即,目标文件)。
编译器和编译标志:
CUCC := $(CUDA_DIR)/bin/nvcc
CUDAFLAGS := -Xcompiler -fPIC
CUCC变量指向 CUDA 编译器nvcc的路径。CUDAFLAGS定义了传递给 CUDA 编译器的标志。在这里-Xcompiler标志用于将-fPIC选项传递给底层的 C/C++ 编译器,以生成位置无关代码(PIC)。
包含目录和库目录:
INCS := -I $(CUDA_DIR)/include \
-I $(SRC_PATH)
LIBS := -L "$(CUDA_DIR)/lib64" \
INCS定义了编译器查找头文件的目录。LIBS指定了链接器查找库文件的目录。
调试和警告选项:
ifeq ($(DEBUG),1)
CUDAFLAGS += -g -G -O0
else
CUDAFLAGS += -O3
endif
ifeq ($(SHOW_WARNING),1)
CUDAFLAGS += -Wall -Wunused-function -Wunused-variable -Wfatal-errors
else
CUDAFLAGS += -w
endif
这部分根据 DEBUG 和 SHOW_WARNING 变量的值来调整编译标志,以支持调试信息的生成和警告信息的显示。
目标定义:
all是默认目标,它依赖于变量$(APP)(这里没有显示定义,可能在包含的配置文件中定义)。update和$(APP)目标用于编译和链接应用程序。show目标用于打印出一些变量的值,以便于调试 Makefile。clean目标用于清理构建产物。
编译规则:
$(BUILD_PATH)/%.cu.o: $(SRC_PATH)/%.cu
@echo Compile CUDA $@
@mkdir -p $(BUILD_PATH)
@$(CUCC) -o $@ -c $< $(CUDAFLAGS) $(INCS)
这个规则用于编译 .cu 文件:它会为每个源文件创建对应的 .cu.o 对象文件。这包括创建构建目录,然后使用 nvcc 编译器和前面定义的编译选项来编译源文件。
特殊目标:
.PHONY: all update show clean
- 声明
all、update、show、clean为伪目标,这意味着它们不对应文件名,即使存在同名文件,也总是执行相关的命令。
Makefile 的分析到这里就结束了,这个还是需要大家对 Makefile 有一些基本的了解
博主之前有一些关于 Makefile 的笔记,大家感兴趣的可以看看:Makefile
6. 执行我们的第二个CUDA程序
我们来看第二个案例 2.2-cpp_cuda_interactive,包含的文件内容如下:

相比于第一个案例,这个多了一个 main.cpp 源文件,print_index.hpp 和 utils.hpp 两个头文件,我们希望 main.cpp 作为接口,通过 g++ 去编译调用 print_index.cu 中的核函数
main.cpp 中的内容如下:
#include <stdio.h>
#include <cuda_runtime.h>
#include "print_index.hpp"
void print_one_dim(int inputSize, int blockSize){
int gridSize = inputSize / blockSize;
dim3 block(blockSize);
dim3 grid(gridSize);
print_idx_device(block, grid);
// print_dim_device(block, grid);
// print_thread_idx_per_block_device(block, grid);
// print_thread_idx_device(block, grid);
}
void print_two_dim(int inputSize, int blockSize){
int gridSize = inputSize / blockSize;
dim3 block(blockSize, blockSize);
dim3 grid(gridSize, gridSize);
// print_idx_device(block, grid);
// print_dim_device(block, grid);
// print_thread_idx_per_block_device(block, grid);
print_thread_idx_device(block, grid);
}
int main(){
int inputSize;
int blockSize;
/* one-dimention test */
inputSize = 32;
blockSize = 4;
print_one_dim(inputSize, blockSize);
/* two-dimention test */
// inputSize = 8;
// blockSize = 4;
// print_two_dim(inputSize, blockSize);
return 0;
}
我们 main.cpp 中没有核函数的具体实现,只有几个接口函数,通过这几个接口函数调用我们的 CUDA 核函数完成相应的计算,这个其实是 CUDA 编程中非常常见的一种方式,通过 host 函数去调用 device 函数
值得注意的是我们对于所有的 CUDA API 的调用都套上了一个 CUDA_CHECK 函数,它的定义如下:
#ifndef __UTILS_HPP__
#define __UTILS_HPP__
#include <cuda_runtime.h>
#include <system_error>
// 一般cuda的check都是这样写成宏
#define CUDA_CHECK(call) { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("ERROR: %s:%d, ", __FILE__, __LINE__); \
printf("CODE:%d, DETAIL:%s\n", error, cudaGetErrorString(error)); \
exit(1); \
} \
}
#endif //__UTILS__HPP__
这个代码段定义了一个非常有用的宏 CUDA_CHECK,其主要用途是简化 CUDA API 调用的错误处理。CUDA 编程中,几乎所有的 CUDA API 函数调用都会返回一个 cudaError_t 类型的状态码,表示调用是否成功。正确的错误处理对于调试和确保 CUDA 应用程序稳定运行至关重要。
这个是 CUDA 编程中很常见的一种错误处理的方式,我们后续会详细介绍,这里先简单过一下。
7. Makefile添加的部分
第二个案例完整的 Makefile 内容如下:
下面依旧是一个 Makefile 文件,请你帮我找出其中与上一个 Makefile 文件添加的部分,并进行详细分析
CONFIG := ../../config/Makefile.config
CONFIG_LOCAL := ./config/Makefile.config
include $(CONFIG)
include $(CONFIG_LOCAL)
BUILD_PATH := build
SRC_PATH := src
CUDA_DIR := /usr/local/cuda-$(CUDA_VER)
CXX_SRC += $(wildcard $(SRC_PATH)/*.cpp)
KERNELS_SRC := $(wildcard $(SRC_PATH)/*.cu)
APP_OBJS := $(patsubst $(SRC_PATH)%, $(BUILD_PATH)%, $(CXX_SRC:.cpp=.cpp.o))
APP_OBJS += $(patsubst $(SRC_PATH)%, $(BUILD_PATH)%, $(KERNELS_SRC:.cu=.cu.o))
APP_DEPS := $(CXX_SRC)
APP_DEPS += $(KERNELS_SRC)
APP_DEPS += $(wildcard $(SRC_PATH)/*.hpp)
CUCC := $(CUDA_DIR)/bin/nvcc
CXXFLAGS := -std=c++11 -fPIC
CUDAFLAGS := -Xcompiler -fPIC
INCS := -I $(CUDA_DIR)/include \
-I $(SRC_PATH)
LIBS := -L "$(CUDA_DIR)/lib64" \
ifeq ($(DEBUG),1)
CUDAFLAGS += -g -O0 -G
CXXFLAGS += -g -O0
else
CUDAFLAGS += -O3
CXXFLAGS += -O3
endif
ifeq ($(SHOW_WARNING),1)
CUDAFLAGS += -Wall -Wunused-function -Wunused-variable -Wfatal-errors
CXXFLAGS += -Wall -Wunused-function -Wunused-variable -Wfatal-errors
else
CUDAFLAGS += -w
CXXFLAGS += -w
endif
all:
$(MAKE) $(APP)
update: $(APP)
@echo finished updating $<
$(APP): $(APP_DEPS) $(APP_OBJS)
@$(CUCC) $(APP_OBJS) -o $@ $(LIBS) $(INCS)
@echo finished building $@. Have fun!!
show:
@echo $(BUILD_PATH)
@echo $(APP_DEPS)
@echo $(INCS)
@echo $(APP_OBJS)
@echo $(APP_MKS)
clean:
rm -rf $(APP)
rm -rf build
ifneq ($(MAKECMDGOALS), clean)
-include $(APP_MKS)
endif
# Compile CXX
$(BUILD_PATH)/%.cpp.o: $(SRC_PATH)/%.cpp
@echo Compile CXX $@
@mkdir -p $(BUILD_PATH)
@$(CC) -o $@ -c $< $(CXXFLAGS) $(INCS)
# Compile CUDA
$(BUILD_PATH)/%.cu.o: $(SRC_PATH)/%.cu
@echo Compile CUDA $@
@mkdir -p $(BUILD_PATH)
@$(CUCC) $(ARCH) -o $@ -c $< $(CUDAFLAGS) $(INCS)
.PHONY: all update show clean
我们来看下有了 C++ 之后的 CUDA 程序的 Makefile 文件需要添加哪些东西:(from ChatGPT)
C++ 源文件的处理:
CXX_SRC += $(wildcard $(SRC_PATH)/*.cpp)
APP_OBJS := $(patsubst $(SRC_PATH)%, $(BUILD_PATH)%, $(CXX_SRC:.cpp=.cpp.o))
APP_DEPS := $(CXX_SRC)
- 新增对
.cpp文件的处理,包括查找源码、转换为对象文件的路径,并添加为依赖。
C++ 编译选项:
CXXFLAGS := -std=c++11 -fPIC
- 定义了 C++ 的编译选项,包括使用 C++11 标准和生成位置无关代码。
编译 C++ 源文件的规则:
$(BUILD_PATH)/%.cpp.o: $(SRC_PATH)/%.cpp
@echo Compile CXX $@
@mkdir -p $(BUILD_PATH)
@$(CC) -o $@ -c $< $(CXXFLAGS) $(INCS)
- 新增了一个规则来编译
.cpp文件为.cpp.o对象文件,使用的是$(CC)编译器(通常指向gcc或g++),这使得 Makefile 能够处理 C++ 源文件。
相比于第一个案例的 Makefile,这个版本通过引入对 C++ 源文件的支持以及条件编译选项的扩展,大大增强了其灵活性和通用性。这些改进使得 Makefile 能够更好地适应复杂的项目结构,处理不同类型的源文件,并提供更精细的构建控制
OK,以上就是第一小节有关 CUDA 中的线程和线程束的全部内容了
总结
本次课程我们学习了 CUDA 编程中的一些基础概念,首先通过执行我们的第一个 CUDA 程序案例我们了解了 CUDA 中的 Grid 和 Block 的概念,它们是为了我们能够快速索引而产生的逻辑意义上的东西,物理意义上并不存在。之后我们通过分析第一个案例了解了各自情况下的 idx 索引的计算,然后我们简单的聊了一下 nvcc 以及 Makefile,并通过第二个案例了解了同时包含 C++ 和 CUDA 程序的 Makefile 该如何编写。总之,这里只聊了 CUDA 编程中一些基本的东西,更多的知识比如 warp 线程束还有 Makefile 的规则等等内容可能需要大家额外补充了。
OK,以上就是第 1 小节有关 CUDA 中的线程与线程束的全部内容了,下节我们来学习使用 CUDA 来进行矩阵乘法的加速,敬请期待😄























![[Python初阶]2255.统计是给定字符串前缀的字符串数目](https://img-blog.csdnimg.cn/direct/3742d4f235514dc99b133a838981d004.png)