GiT: Towards Generalist Vision Transformer through Universal Language Interface
相关链接:arxiv github
关键字:Generalist Vision Transformer (GiT)、Universal Language Interface、Multi-task Learning、Zero-shot Transfer、Transformer
摘要
本文提出了一个简单而有效的框架,称为GiT,仅使用普通的ViT即可应用于各种视觉任务。受大型语言模型(LLMs)中广泛使用的多层Transformer架构(例如GPT)的普适性启发,我们寻求将其扩展应用作为强大的视觉基础模型(VFM)。然而,与语言建模不同,视觉任务通常需要特定的模块,如检测中的边界框头和分割中的像素解码器,这极大地阻碍了强大的多层Transformer在视觉领域中的应用。为了解决这个问题,我们设计了一个通用语言接口,使得成功的自回归解码能够熟练地统一各种视觉任务,从图像级别理解(例如标题生成)到稀疏感知(例如检测),再到密集预测(例如分割)。基于上述设计,整个模型仅由一种ViT组成,无需任何特定的添加,提供了显著的架构简化。GiT是一个多任务视觉模型,跨五个代表性基准联合训练而无需任务特定的微调。有趣的是,我们的GiT在通用表现方面树立了新的基准,并促进了任务之间的相互提升,与孤立训练相比有了显著的改善。这反映了LLMs中观察到的类似影响。通过进一步丰富27个数据集的训练,GiT在多种任务上实现了强大的零样本结果。由于它的设计简单,这种范式有望缩小视觉和语言之间的架构差距。代码和模型将在 https://github.com/Haiyang-W/GiT 上提供。
核心方法
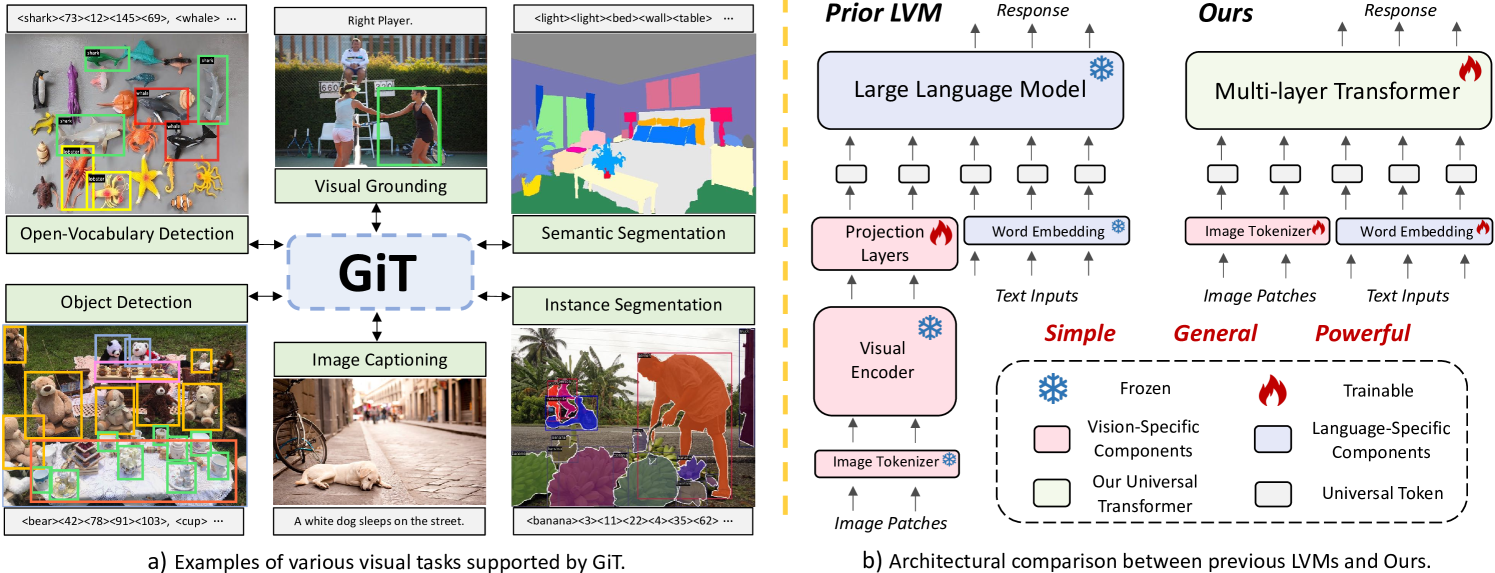
GiT 的核心方法包括:
- 通用语言接口:设计了能够将图像和语言统一表示为标准词汇的token序列,简化了对于各种视觉任务的处理。
- 多任务模板和并行解码:提出了一种框架将图像划分为多个子区域,并通过并行解码来同时处理这些子任务,提高了处理效率。
- 模型架构:采用多层Transformer架构,并且在不依赖于视觉特定组件的情况下处理各种视觉任务,与大型语言模型架构一致。
实验说明
Object Detection (目标检测)
| Model | Specific Modules | Num | #Params | AP | AP50 | AP75 |
|---|---|---|---|---|---|---|
| Faster R-CNN-FPN | ResNet,RPN | 5 | 42M | 40.3 | - | - |
| GiT-Bsingle-task | None | 1 | 131M | 45.1 | 62.7 | 49.1 |
| GiT-Bmulti-task | None | 1 | 131M | 46.7 | 64.2 | 50.7 |
| GiT-Hmulti-task | None | 1 | 756M | 52.9 | 71.0 | 57.8 |
GiT 在目标检测任务中表现出色,即使在没有特定任务模块的情况下,其多任务训练的模型(GiT-Hmulti-task)也能达到最优表现。
Instance Segmentation (实例分割)
| Model | Specific Modules | Num | #Params | AP | AP50 | AP75 |
|---|---|---|---|---|---|---|
| Mask R-CNN | ResNet,RPN | 6 | 46M | 41.0 | 61.7 | 44.9 |
| GiT-Bsingle-task | None | 1 | 131M | 31.4 | 54.8 | 31.2 |
| GiT-Bmulti-task | None | 1 | 131M | 31.9 | 56.4 | 31.4 |
| GiT-Hmulti-task | None | 1 | 756M | 35.8 | 62.6 | 35.6 |
即使在实例分割任务中,GiT 的多任务训练模型仍然展示了突出的改善和潜力。
Semantic Segmentation (语义分割)
| Model | Specific Modules | Num | #Params | mIoU(SS) |
|---|---|---|---|---|
| DeepLabV3+ | ResNet,Decoder | 3 | 63M | 80.9 |
| GiT-Bsingle-task | None | 1 | 131M | 47.7 |
| GiT-Bmulti-task | None | 1 | 131M | 47.8 |
| GiT-Hmulti-task | None | 1 | 756M | 52.4 |
语义分割任务中,GiT 模型也能够在没有专门模块的情况下取得与专家系统相媲美的成绩。
Captioning (图像标题生成)
| Model | Specific Modules | Num | #Params | BLEU-4 | CIDEr |
|---|---|---|---|---|---|
| VL-T5 | Faster R-CNN | 3 | 440M | - | 116.5 |
| GiT-Bsingle-task | None | 1 | 131M | 33.7 | 107.9 |
| GiT-Bmulti-task | None | 1 | 131M | 35.4 | 112.6 |
| GiT-Hmulti-task | None | 1 | 756M | 36.2 | 118.2 |
图像标题生成任务显示,GiT 在多任务的训练下,取得了一致的优良表现。
结论
本论文介绍了一个基于简单的多层Transformer的通用视觉建模范式,该模型能够集成各种视觉中心任务,尤其是经常被忽视的对象级和像素级任务。类似于语言模型,所有视觉任务都通过通用语言接口结构化为自回归框架。GiT模型展现了与LLM类似的多任务能力,实现了多个基准上最好和相互增强的全面性能。也展现了强大的泛化能力,在27个公开可用数据集上的训练中实现了令人信服的零样本和少样本性能。
GiT在多个视觉任务中表现出色,不仅构建了一种新的通用视觉Transformer和语言接口的范式,而且还展示了跨任务增强和强大的零样本学习能力,为未来的研究提供了新的视角。