Sambert-Hifigan模型介绍
拼接法和参数法是两种Text-To-Speech(TTS)技术路线。近年来参数TTS系统获得了广泛的应用,故此处仅涉及参数法。
参数TTS系统可分为两大模块:前端和后端。 前端包含文本正则、分词、多音字预测、文本转音素和韵律预测等模块,它的功能是把输入文本进行解析,获得音素、音调、停顿和位置等语言学特征。 后端包含时长模型、声学模型和声码器,它的功能是将语言学特征转换为语音。其中,时长模型的功能是给定语言学特征,获得每一个建模单元(例如:音素)的时长信息;声学模型则基于语言学特征和时长信息预测声学特征;声码器则将声学特征转换为对应的语音波形。
系统结构:

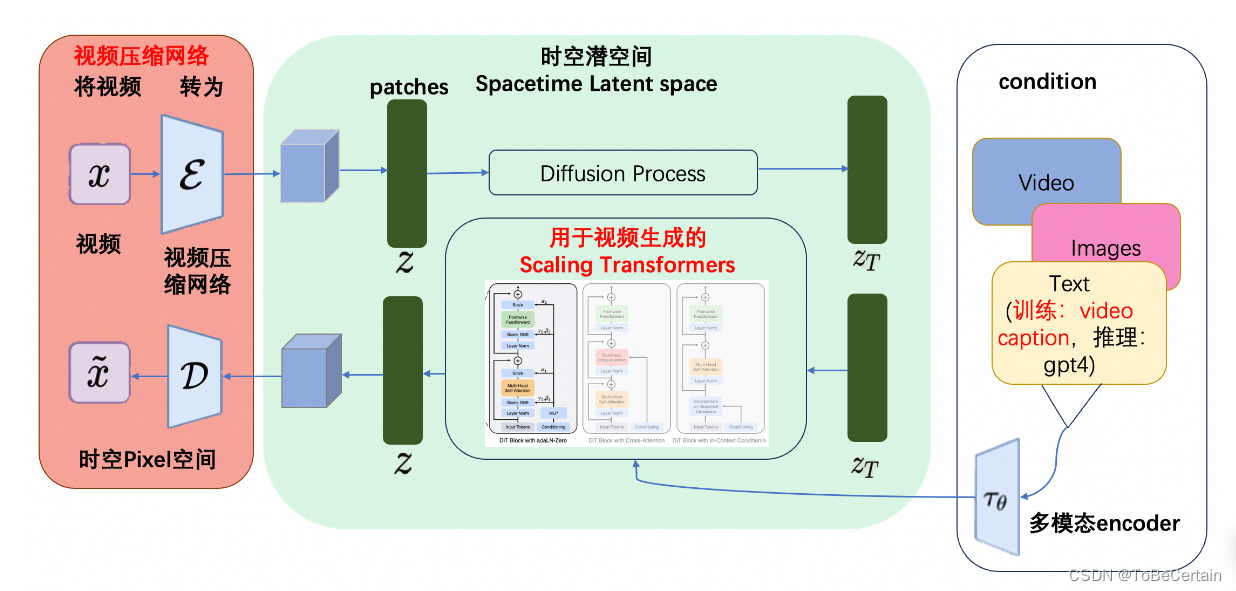
声学模型SAM-BERT
后端模块中声学模型采用自研的SAM-BERT,将时长模型和声学模型联合进行建模
1. Backbone采用Self-Attention-Mechanism(SAM),提升模型建模能力。
2. Encoder部分采用BERT进行初始化,引入更多文本信息,提升合成韵律。
3. Variance Adaptor对音素级别的韵律(基频、能量、时长)轮廓进行粗粒度的预测,再通过decoder进行帧级别细粒度的建模;并在时长预测时考虑到其与基频、能量的关联信息,结合自回归结构,进一步提升韵律自然度.
4. Decoder部分采用PNCA AR-Decoder[@li2020robutrans],自然支持流式合成。

声码器模型
后端模块中声码器采用HIFI-GAN, 基于GAN的方式利用判别器(Discriminator)来指导声码器(即生成器Generator)的训练,相较于经典的自回归式逐样本点CE训练, 训练方式更加自然,在生成效率和效果上具有明显的优势。
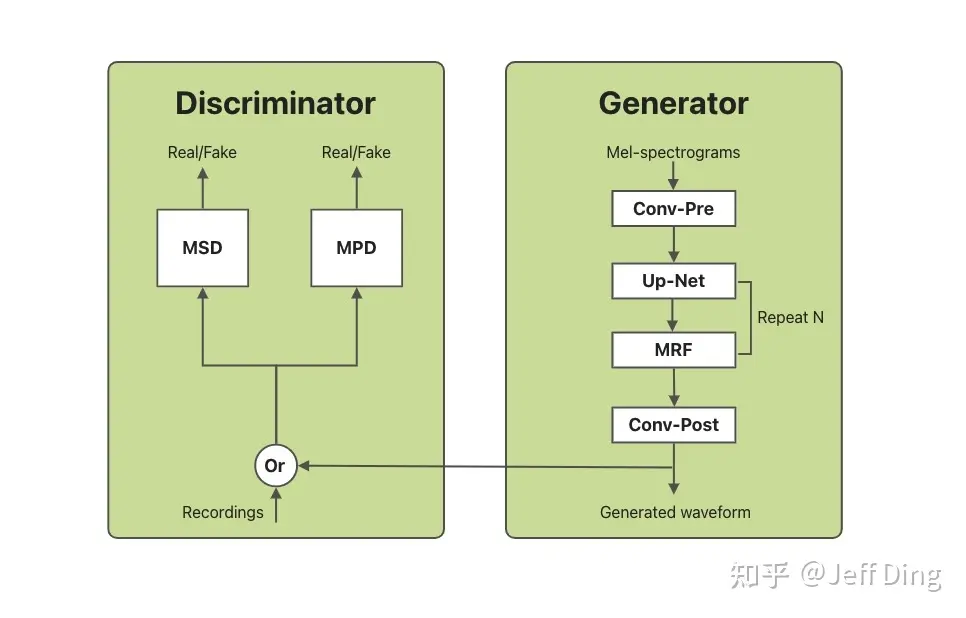
在HIFI-GAN开源工作[1]的基础上,我们针对16k, 48k采样率下的模型结构进行了调优设计,并提供了基于因果卷积的低时延流式生成和chunk流式生成机制,可与声学模型配合支持CPU、GPU等硬件条件下的实时流式合成。
环境准备
下载KAN-TTS代码仓代码
git clone https://github.com/alibaba-damo-academy/KAN-TTS模型准备
语音合成-上海话-通用领域-16k-发音人xiaoda 模型地址
https://modelscope.cn/models/speech_tts/speech_sambert-hifigan_tts_xiaoda_WuuShanghai_16k
创建conda环境
cd KAN-TTS
conda create -n kantts python=3.10激活环境,前面通过environment.yml文件安装的环境名为maas
conda activate kantts安装torch
pip install torch torchvision torchaudio安装依赖
pip install autopep8
pip install pre-commit
pip install modelscope
pip install matplotlib
pip install librosa
pip install ttsfrd --find-links https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install unidecode
pip install inflect
pip install pytorch_wavelets
pip install PyWavelets
pip install tensorboardX代码脚本(demo.py)
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
def read_text_file(filename):
with open(filename, 'r', errors='ignore') as file:
text = file.read()
cleaned_text = ''.join(text.split()).strip()
return cleaned_text
# 使用方法
text = read_text_file('文件名.txt')
model_id = 'speech_tts/speech_sambert-hifigan_tts_xiaoda_WuuShanghai_16k'
sambert_hifigan_tts = pipeline(task=Tasks.text_to_speech, model=model_id)
output = sambert_hifigan_tts(input=text)
wav = output[OutputKeys.OUTPUT_WAV]
with open('output.wav', 'wb') as f:
f.write(wav)
运行脚本
python demo.py