目录
Http协议介绍
HTTP(全称为“超文本传输协议”)是一种应用很广泛的 应用层协议.
http往往是基于传输层的TCP协议实现的.
HTTP 是一个文本格式的协议. 学习HTTP协议,重点学习HTTP的报文格式,分为两部分看待,请求 和 响应. 可以通过 Chrome 开发者工具或者 Fiddler 抓包, 分析 HTTP 请求/响应的细节.

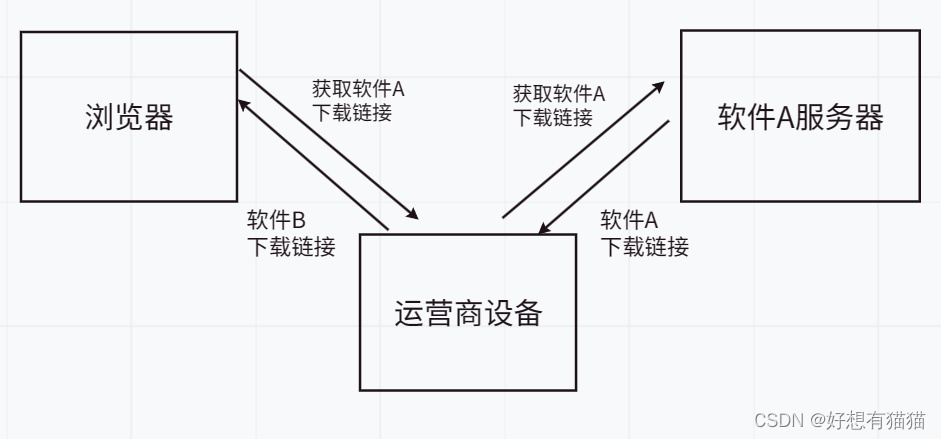
http使用场景:1.浏览器访问网站 2.手机App访问对应的服务器 (通过http协议传输数据)
HTTP协议工作流程
- 请求: 客户端给服务器发送的数据.
- 回应: 服务器给客户端返回的数据.
当我们在Bing浏览器中输入一个 "搜狗网址", 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应.
 .
.

事实上, 当我们访问一个网站的时候, 可能涉及不止一次的 HTTP 请求/响应 的交互过程.
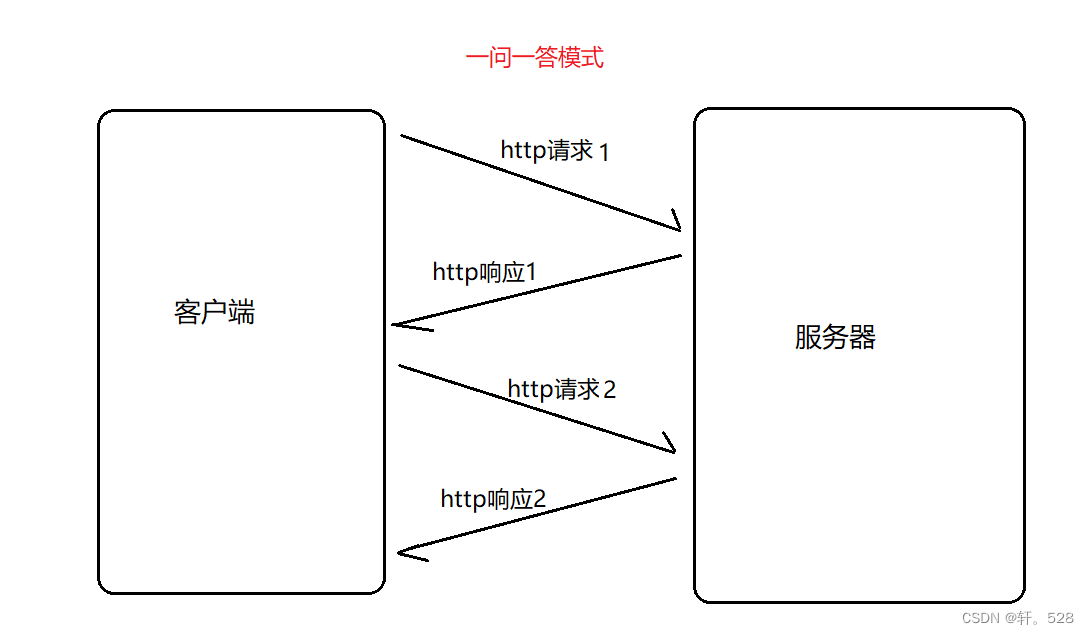
http协议,是一种“一问一答” 结构模型的协议。请求和响应的协议和格式。
一问一答:访问网站
多问多答:上传文件
一问多答:下载文件
多问多答:串流/ 远程桌面
Fiddler抓包工具介绍
Fidder官方下载地址:https://www.telerik.com/fiddler/
安装可以自定义路径一路next,就可以非常简答 !
Fiddler 使用
新安装的fidder 还需要我们手动开启 HTTPS 功能,并且安装证书的. (否则只能抓htttp)
1.打开fidder, 找到Tools,点击Options.

2. 选HTTPS,把对号都选上,会弹出一个框,意思就是是否要安装证书,选Yes就完了.

上诉操作完成之后就可以使用了.
3.fidder打开之后,是一个左右结构的程序,左边有一个列表,列出抓到的包有哪些

4.fiddler 右边就是包的详情.(点击左边某个包)

- 左侧窗口显示了所有的 HTTP请求/响应, 可以选中某个请求查看详情.
- 右侧上方显示了 HTTP 请求的报文内容. (切换到 Raw 标签页可以看到详细的数据格式)
- 右侧下方显示了 HTTP 响应的报文内容. (切换到 Raw 标签页可以看到详细的数据格式)
- 请求和响应的详细数据, 可以通过右下角的 View in Notepad 通过记事本打开.
可以使用 ctrl + a 全选左侧的抓包结果, delete 键清除所有被选中的结果.
HTTP请求(request)
首行
首行由http请求的“方法”(methon)、url 、版本号三部分组成.
请求方法
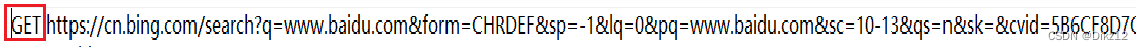
![]()
这两个方法是较为重要的方法!!
GET方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.
打开 Fiddler, 访问 百度主页, 观察抓包结果.

图中标记的就是通过浏览器地址栏发送的 GET 请求.
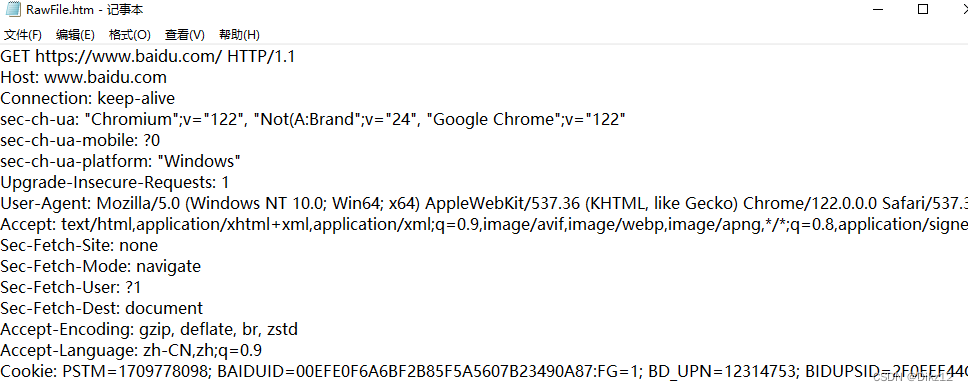
GET 请求的特点
- 首行的第一部分为 GET
- URL 的 query string 可以为空, 也可以不为空.
- header 部分有若干个键值对结构.
- body 部分为空.
POST方法
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面).

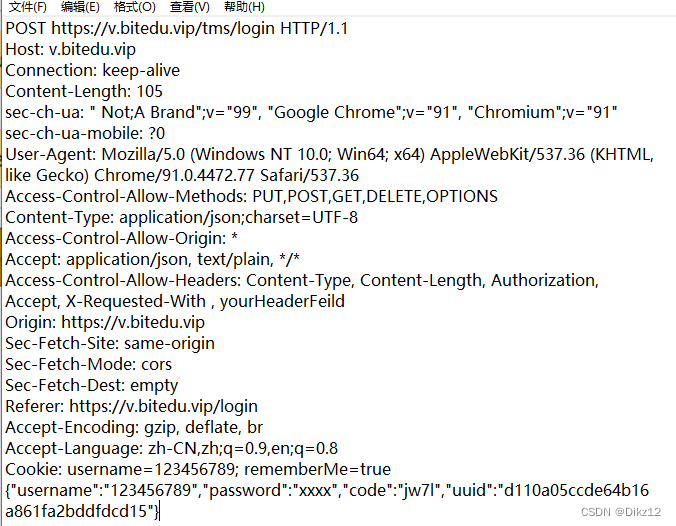
POST 请求的特点
- 首行的第一部分为 POST
- URL 的 query string 一般为空 (也可以不为空)
- header 部分有若干个键值对结构.
- body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定. body 的长度由
- header 中的 Content-Length 指定.
其它方法
- PUT 与 POST 相似,只是具有幂等特性,一般用于更新
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
这些方法不需要记,也就是说不需要去遵守场景要求,没有所谓的约束, 它们能做的get 和 post 也能做到.
GET 和 POST的区别
首先,GET 和 POST 没有本质区别!!!(双方可以替换对方的场景)
虽没有本质区别,但是在使用习惯上,还是存在差异的.
1.GET 习惯把传递的数据放到query string 中,POST则是习惯把传递的数据放到body中.
(情况并非绝对!!!,当然还是建议大家这样操作.)
2.语义上的差异.
GET 大多数还是用来获取数据.
POST 大多数还是用来提交数据.(登录+上传)
网上一些错误说法:
1.GET请求传递数据数据不安全. POST请求传递数据更安全.
依据就是:如果使用GET请求来实现登录,点击登录的时候,会把用户名和密码放到 url 中,进一步显示到浏览器地址栏里.(就被别人看见了). 相对于POST,则是放在body中,不会在界面上显示,所以更安全.
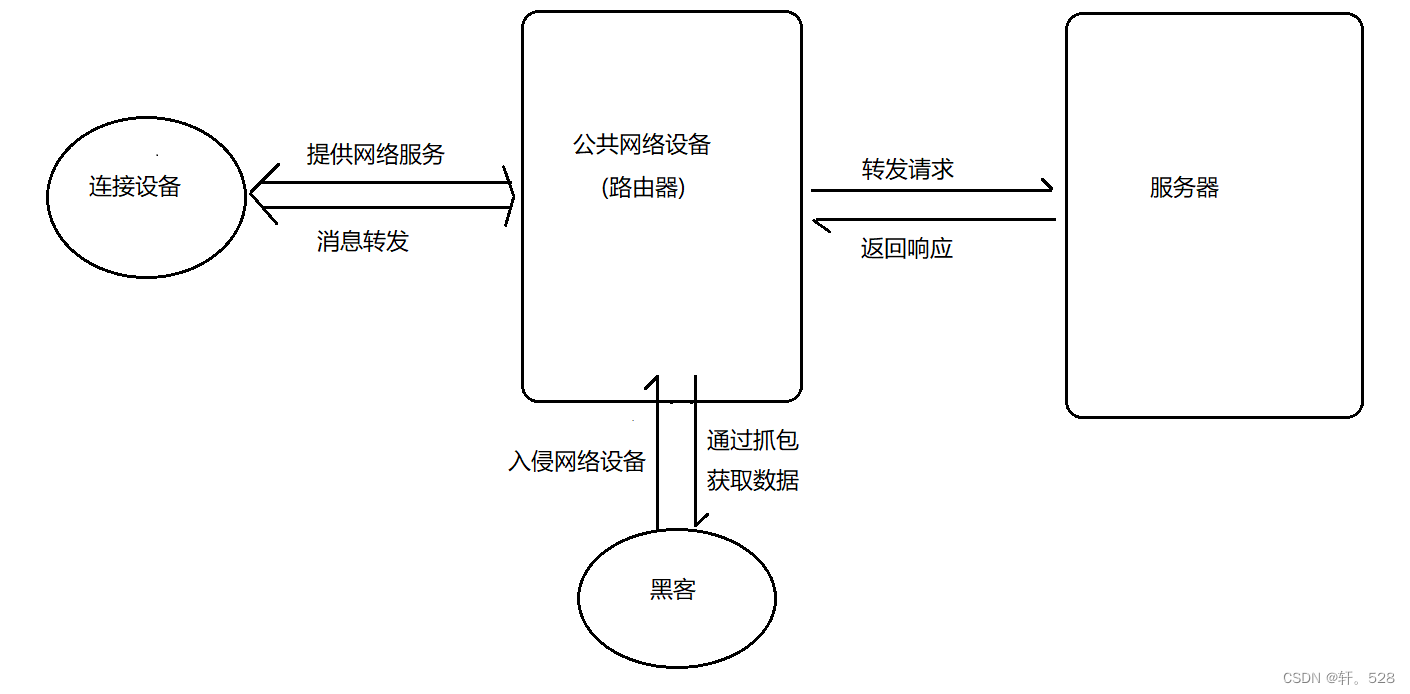
这种说法,也就能忽悠下小白了,对于黑客来说成本并不高,就如下图:用fiddler抓包得到的,用户名和密码,安不安全的关键是加密!!!
![]()
2. GET 请求能传递的数据量有上限,POST传递的数据量没有上限.
这个说法是上古时期的一个遗留问题,早起版本的浏览器硬件资源非常匮乏,针对GET请求的url 做出了限制.实际上,RFC标准文档中并没有明确规定url 能有多长. 目前,浏览器和服务器的实现过程中,url可以非常长.
URL
URL,描述了某个资源在网络上所属的位置. 就可以理解成jdbc 里的url. 数据库也算是一种“资源”.

版本号
这就很简单,首行的最后就是http 的版本.

请求头(header)
header 的整体的格式也是 "键值对" 结构.
每个键值对占一行. 键和值之间使用分号分割
Host
表示服务器主机的地址和端口.
Content-Length
表示 body 中的数据长度.
Content-Type
表示请求的 body 中的数据格式.
User-Agent (简称 UA)
表示浏览器/操作系统的属性. 形如
![]()
Referer
表示这个页面是从哪个页面跳转过来的. 形如:

Cookie
可以认为是浏览器在本地存储的一种机制.

浏览器的数据来自于服务器. 而且浏览器的后续操作也是要提交给服务器的.
服务器就相当于一个网站的各种核心数据.
程序在运行过程中,也会有一些数据,需要在浏览器这边存储,并且在后续请求的时候数据可能需要再发给服务器. (上次登录时间、上次访问时间、用户的身份信息、累计访问次数.....)


空行 和 正文 boby 就不在演示了!!! 用fiddler抓包工具观察一下就可以!!非常简单
HTTP响应
认识“状态码”

- 2xx:都表示成功.
- 3xx: 表示重定向. 重定向:请求中访问的是A 这样的地址,响应返回了一个重定向报文,告诉你应该要访问B的地址.
- 5xx: 表示服务器出错了. 也就是服务器挂了.

响应报头(header)
响应报头的格式跟请求报文格式基本一致,也就是 Content-Type 中的body数据格式不一样.

客户端如何构造一个请求?
1.直接在浏览器地址栏输入URL

2.通过form表单来触发GET / POST 请求
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>hello</title>
</head>
<body>
<form action="http://www.sogou.com/abc.html" method="get">
<input type="text" name="key1">
<input type="text" name="key2">
<input type="text" name="key3">
<input type="submit" value="提交">
</form>
</body>
</html>
3.这种也是最简单的借助第三方工具 --> postman


HTTP协议格式总结

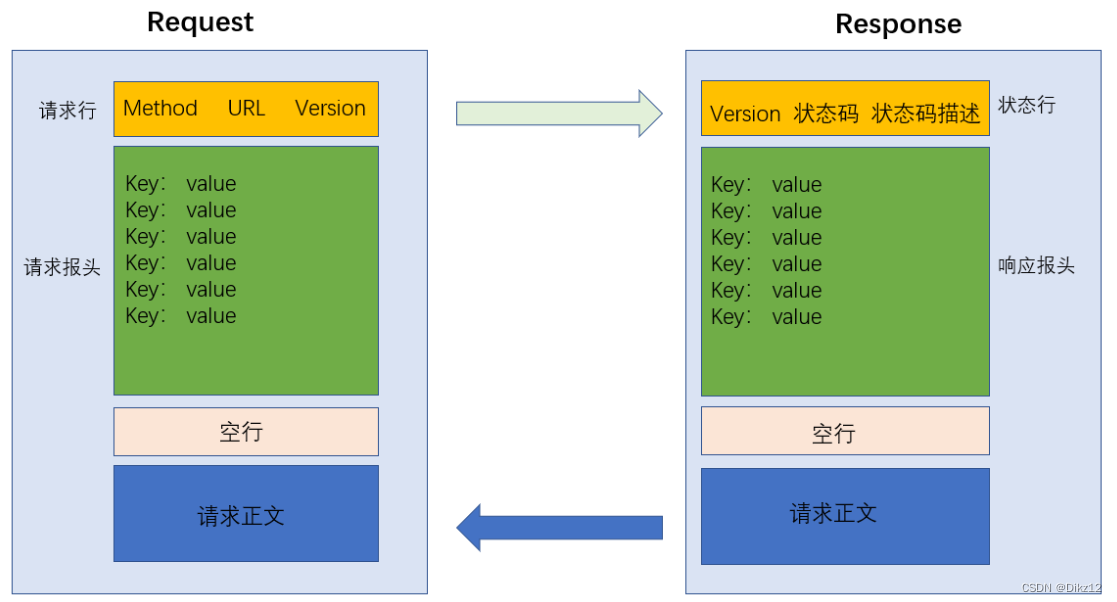
思考问题: 为什么 HTTP 报文中要存在 "空行"?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 "报头的结束标记", 或者是 "报头和正文之间的分隔符".
HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 "粘包问题".
![[<span style='color:red;'>计算机</span><span style='color:red;'>网络</span>]---<span style='color:red;'>Http</span><span style='color:red;'>协议</span>](https://img-blog.csdnimg.cn/f55a07090b3541518429c3017449bf1b.png)