编者
这是缺失数据填补的系列文章第三篇。
复现文章介绍
今天要介绍的复现文章是发表在《Cardiovasc Diabetol》(一区top,IF= 9.30)的题为“Association between the cumulative average triglyceride glucose-body mass index and cardiovascular disease incidence among the middle-aged and older population: a prospective nationwide cohort study in China”的研究论文。

题目:中老年人群累积平均甘油三酯葡萄糖-体重指数与心血管疾病发病率的关系
本公众号回复“立春”即可获得“立春”临床统计学沙龙PPT,数据等资料 |
1. 研究设计
P(Population)研究对象:选择2011(wave 1)和2015(wave 3)的数据,最终纳入5418名CHARLS数据库参与者。
E(Exposure)暴露:根据累积平均TyG-BMI(甘油三酯葡萄糖-体重指数)的四分位数分为四组(Q1-Q4)。
O(Outcome)结局:是否发生CVD(心血管)事件。
S(Study design)研究类型:回顾性队列研究。
2. 统计学方法
2.1 为了保持尽可能大的样本量,尽管缺失数据的比例很小,但我们采用了多重插补方法来解决缺失变量。


2.2 为了评估累积平均TyG-BMI与CVD发病率之间的关系,建立了单变量和多变量logistic回归模型,并给出了比值比(OR)及其95%置信区间(95% CI)。

2.3 此外,进行多变量调整(完全调整)限制性三次样条(RCS) logistic回归分析(分别选取4节、5、35、65和95百分位),检验累积平均TyG-BMI与CVD发病率之间的线性关系和剂量-反应关系。

2.4 为了检测潜在的修饰作用,进行了各种亚组分析和相互作用分析。

2.5 敏感性分析

3. 文章数据介绍
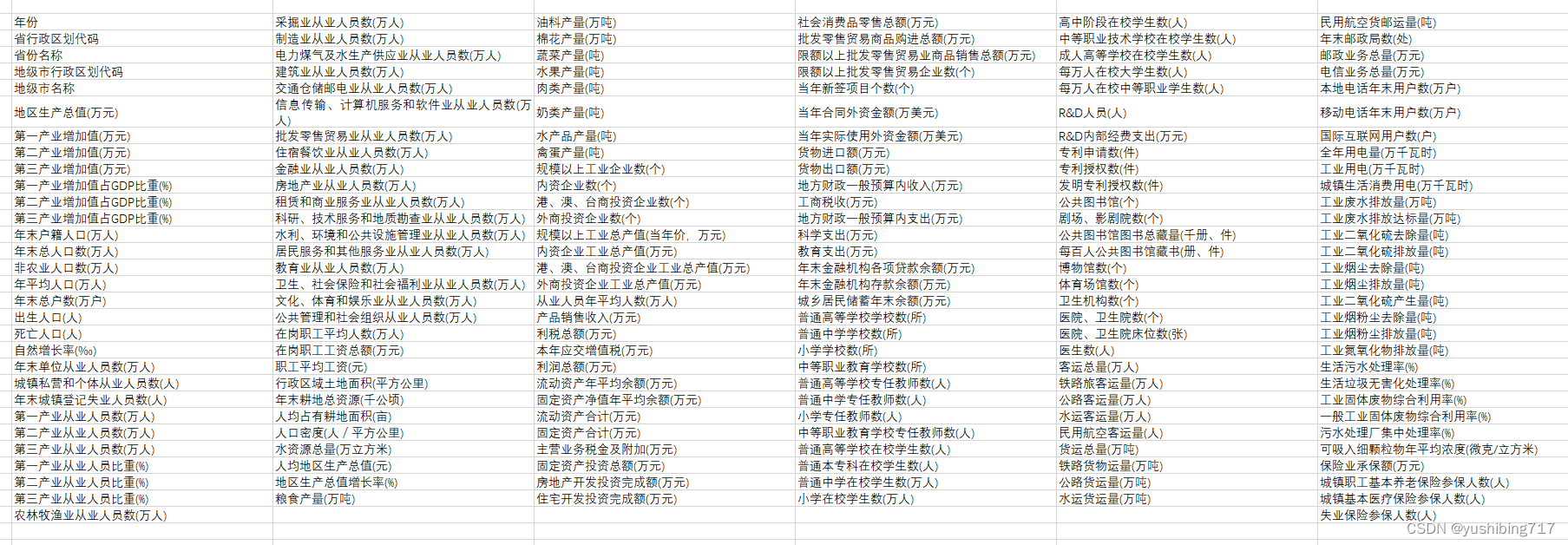
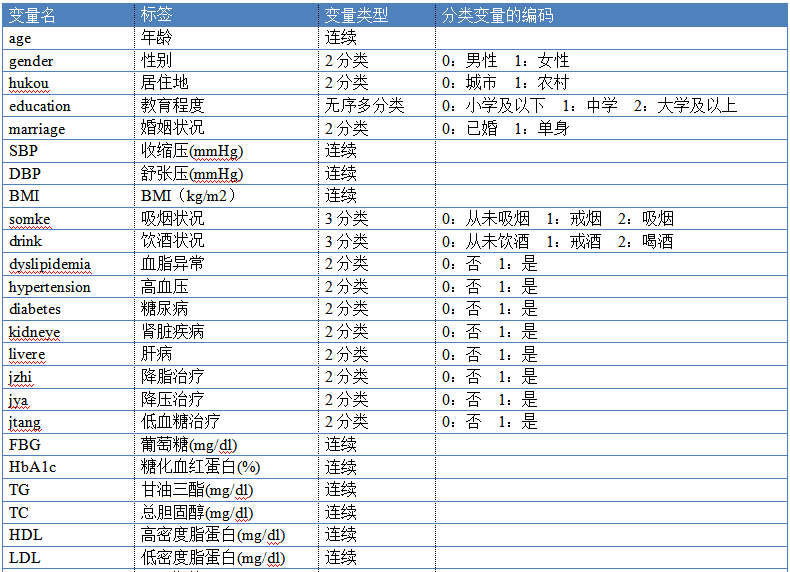
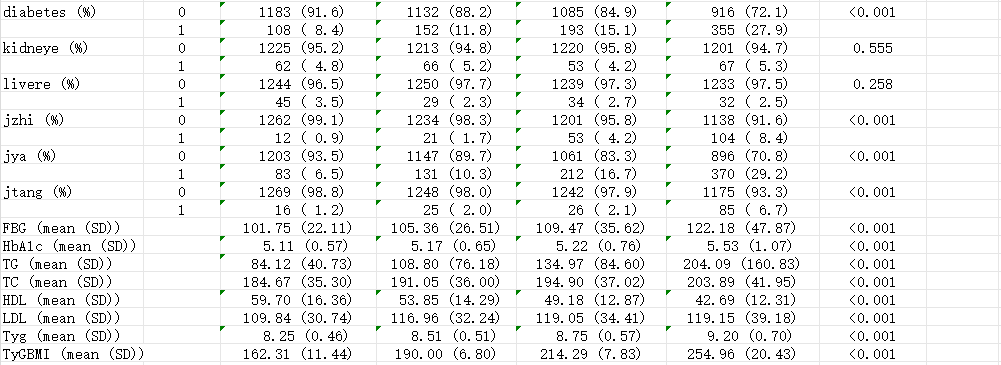
研究涉及CHARLS数据库的变量如下表所示,本次复现所用到的变量也与文章保持一致。

R语言复现
本次复现包括的统计学方法有:
基线差异性分析
缺失数据填补
多因素logistic回归
绘制限制性立方样条图(RCS)
亚组分析以及交互作用分析
绘制森林图
1. 首先,加载R包和导入数据。
首先,导入我们从CHARLS数据库中提取处理好的数据,本次复现数据包括5124名研究对象(原文章n=5418),样本量略有出入,这里大家请多关注统计方法的运用。
2. 基线差异性分析
本次复现基线表格用到了tableone包,这里“myVars”汇总了基线表中的全部变量,其中有部分变量为分类变量,则需要通过“catVars”进行指定,否则分类数据也将以定量数据进行展示。
这里tab1与tab2展示了2种统计描述的方式,tab1中未指定分组变量,则仅展示各变量的数据分布,tab2中利用“strata =”指定了分组变量,在展示数据分布的基础上,增加了分组数据间的差异性比较。
最后,将基线表结果输出保存在工作空间里,这里我们设置保存为csv格式!
csv格式结果展示如下:
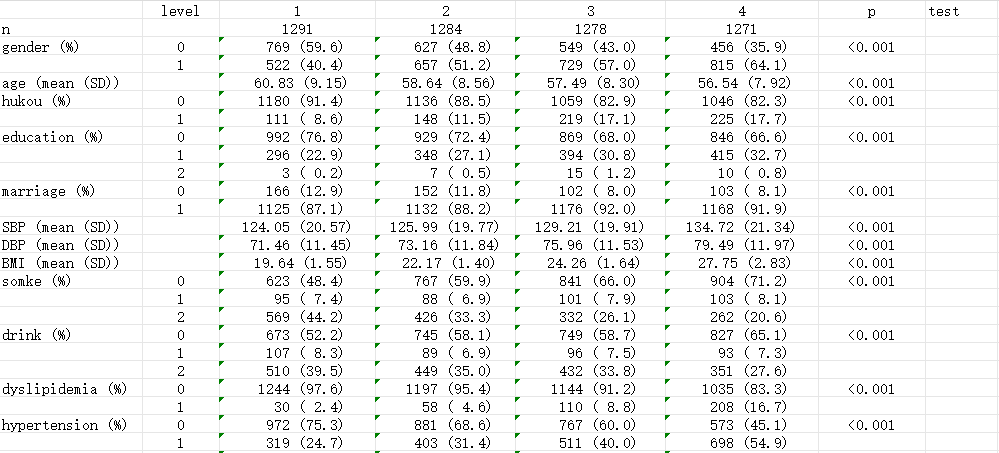
3. 缺失数据填补
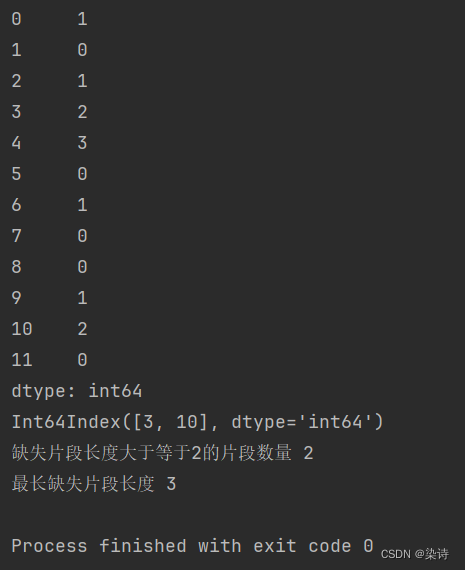
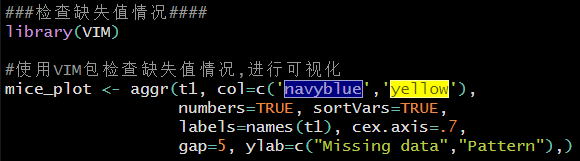
首先,使用VIM包检查缺失值情况,进行可视化。

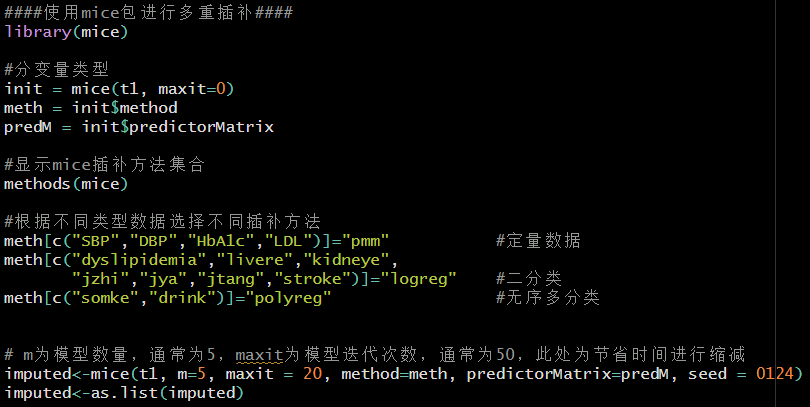
利用mice包对缺失数据进行多重插补,m:多重插补法的数量,默认为 5。method:指定数据中每一列的输入方法。
数值型数据适用 pmm;
二分类数据适用 logreg;
无序多类别数据适用 ployreg;
有序多分类变量适用 polr。
默认方法为 pmm 。
maxit:迭代次数,一般为 50。
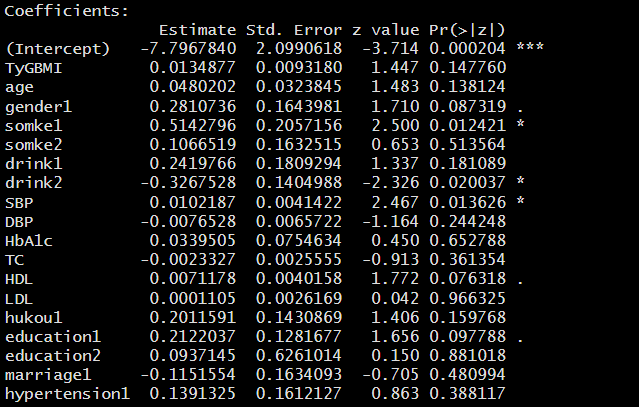
4. 多因素logistics回归
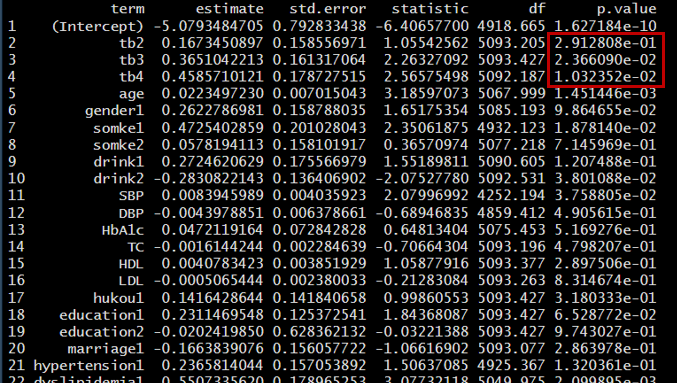
使用with函数对所有数据集进行分析,在填补的数据集中进行多因素logistic回归,最后使用pool函数对结果进行汇总输出。
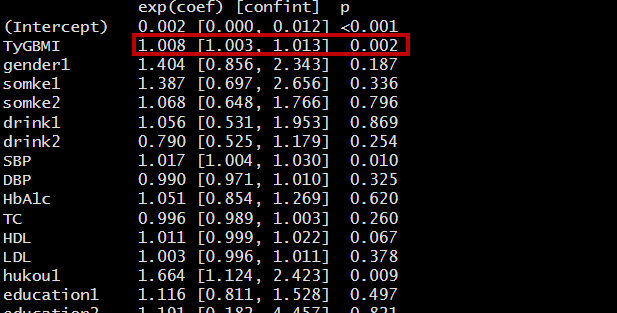
首先,将TyG-BMI按四分位数分组进行多因素logistics回归分析。

运行结果如下:
建立自定义函数,用于计算OR值及其95%置信区间,并输出β、S.E和P值。
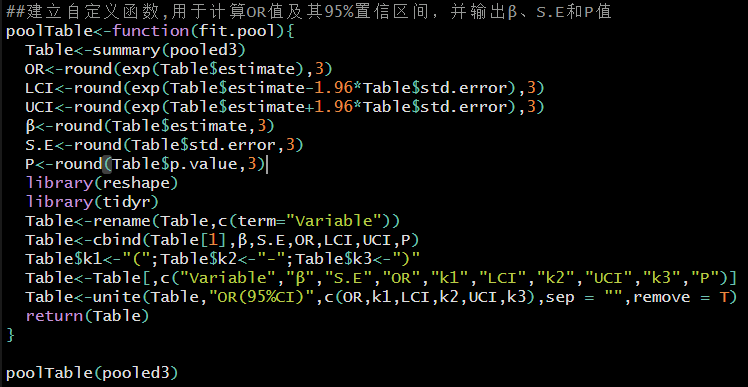
运行结果如下:

然后,将TyG-BMI按每升高一个SD进行多因素logistics回归分析,需要对TyG-BMI进行标准化。同上,建立自定义函数,用于计算OR值及其95%置信区间,并输出β、S.E和P值。

运行结果如下:

5. 绘制限制性立方样条图(RCS)
计算非线性关系P值与OR值。
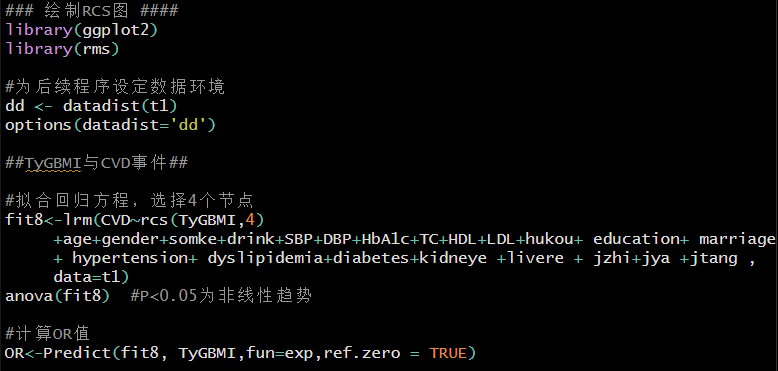
利用ggplot2包和rms包绘制RCS图,ggplot2包绘制图像就会灵活许多,譬如说添加一条辅助线,"geom_hline"指辅助线的纵轴位置,"linetype=2"定义线条类型为虚线,同理,"geom_vline"指辅助线的横轴位置,这里的"xintercept"值需要查询我们上一步计算的OR表,找到OR=1对应的变量值。
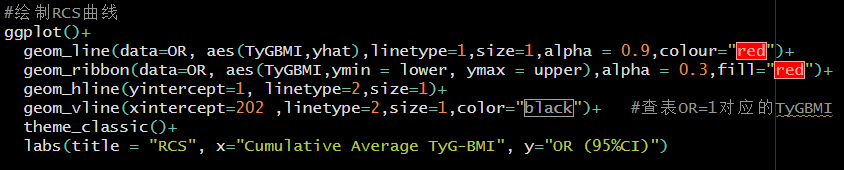
运行结果如下:

6. 亚组分析以及交互作用分析
通过subset函数进行分组,生成新的数据集,下面以年龄age1为例进行亚组分析,利用tableone包的ShowRegTable函数产生OR值和置信区间,之后只要将”data= “改为相应的数据集即可。

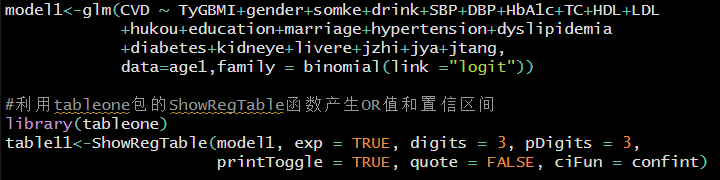
运行结果如下:
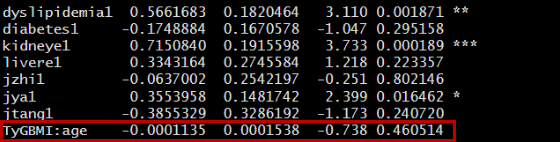
以年龄age为例进行交互作用分析,计算P for interaction

运行结果如下:
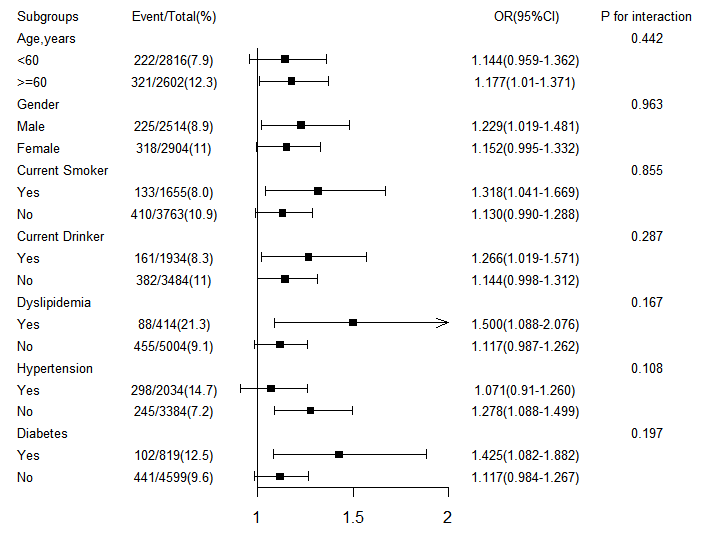
7. 绘制森林图
利用forestplot包绘制森林图。


运行结果如下:
后记
多重填补(multiple imputation,MI)是当前非常主流也是最受青睐的一种缺失值填补的方式,相较于删除,该方法可以将数据进行充分的应用,保证样本的代表性以及结果的可信度。
但是在使用多重填补法分析数据时,要根据实际情况选择填补次数,有学者建议填补次数应>5次,从而避免产生较大的误差;也有研究认为填补次数至少大于分析模型中缺失数据的百分比,例如缺失数据比例为30%,则填补次数应>30次。
如果看了本文依旧对多重插补一知半解或者对缺失值填补感兴趣,不妨看一下本公众号其他文章,希望能为各位读者在遇到相似的情况时提供可行的思路与方法。
本公众号回复“立春”即可获得“立春”临床统计学沙龙PPT,数据等资料 |
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: |