目录
一、边界计算与不对称边界
在C语言中,这个数组的下标范围是从0到9。一个拥有10个元素的数组中,它的元素的下标范围是从0到n-1。
例如,让我们仔细地来看看本书导读中的一段代码:
int i,a=[10];
for(i=1;i<=10;i++)
a[i]=0;
这段代码本意是要设置数组a中所有元素为0,
在for语句的比较部分本来是i<10,却写成了i<=10,循环体内将并不存在的a[10]设置为0,这就陷入了一个死循环。
1.栏杆错误
在所有常见的程序设计错误中,最难于察觉的一类是“栏杆错误”,也常被称为“差一错误”
100英尺长的围栏每隔10英尺需要一根支撑用的栏杆,一共需要多少根栏杆呢?
(1)最“显而易见”的答案是将100除以10,得到的结果是10.当然这个答案是错误的,正确答案是11。
(2)要支撑10英尺长的围栏实际需要2根栏杆,两端各一根。
(3_除了最右侧的一段围栏,其他每一段10英尺长的围栏都只在左侧有一根栏杆;而例外的最右侧一段围栏不仅左侧有一根栏杆,右侧也有一根栏杆。
实际上提示了我们避免“栏杆错误”的两个通用原则:
(1)首先考虑最简单情况下的特例,然后将得到的结果外推,这是原则一。
(2)仔细计算边界,绝不掉以轻心,这是原则二。
例如,假定整数x满足边界条件x>=16且x<=37,那么此范围内x的可能取值个数有多少?
根据原则一,我们考虑最简单情况下的特例。这里假定整数x的取值范围上界与下界重合,即x>=16且x<=16,显然合理的x取值只有1个整数,即16。
再考虑一般的情形,假定下界为1,上界为h。如果满足条件“上界与下界重合”,即1=h,亦即h-1=0。根据特例外推的原则,我们可以得出满足条件的整数序列有h-1+1个元素。就是37-16+1,即22。
造成“栏杆错误”的根源正是“h-1+1”中的“+1”。一个字符串中由下标为16到下标为37的字符元素所组成的子串,
用第一个入界点和第一个出界点来表示一个数值范围。具体而言,前面的例子我们不应说整数x满足边界条件x>=16且x<=37,而是说整数x满足边界条件x>=16且x<38。
注意:
下界是“入界点”,即包括在取值范围之中;
上界是“出界点”,即不包括在取值范围之中。
2.程序简化
对于程序设计的简化效果却足以令人吃惊:
1.取值范围的大小就是上界与下界之差。38-16的值是22,是不对称边界16和38之间所包括的元素数目。
2.如果取值范围为空,那么上界等于下界。这是第1条的直接推论。
3.即使取值范围为空,上界也永远不可能小于下界。
对于像C这样的数组下标从0开始的语言,不对称边界给程序设计带来的便利尤其明显:
这种数组的上界(即第一个“出界点”)恰是数组元素的个数!因此,如果我们要在C语言中定义一个拥有10个元素的数组,那么0就是数组下标的第一个“入界点”(指处于数组下标范围以内的点,包括边界点),而10就是数组下标中的第一个“出界点”(指不在数组下标范围以内的点,不含边界点)。正因为此,我们这样写:
int a[10], i;
for(i=0;i<10;i++)
a[i]=0;
而不是写成下面这样:
int a[10],i:
for(i = 0;i <= 9;i++)
a [i] = 0;
那么下面这个语句的含义究竟是什么?
for (i= 0 to 10)
a[i] = 0;
如果10是包括在取值范围内的“入界点”,那么i将取11个值,而不是10个值。如果10是不包括在取值范围内的“出界点”
另一种考虑不对称边界的方式是,把上界视作某序列中第一个被占用的元素,而把下界视作序列中第一个被释放的元素。
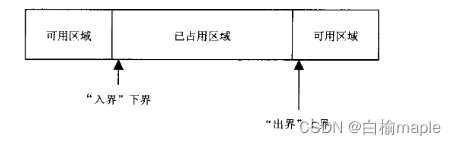
当处理各种不同类型的缓冲区时,这种看待问题的方式就特别有用。这种看待问题的方式就特别有用。将长度无规律的输入数据送到缓冲区(即一块能够容纳N个字符的内存)中去,每当这块内存被“填满”时,就将缓冲区的内容写出。缓冲区的声明可能是下面这个样子:
# define N 1024
static char bufferN
我们再设置一个指针变量,让它指向缓冲区的当前位置:
static char * bufptr;
按照“不对称边界”的惯例,我们可以这样编写语句:
* bufptr++ = c;
这个语句把输入字符c放到缓冲区中,然后指针bufptr 递增1,又指向缓冲区中第1个未占用的字符。
当指针bufptr 与&buffer [0]相等时,缓冲区存放的内容为空,因此初始化时声明缓冲区为空可以这样写:
bufptr= & buffer[0];
或者,更简洁一点,直接写成:
bufptr = buffer;
任何时候缓冲区中已存放的字符数都是bufptr -buffer ,因此我们可以通过将这个表达式与N作比较,来判断缓冲区是否已满。当缓冲区全部“填满”时,表达式bufptr -buffer 就等于N,可以推断缓冲区中未占用的字符数为N-(bufptr -buffer )。
3.编写程序
我们就可以开始编写程序了,假设这个函数的名称是bufwrite 。函数bufwrite 有两个参数,第一个参数是一个指针,指向将要写入缓冲区的第1个字符;第二个参数是一个整数,代表将要写入缓冲区的字符数。假定我们可以调用函数flushbuffer 来把缓冲区中的内容写出,而且函数flushbuffer 会重置指针bufpur ,使其指向缓冲区的起始位置。如下所示:
void
bufwrite( char * p, int n)
{
while( --n> 0) {
if (bufptr = & buffer[N])
flushbuffer();
* bu fptr+ + = *p++;
}
}
重复执行表达式--n>=0只是进行n次迭代的一种方法。
我们注意到前面出现了bufptr 与&buffer [N]的比较,而buffer [N]这个元素是不存在的,数组buffer 的元素下标从0到N-1,根本不可能是N。我们用这种写法:
if (bufptr = & buffer[N)
代替了下面等效的写法:
if (bufptr & buffer[ N 1]>
原因在于我们要坚持遵循“不对称边界”的原则:比较指针bufptr 与缓冲区后第一个字符的地址,而&buffer [N]正是这个地址。
我们并不需要引用这个元素,而只需要引用这个元素的地址,
ANSIC标准明确允许这种用法:数组中实际不存在的“溢界”元素的地址位于数组所占内存之后,这个地址可以用于进行赋值和比较。
4.移动字符
假定我们有一种方法能够一次移动k个字符。即使你的C语言实现没有提供这个函数,自己写一个也很容易:
void
memcpy( char * dest ,const *char source, int k
{
while( --k >= 0)
* dest++=*source++;
}
我们现在可以让函数bufwrite 利用库函数memcpy 来一次转移一批字符到缓冲区,而不是一次仅转移一个字符。
循环中的每次迭代在必要时会刷新缓存,计算需要移动的字符数,移动这些字符,最后恰当地更新计数器。如下所示:
void
bufwrite( char * p, int n)
{
while( n > 0) {
int k, rem;
if (bufptr == & buffer [ N] )
flushbuffer();
rem = N - ( bufptr - buffer);
k = n > rem? rem: n ;
memcpy (bufptr ,p,k);
bufptr += k;
p += k;
n -= k;
}
}
在循环的入口处,n是需要转移到缓冲区的字符数。因此,只要n还大于0,
上面的代码中,最后四行语句管理着字符转移的过程:
(1)从缓冲区中第1个未占用字符开始,复制k个字符到其中;
(2)将指针bufptr 指向的地址前移k个字符,使其仍然指向缓冲区中第1个未占用字符
(3)输入字符串的指针p前移k个字符;
(4)将n(即待转移的字符数)减去k
5.打印元素
打印当前输入数值(即当前行的最后一个元素),打印换行符以结束当前行,如果是一页的最后一行还要另起新的一页:
printnum(n); /打印当前行的最后一个元素*/
printr1(); /另起新的一行*/
if = (++ row NROWS) {
printpage ();
row = 0 ; /*重置当前行号*/
bufptr =buffer ; /*重置指针bufptr */
}
因此,最后的print 函数看上去就像这样:
void
print( int n )
{
if (bufptr = & buffer [ BUFSIZE] ) {
static int row = 0;
int * p;
for (p = buffer+ row; p < bufptr);
p += NRONS)
printnum(*p);
printnum(n); /*打印当前行的最后一个元素*/
printnl(); /*另起新的一行*/
if (++ row = NROWS) {
printpage();
row = 0 /*重置当前行序号*/
bufptr =buffer ;/*重置指针bufptr */
}
else
* butptr++ = n;
}
只需要编写函数flush ,它的作用是打印缓冲区中所有剩余元素,只需要将其作为内循环,在其上另外套一个外循环(作用是遍历一页中的每一行)
void
flush()
{
int row;
for (row = 0; row NROWS; row++) {
int * p:
for (p = buffer row; p = bufptr;
p += NRONS)
printnum(*p);
printnl ();
}
printpage();
}
事实上,即使最后一页为空,函数flush 仍然还会全部打印出来,只不过一页全是空白而已。为了代码更加简洁,可以改为:
void
flush()
(
int row
int k = bufptr -buffer ; /*计算缓冲区中剩余项的数目*/
if (K >NROWS)
K = NROWS;
if(k>0){
for (row = 0; row < k; row++) {
int * p;
for (p = buffer + row; p< bufptr:
p += NROWS )
printnum(*p);
printnl();
}
printpage();
}
)
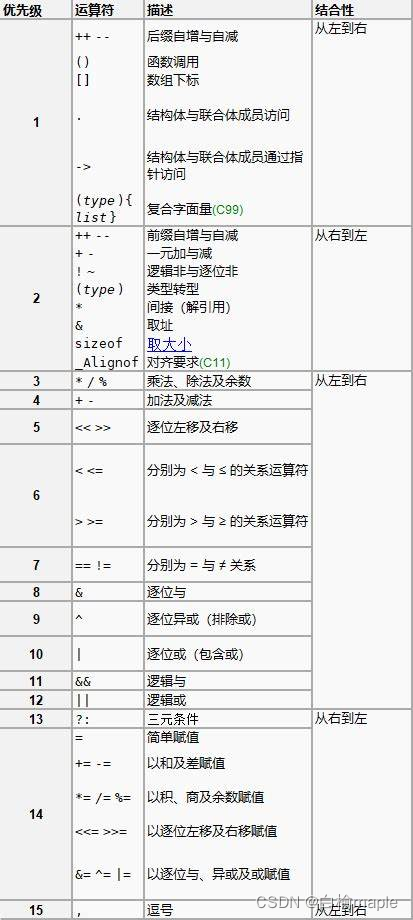
二、求值顺序
运算符优先级是关于诸如表达式
a + b * c
应该被解释成
a + ( b * c)
而不是
(a+b) * c
可以保证像下面的语句
if (count != 0 && sum/ count smallaverage)
printf("average < %g\ n" , smallaverage);
即使当变量count 为0时,也不会产生一个“用0作除数”的错误。
例如,考虑下面的表达式:
a < b && c < d
C语言的定义中说明a<b应当首先被求值。如果a确实小于b,此时必须进一步对c<d求值,以确定整个表达式的值。但是,如果a大于或等于b,则无需对c<d求值,表达式肯定为假。
另外,要对a<b求值,编译器可能先对a求值,也可能先对b求值,在某些机器上甚至有可能对它们同时并行求值。
C语言中只有四个运算符(&&、、?:和,)存在规定的求值顺序。运算符&&和运算符首先对左侧操作数求值,只在需要时才对右侧操作数求值。运算符?有三个操作数:在a?b:c中,操作数a首先被求值,根据a的值再求操作数b或c的值。而逗号运算符,首先对左侧操作数求值,然后该值被“丢弃”,再对右侧操作数求值。
C语言中其他所有运算符对其操作数求值的顺序是未定义的。特别地,赋值运算符并不保证任何求值顺序。
运算符&&和运算符对于保证检查操作按照正确的顺序执行至关重要。例如,在语句
if (y != 0 && x/ y > tolerance)
complain ();
中,就必须保证仅当y非0时才对xy求值。
i = 0;
while (i < n)
y[i] = x[i++];
上面的代码假设y[i]的地址将在i的自增操作执行之前被求值,这一点并没有任何保证!
下面这种版本的写法与前类似,也不正确:
i=0;
while( i < n)
y[i++]=x[i]:
另一方面,下面这种写法却能正确工作:
i = 0;
while (i < n) {
y[i]=x[i];
i++;
}
当然,这种写法可以简写为:
for (i = 0; i < n; i++)
y[i]=x[i];


![<span style='color:red;'>c</span>++ map operator[] <span style='color:red;'>陷阱</span>](https://i-blog.csdnimg.cn/direct/98d7f2220dba413c91193d341454d190.png)