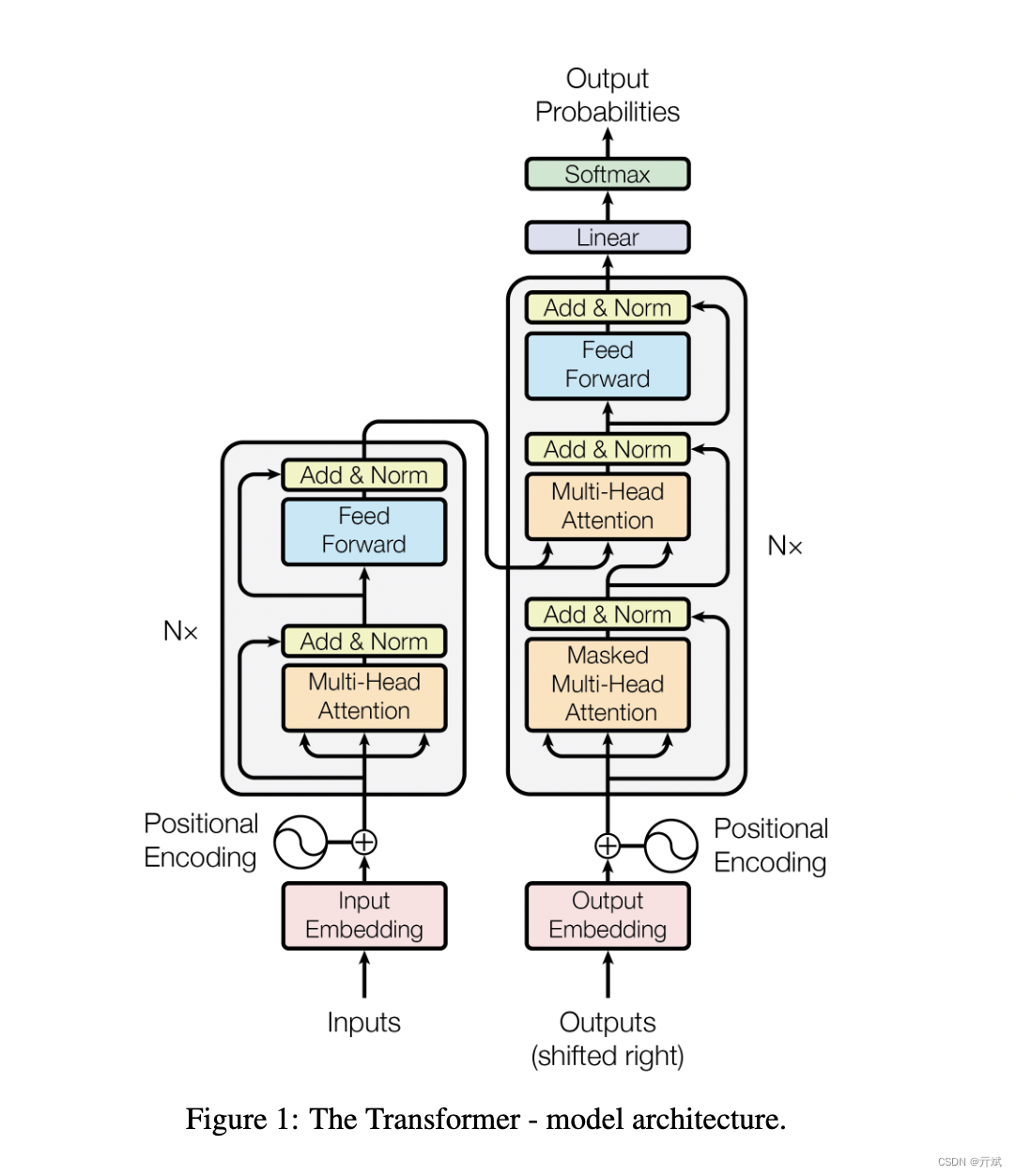
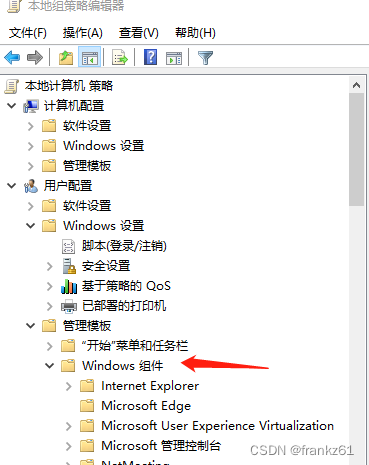
Prompt Engineering |
RAG | 微调 |
从零训练大模型 | |
| 通过提供少量示例提供尽可能多的上下文,使基础模型更好地了解用例 | 增加了直接来自向量化信息存储的特定于用例的上下文 | 在特定领域的数据上更新模型权重 | 模型是在用例特定数据上从零开始训练的 | |
| 准确性 | 与其他方法相比,它产生的结果最不准确 | 与Prompt Engineering相比,它产生的结果大大改善,而且产生幻觉的可能性非常低 | 也提供了相当精确的结果,输出的质量与RAG相当 | 产生幻觉的几率几乎为零,输出的准确率也是比较中最高的 |
实现的复杂性 |
相当低的实现复杂性 | 比Prompt Engineering具有更高的复杂性 | 更复杂 | 最高的实现复杂性 |
工作量投入 |
需要大量的迭代努力才能做到正确 基础模型对提示的措辞非常敏感,改变一个词甚至一个动词有时会产生完全不同的反应 |
由于涉及到创建嵌入和设置矢量存储的任务,RAG也需要很多的工作量,比Prompt Engineering要高一些 | 微调则比前两个要更加费力。 虽然微调可以用很少的数据完成(在某些情况下甚至大约或少于30个示例),但是设置微调并获得正确的可调参数值需要时间 |
从头开始训练是所有方法中最费力的方法。 它需要大量的迭代开发来获得具有正确技术和业务结果的最佳模型。 这个过程从收集和管理数据开始,设计模型体系结构,并使用不同的建模方法进行实验,以获得特定用例的最佳模型。 这个过程可能会很长(几周到几个月) |
| 灵活性 | 非常高的灵活性,因为只需要根据基础模型和用例的变化更改提示模板 | 很最高程度的灵活性 可以独立地更改嵌入模型、向量存储和LLM,而对其他组件的影响最小 |
灵活性非常低 因为数据和输入的任何更改都需要另一个微调周期,这可能非常复杂且耗时 |
灵活性最低的 |
- 总结:
- 准确性(低——>高):Prompt Engineering<RAG ≈微调<从零训练大模型
- 实现复杂性(低——>高):Prompt Engineering<RAG <微调<从零训练大模型
- 工作量投入(少——>多):Prompt Engineering<RAG <微调<从零训练大模型
- 灵活性(少——>多):从零训练大模型<微调<Prompt Engineering<RAG



![AGI 之 【Hugging Face】 的【<span style='color:red;'>从</span><span style='color:red;'>零</span><span style='color:red;'>训练</span>Transformer<span style='color:red;'>模型</span>】之二 [ <span style='color:red;'>从</span><span style='color:red;'>零</span><span style='color:red;'>训练</span>一个<span style='color:red;'>模型</span> ] 的简单整理](https://i-blog.csdnimg.cn/direct/c4be01b373154c6bb37f14f5cf550812.png)