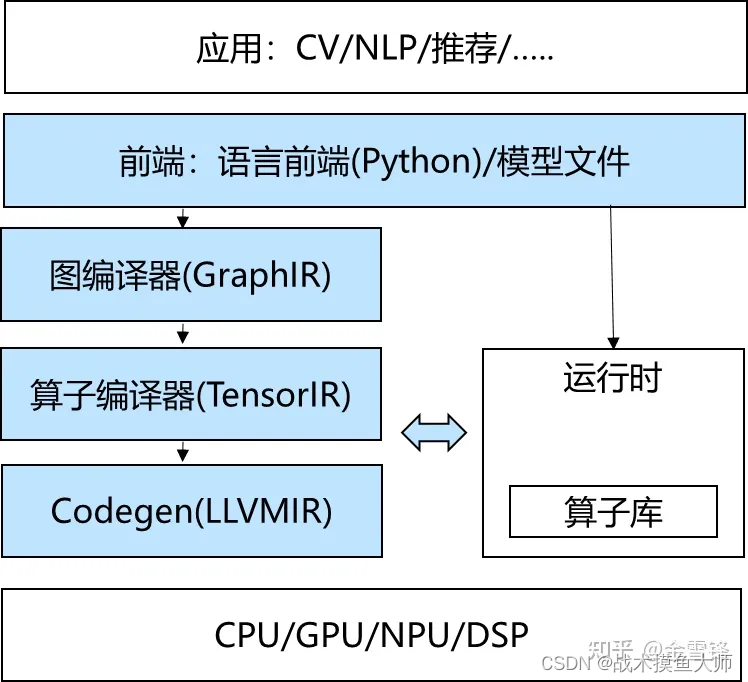
一、写作动机:
最近的一项研究,LIMA,表明仅使用1K个示例进行SFT也可以实现显著的对齐性能,这表明对齐微调的效果可能是“表面的”。(知识和推理能力来源于预训练,而不是必须通过对齐微调获得的。)这引发了对对齐调整如何确切地转变基础LLM的问题。作者通过检查基础LLMs及其对齐的对应版本之间的token分布变化(例如,Llama-2和Llama2-chat),来分析对齐微调的效果。结果显示,基础LLMs及其对齐微调版本在大多数token位置的解码上表现几乎相同(即,它们共享排名靠前的token)。大多数分布变化发生在风格token(例如,话语token、安全声明)上。这些直接证据强烈支持对齐微调主要学习采用AI助手的语言风格的假设,并且用于回答用户查询的知识主要来自基础LLMs本身。基于这些发现,我们通过提出研究问题重新思考LLMs的对齐:我们可以多大程度地在没有SFT或RLHF的情况下对齐基础LLMs?
二、主要贡献:
作者介绍了一种简单的、不需要微调的对齐方法,URIAL(未调整的LLMs与重新风格化的上下文对齐)。URIAL纯粹通过基础LLMs的上下文学习(ICL)实现有效的对齐,只需要三个恒定的风格示例和一个系统提示。作者对各种示例进行了细致且可解释的评估,命名为just-eval-instruct。结果表明,具有URIAL的基础LLMs可以与通过SFT(Mistral-7b-Instruct)或SFT+RLHF(Llama-2-70b-chat)对齐的LLMs的性能相匹配甚至超越。
三、解密通过Token分布偏移的对齐:
对于给定的用户查询q = {q1, q2, · · · },将其输入到对齐模型g(x)中,通过贪婪解码获得其输出o = {o1, o2, · · · }。对于每个位置t,在该位置定义一个“上下文”为xt = q + {o1, · · · , ot−1}。将对齐模型在预测该位置的下一个标记时的概率分布定义为Palign,其中ot具有最高概率。作者的分析驱动了一个问题:如果从对齐模型g切换到基础模型f以解码此位置的下一个标记,会发生什么?
在整个标记词汇表上分析两个分布之间的差异是具有挑战性的,特别是在解码时启用抽样时。如下图所示,使用贪婪解码的对齐模型g首先用于生成完整输出o。对于每个位置t,根据基础模型f预测的概率Pbase对标记进行排序。ot在此排序列表中的排名被定义为“基础排名”,表示为η。这导致了三种类型的位置:(1)未偏移的位置(η = 1):ot在Pbase和Palign中都是排名最高的标记,具有最高概率;(2)边缘位置(1 < η ≤ 3):虽然ot在Pbase中不是排名最高的标记,但仍有可能被用于解码,具有第二或第三高的概率。(3) 偏移位置(η > 3):在这种情况下,ot 很可能不会被Pbase抽样,这表明了从Pbase到Palign的显著分布偏移。

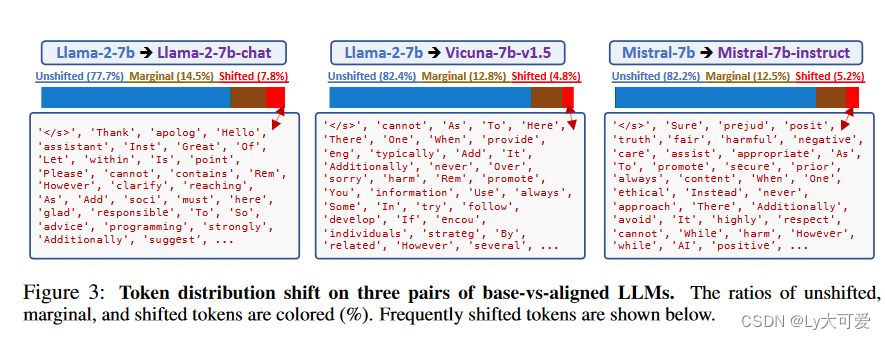

对于对齐微调的总结:
- 对齐只影响了很小一部分token;在大多数位置上,基础和对齐的LLMs在解码时的行为相同,它们共享相同的排名最高的token。
- 对齐主要涉及风格token,例如话语token、过渡词和安全声明,这些token仅占总token位置的很小一部分。
- 对齐对于较早的token更为关键。对于大多数位置,对齐模型的排名最高的token在基础模型排名前五的token内。
- 基础LLMs已经获得了足够的知识来遵循指令。当给定适当的上下文作为前缀时,它们的行为与对齐的LLMs非常相似。
四、URIAL方法:
由两部分组成:ICL示例的风格化输出和用于上下文对齐的系统提示。(URIAL使用尽可能少的K=3个恒定上下文示例)

五、实验:
5.1、数据集和模型:
合并了五个现有数据集:(1) AlpacaEval2 (Li等人,2023a),(2) MT-Bench (Zheng等人,2023),(3) LIMA (Zhou等人,2023),(4) HH-RLHF-redteam (Ganguli等人,2022)和(5) MaliciousInstruct (Huang等人,2023)。控制了大小,以确保评估是可承受的,同时保持任务和主题的多样性,以进行全面分析。最终,创建了一个包含1,000个示例的集合,我们称之为just-eval-instruct。来自前三个子集的800个示例专注于评估LLMs的帮助性,来自最后两个子集的200个示例针对测试LLMs的无害性的红队指令。

选取了三个主要的基础LLMs进行实验:Llama-2-7b、Llama-2-70bq (通过GPTQ进行4位量化 (Frantar等人,2022)) 和 Mistral-7b (v0.1) (Jiang等人,2023a)。请注意,这三个LLMs没有使用任何指令数据或人类偏好数据进行微调。
四个构建在这些基础模型上的对齐模型:它们是Vicuna-7b (v1.5)、Llama-2-7b-chatq、Llama-2-70b-chat和Mistral-7b-Instruct。除了这些开源LLMs,还包括了OpenAI GPTs的结果(即gpt-3.5-turbo和gpt-4)。
5.2、评估:
提出了一个关于以下六个方面的多方面、可解释的评估协议:有帮助性,清晰度,事实性,深度,参与度和安全性,开发了基于评分的模板,以促使OpenAI GPTs在每个描述的方面上评估LLM输出,以及对其评估的理由。使用GPT-4来评估800个常规指令,以评估前五个方面,而使用ChatGPT来评估200个有关安全方面的红队测试和恶意指令。在每个方面上,将得到一个从1到5的分数,表示‘强烈不同意’,‘不同意’,‘中立’,‘同意’和‘强烈同意’。
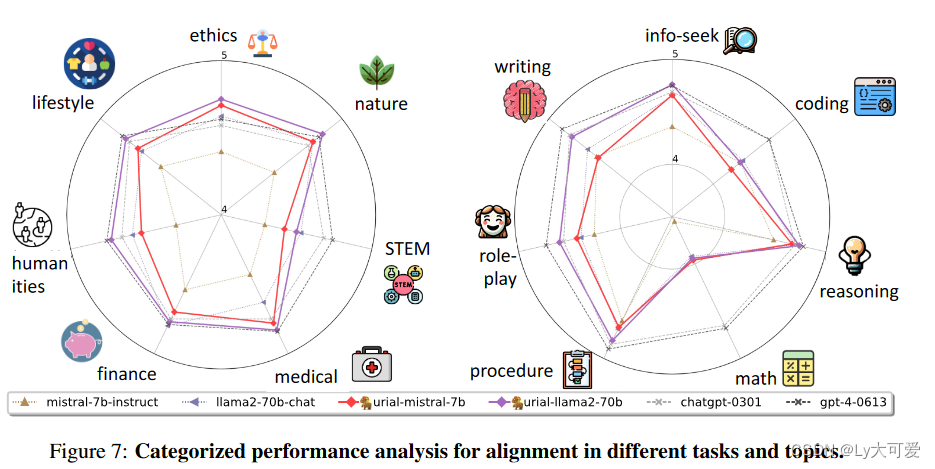
5.3实验结果: