目录
前言
今天我们来学习Hadoop完全分布式的搭建,我们要搭建hadoop完全分布式要掌握哪些东西呢?
首先需要掌握的就是Hadoop的基础知识,了解Hadoop的生态系统,包括Hadoop的核心组件(如HDFS、MapReduce、YARN等)以及其他相关组件(如HBase、Hive、Zookeeper等)。理解这些组件的功能和相互作用对于搭建和管理Hadoop集群至关重要。因为Hadoop通常在Linux操作系统上运行,因此需要对Linux有一定的了解,包括基本的命令行操作、系统管理和网络配置等。再者Hadoop是用Java编写的,因此需要对Java编程语言有一定的了解,包括Java编程基础、JDK的安装和配置等。还要了解如何规划和搭建Hadoop集群,包括选择合适的硬件和软件、配置网络、安装和配置Hadoop等。此外,还需要了解如何管理和维护Hadoop集群,包括监控集群状态、处理故障、优化性能等。熟悉Hadoop的配置文件(如core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等),了解如何配置和优化Hadoop集群以满足不同的业务需求。熟悉Hadoop的配置文件(如core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等),了解如何配置和优化Hadoop集群以满足不同的业务需求。了解如何保障Hadoop集群的安全性和可靠性,包括设置访问控制、数据加密、备份和恢复等。
当我们大概了解了这些以后,就可以开始我们的搭建过程
搭建
准备
首先我们的Hadoop完全分布式,是搭建在Linux系统上的,所以我们需要在Linux服务系统上准备三个节点,这里大家自行准备,我准备的是
- bigdata1
- bigdata2
- bigdata3
有了节点以后,我们还需要做一下集群规划
| 节点 | NameNode | DataNode | SecondNameNode |
| bigdata1 | √ | √ | |
| bigdata2 | √ | √ | |
| bigdata3 | √ |
上述表格就是我们的集群规划,采用1NameNode、3DataNode的方式去搭建我们的Hadoop分布式集群
配置JAVA环境
搭建Hadoop先配置支撑它的语言,要不则会寸步难行,这里选择的是jdk1.8.0版本
首先先把压缩包拉取到bigdata1节点的/opt/software目录下(没有的自行创建)
然后运行命令解压压缩包到/opt/module目录下(没有的自行创建)
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar .gz -C /opt/module首先 tar是Linux 系统上的一个用于处理归档文件的工具,-zxvf分别代表
z: 使用 gzip 进行解压。这告诉tar命令,归档文件是用 gzip 压缩的,所以需要先进行 gzip 解压。x: 解压。这告诉tar命令要解压归档文件。v: 详细模式(verbose)。这会在解压过程中显示正在解压的文件名,使得用户可以看到解压的进度。f: 文件。这告诉tar命令后面会跟一个文件名,而不是从标准输入或输出中读取/写入。
解压缩完文件以后,还要配置JAVA环境才可以正常使用,所有环境我们都配在/etc/profile.d/目录下的my_env.sh文件下,这里不推荐在/etc/目录下的profile文件,因为一旦profile文件受损,节点就会宕机,所以建议配置在自建文件my_env.sh上
vim /etc/profile.d/bigdata_env.sh在my_env.sh文件上添加内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin保存退出以后,运行命令,刷新环境变量使其生效
source /etc/profile运行命令,验证是否配置成功,如果没有报错,则为成功
java -version
javac
搭建Hadoop集群
与配置JAVA环境一样,我们需要先解压压缩包
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/然后我们配置hadoop的运行环境
vim /etc/profile.d/bigdata_env.sh#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin然后使用source刷新环境变量文件,运行命令验证是否成功
hadoop version接下来就是配置hadoop分布式最重要的部分了,配置文件
cd /opt/module/hadoop-3.1.3/etc/hadoop/Hadoop-env.sh 文件
hadoop-env.sh 是 Hadoop 分布式文件系统 (HDFS) 和其他 Hadoop 组件的一个重要配置文件,这个文件主要用于设置 Hadoop 运行环境的一些重要参数,比如 Java 运行环境(JRE)的路径、Hadoop 的 PID(进程 ID)文件存放位置等。
然后修改Hadoop-env.sh文件,添加内容
export JAVA_HOME=/opt/module/jdk1.8.0_212核心配置文件 —— core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>HDFS 配置文件 —— hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata1:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata3:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>YARN 配置文件 —— yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata2</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>MapReduce 配置文件 —— mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata1:19888</value>
</property>
</configuration>配置 workers/slaves 文件
bigdata1
bigdata2
bigdata3在/etc/profile.d/bigdata_env.sh 文件末尾田间
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
这是保证在HDFS上可以畅通无阻,生产活动的时候不建议这样,因为root用户是权限最大的用户
分发
配置分发工具:(参考尚硅谷)
进入/usr/bin目录下,创建文件xsync,
#!/bin/bash
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
for host in bigdata1 bigdata2 bigdata3
do
echo ==================== $host ====================
for file in $@
do
if [ -e $file ]
then
pdir=$(cd -P $(dirname $file); pwd)
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done给xsync添加可执行的权限
chmod 777 /usr/bin/xsync
然后直接分发想分发的文件就可以了
xsync /opt/module/
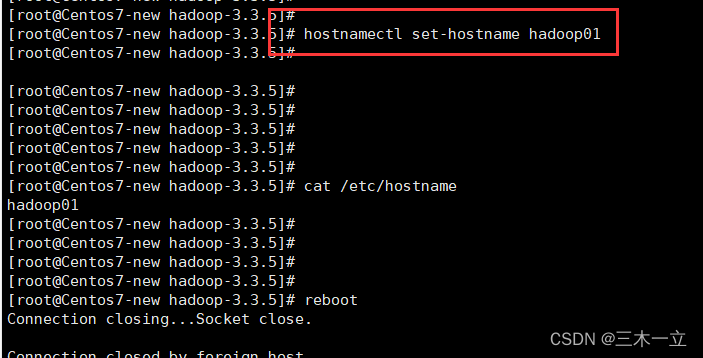
xsync /etc/profile第一启动hadoop集群需要先格式化,在bigdata1下运行
hdfs namenode -format
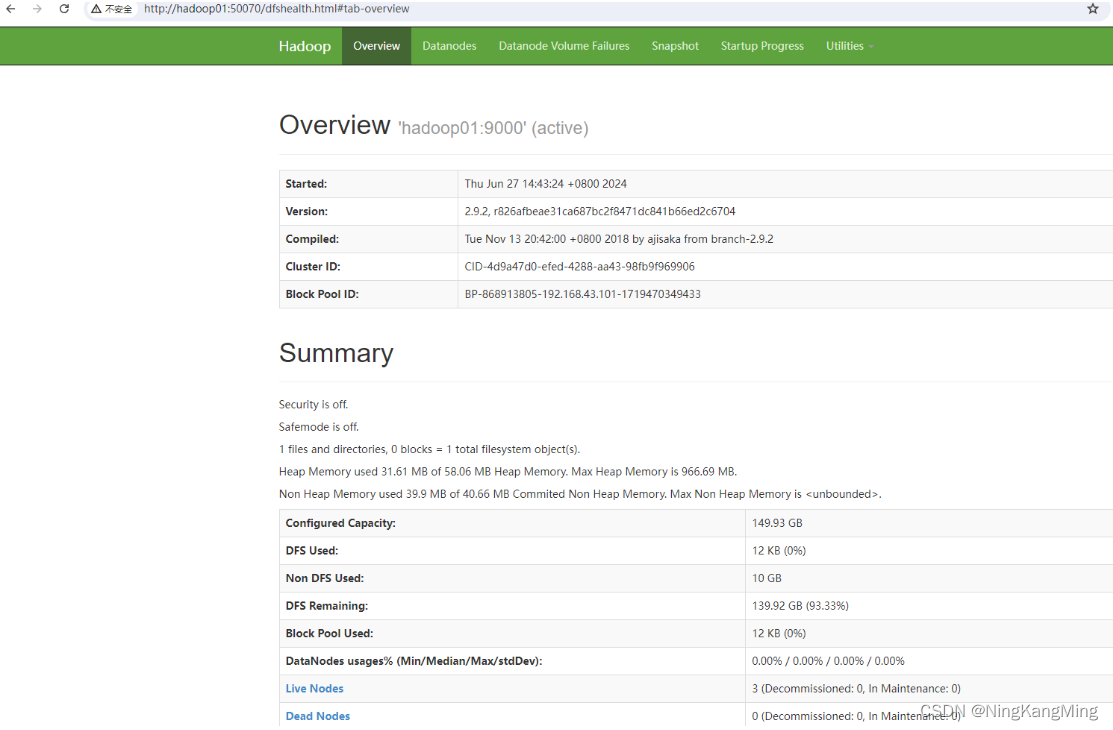
然后再bigdata1中,运行start-all.sh;再进入bigdata2,运行start-yarn.sh
和集群规划如果一致那么说明配置成功