本质就是一个hadoop的客户端,将HIve SQL转化成MapReduce程序
一、企业级调优
这部分主要用在实际工作中和面试中
1、主要分为计算资源调优 & 执行计划调优
计算资源调优就是yarn资源的配置,和mapreduce的资源配置,分给多少内存,核数之类的
-- 具体可以看讲义第94-95页
而执行计划是什么呢?
!!!!!!!!!!!!!!!!!!执行计划很重要!!!!!!!!!!!!!!!!!!!!!!!!!!!!
一个sql语句翻译成几个mapreduce ,map和reduce分别干了什么,就是执行计划讲解的
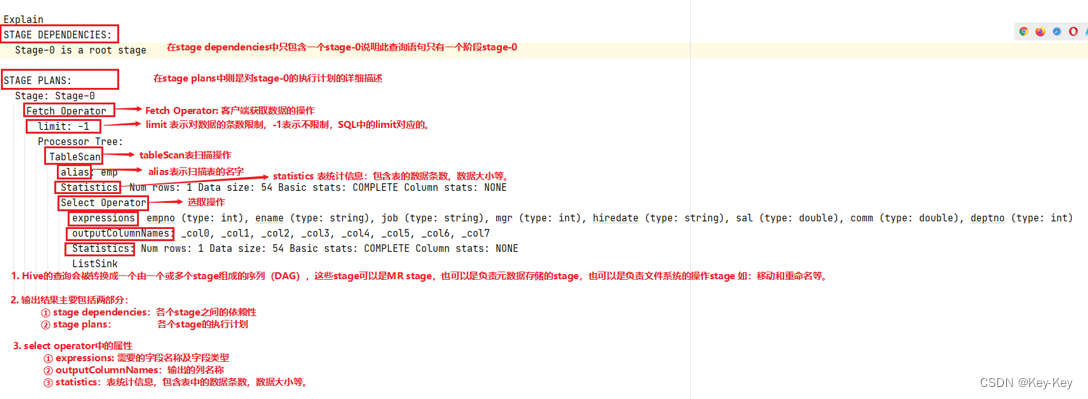
这个是通过在select语句最外面加上explain关键字,就会显示出来详细的执行计划
而执行计划是由一系列的stage,就是一页一页的构成,每一个stage对应一个mapreduce job 或者一个文件操作系统,比如load之类的
-- 具体的其中执行计划讲解可以看讲义的第98-100页
注意语法中,expalin后面可以跟三个参数
另外详细看一下99页中各个operator的含义
0- 补充一个可视化执行计划方法
在hive文件夹中有一个压缩包名为dist,是可以用于可视化hive sql中的执行计划
在任意一台节点中上传这个压缩包,然后进入dist
输入python -m SimpleHTTPServer 8900
就可以去hadoop104:8900中使用这个可视化web页面。将sql中explain出来的执行计划粘贴到那个web页面即可
但是这个执行计划,是需要json格式的,所以我们使用sql语句的时候,应该加上参数formatted
explain formatted 巴拉巴拉
2、Map端聚合优化
Hive对分组聚合的优化主要是围绕减少Shuffle数据量进行
具体做法是,不是按照之前原理在shufflez中使用combiner进行合并相同字段到同一个reduce中。相当于先在map端进行了一部分聚合
这里使用的是map-side聚合。
- 在map端维护一个hash table,使用到了内存。利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
默认是打开这个map-side聚合的
-- 可以在讲义中看第101页中的聚合相关参数
3、join 调优
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等
主要介绍这四种的join算法,在数据量比较大的情况下进行join,如何让适合的算法生效以减少计算时间提高效率,在不同的join场景下适合什么样的join算法,以及怎么触发使用具体的算法
简单描述一下区分和联系:
从map join开始就是不使用reduce和shuffle,但是Map Join,Bucket Map Join借助内存存储表信息或者桶的数据,Sort Merge Buckt Map Join没有使用内存,也没有构建hash table
并且后三种算法除了Bucket Map Join都是有两种触发方式:sql语句中增加hint提示、自动触发
【Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为其他算法任务,若满足要求,便将Common Join任务自动转换为Map Join任务等】
- map join 默认就是自动触发
- Bucket Map Join不支持自动转换,需要sql中提供hint提示
- Sort Merge Buckt Map Join,可以设置参数进行设置自动转换【触发】
3.1、Common Join
平常如果两个表进行join,只有一个字段,那么就只会有一个一个mapreduce,或者三个表相连接的字段相同,那也只是一个mapreduce,如果是多个表的连接字段不同,那么就是多个mapreduce工作任务
其实Common Join就是完成一个mapreduce job。默认使用的就是这种join算法
-- 具体可以看讲义的第104页
3.2、Map Join
核心要求:借助内存,没有recuce 和 shuffle阶段
适用场景:大表 join 小表
-- 具体可以看讲义的第105页
若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作
触发算法 》》》 参数优化
map join的执行计划是重点分析掌握的
小表也需要一个单独的map task,就是一个mapreduce,只不过不需要reduce和shuffle。所以在执行计划中是一个stage
但是它是执行的本地计划,相当于没有占用yarn
-- 具体看讲义的第107-116页
-- 去看他是怎么自动从common join转换成map join
讲义的第109页中的执行逻辑是针对一个common task,也就是一个mapreduce的,这个里面可能有很多个map和reduce task,但都是算作一个mapreduce job,也就是一个common task
如何才算做可以确定表的大小呢?只要编译阶段的时候这个表是实际存在,不是子查询这种虚拟表就可以
知道表的大小后,就可以判断它能不能被当作小表。具体的判断思路以及其流程在109页,不是单纯的找到一个小表即可,其算法思路考虑到了很多情况。所以设计了一个条件任务,里面就是所有可能实现map join的情况,因为小表既可能是a表,也可能是b表,另外还会有一个后备计划,就是我们所罗列的所以计划都不能实现,这些情况都不能实现map join,那最后还是执行common join。在条件任务里面还会最先筛除一些绝对不可能实现map join的情况
另外,还会有一个最优的map join计划,就是比如多表合并,就会出现a和b表先合并出来一个虚拟表m,然后m表再去和c表合并,这相当于是两个common task,如果就算其符合map join的条件。其中一个可以当作小表,那也比较复杂。但是如果a被当作大表[这个在最开始的流程中就被判断了,寻找大表候选人那一步骤,根据的是sql的join方式],那么去判断b和c表的大小已知嘛,如果已知,并且文件大小的和小于我们设置的小表阈值,那么我们就可以将b和c缓存到一起,最后这三个表放在一个map join中,也就是相当于只有一个common task
最后还需要提一下我们设置参数的时候
会设置那个小表的阈值,有两个这样的参数,其实含义一样,都是小表阈值,只不过位置不同名字就不一样了,这个阈值就是判断文件的大小
但是不能乱设置。因为实际是文件存放到内存中,而这个只是文件大小。我们将文件缓存到内存中,其实经过反序列化等一系列操作。所以实际存放在内存中的大小,要比文件大小大,基本上是10倍的文件大小。所以如果我们文件大小阈值设置成100m,基本消耗的内存是1G
这个要依据一个map task能分多少内存来设置,一般最多设置成hive-site中这个set mapreduce.map.memory.mb=2048;的二分之一到三分之二,这个参数的含义是单个Map Task申请的container容器内存大小,其默认值为1024
3.3、Bucket Map Join
核心要求:还是借助内存,在map join的基础上,借助分桶表,关联字段需要是分桶字段,且一张表的分桶数量是另外一张表分桶数量的整数倍。这时一个桶对应一个hash表
适用场景:大表 join 大表也可以用
-- 在讲义第105页
参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。
触发算法 》》》 参数优化
-- 具体见讲义的第117-121页
若采用普通的Map Join算法,则Map端需要较多的内存来缓存数据,当然可以选择为Map段分配更多的内存,来保证任务运行成功。但是,Map端的内存不可能无上限的分配,所以当参与Join的表数据量均过大时,就可以考虑采用Bucket Map Join算法。
比较大的表还想要用内存,我们可以对其分桶,相当于可以把一个比较大的文件分成好几个小文件,比如300M的文件我们分成6个桶,每个桶50M,才占用50 * 10 = 500的内存,还可以接受
3.4、Sort Merge Buckt Map Join
核心要求:不需要借助内存,在Bucket map join的基础上,分桶表需要是分桶排序表,关联字段需要是分桶字段和排序字段,且都一致,且一张表的分桶数量是另外一张表分桶数量的整数倍。且map端无需对整个桶进行构建hash表
适用场景:什么样的表都可以用,只要是分桶表
-- 在讲义的第106-107页
同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
触发算法 》》》 参数优化
-- 具体看讲义的第122-124页
4、数据倾斜优化
-- 主要见讲义的第125页
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
-- Hive中的数据倾斜常出现在:分组聚合、join操作的两个场景中
4.1、分组聚合导致的数据倾斜
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
有两种解决思路:
-- 见讲义的第125-128页
map-side聚合:
- 这个在之前学习过,是借助内存,在map阶段创建了hash-table,完成初步聚合,再往reduce传输的数据哪怕map很多,但是每个map的数据不会有很多重复key值的字段数据传到同一个reduce了
- 通过**set hive.map.aggr=true;**打开
Skew-Groupby优化:
- 这种不需要借助内存,不需要创建hash table,但是需要进行两个MR,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。这个比较耗费时间
- 通过**set hive.groupby.skewindata=true;**打开
具体情况具体分析,需要去设置相应的参数,打开优化方法
4.2、join操作导致的数据倾斜
未经优化的join操作,默认是使用common join算法。ap端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
有三种解决思路:
-- 见讲义的第128-135页
map join:
这个可以优化join,我们没有使用reduce,所以不会出现数据倾斜情况
之所以没有用bucket map join,和sortbucket,是因为这俩需要的是分桶表,如果一开始不是分桶表
我们还需要进行insert … select… 将原表插入到分桶表,这里也会发生数据倾斜
Skew join:
这个适用于,一个倾斜一个不倾斜的表,就是一对多,其实大部分表也都是一对多的情况
他这块会启动一个条件任务,如果碰到数据倾斜,会对单独的那个地方重新处理,先存放到hdfs,然后大的数据,也就是倾斜的数据,进行切片,小的那个数据,缓存到内存中,进行map join
默认是关闭的
而且它对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
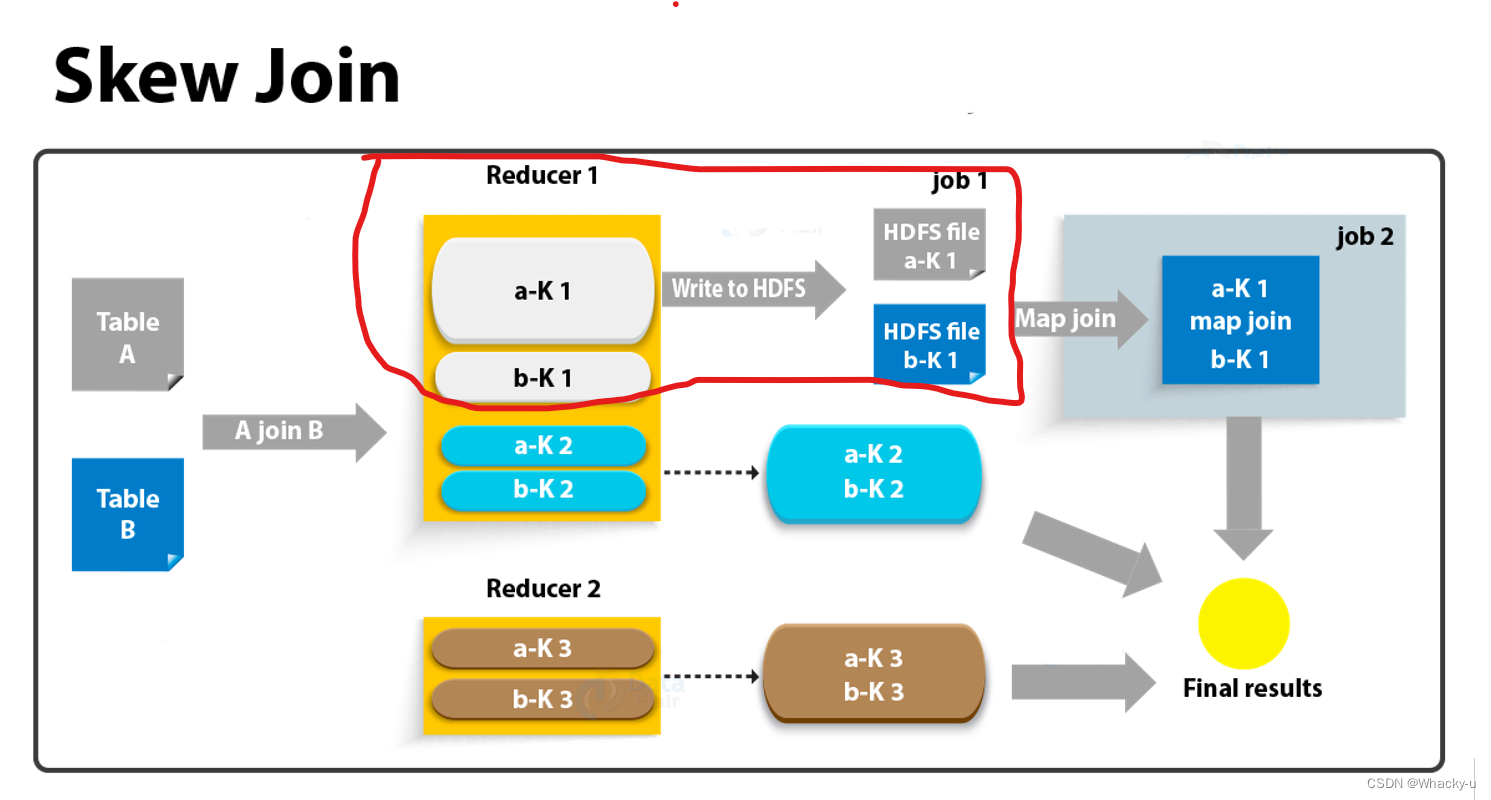
调整SQL语句:
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
-- 可以具体看讲义的前后过程图和笔记讲解,再第130-131页select * from( select -- 打散操作 concat(id,'_',cast(rand()*2 as int)) id, -- 相当于后面跟的不是0 就是1 value from A )ta join( select -- 扩容操作 concat(id,'_',0) id, value from B union all select concat(id,'_',1) id, value from B )tb on ta.id=tb.id;
5、任务并行度
5.1、map端并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。
以下特殊情况可考虑调整map端并行度:
查询的表中存在大量小文件:
默认参数是开的,使用Hive提供的CombineHiveInputFormat,多个小文件合并为一个切片,从而控制map task个数
map端有复杂的查询逻辑:
比如where或者having操作,对应的是map端的过滤操作,在执行计划中也可以看到
在计算资源充足的情况下,可考虑增大map端的并行度,令map task多一些,每个map task计算的数据少一些。
-- 一个切片的最大值 set mapreduce.input.fileinputformat.split.maxsize=256000000; -- 这个可以调小一点,切片就会多,并行度就上去了
5.2、reduce端并行度
Reduce端的并行度,也就是Reduce个数
可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算
【默认是自动估算的】
-- 可以看讲义的第136页。
这个自动估算reduce的并行度个数,其实是有点问题的,只不过mapreduce现在用的比较少了
所以没有继续优化了,但是可以看手写笔记这个为什么有问题
6、小文件合并
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
主要看reduce合并
默认的参数是关闭的
原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并
-- 可以看讲义的第138页
7、其他优化
下面这些优化,就是去看需不需要开关
CBO优化:
默认开启
谓词下推:
默认开启
矢量化查询:
默认开启
不过有些情况没法用,这个hive会自动判断,不是所有数据类型都可以进行矢量查询,这个感兴趣可以去官网看
Fetch抓取
有三种模式,none、minimal、more
本地模式:
需要调参,默认没有开启
并行执行:
默认没有开启。是说不同的stage,即不同的mapreduce job并行工作
严格模式:
通过设置某些参数可以防止危险操作