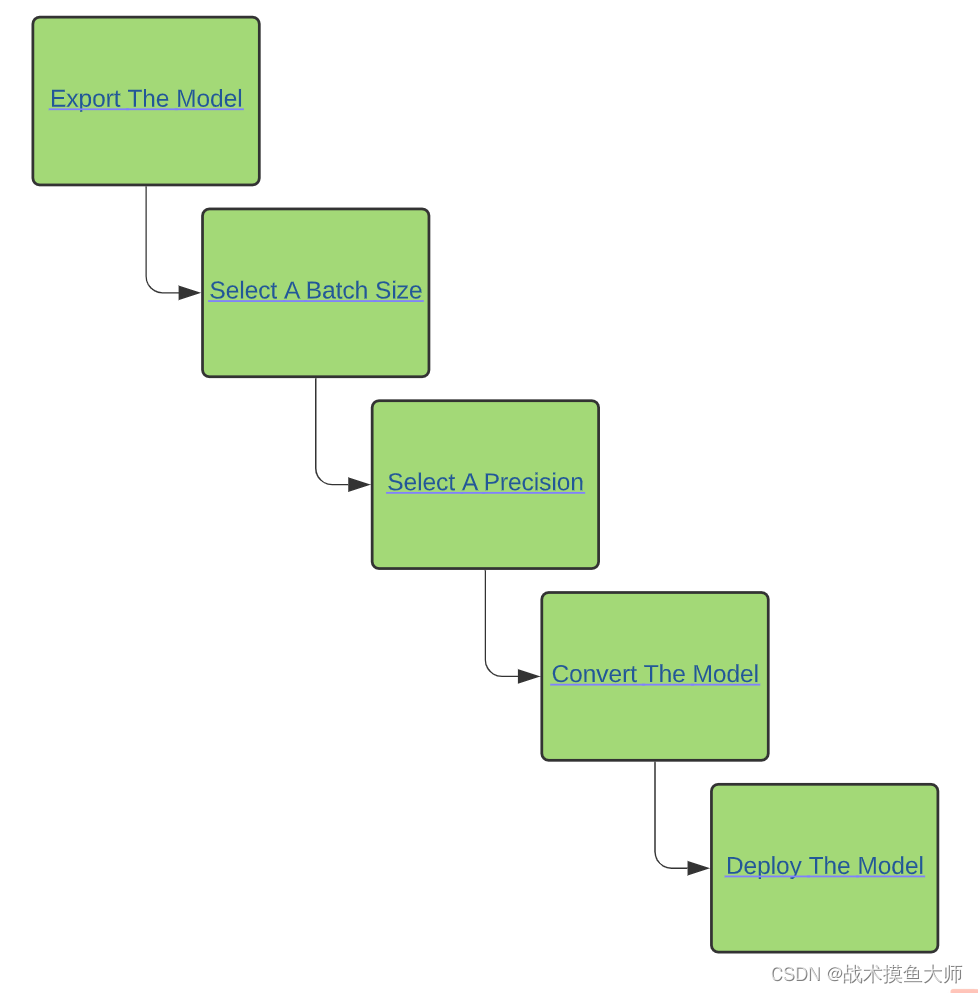
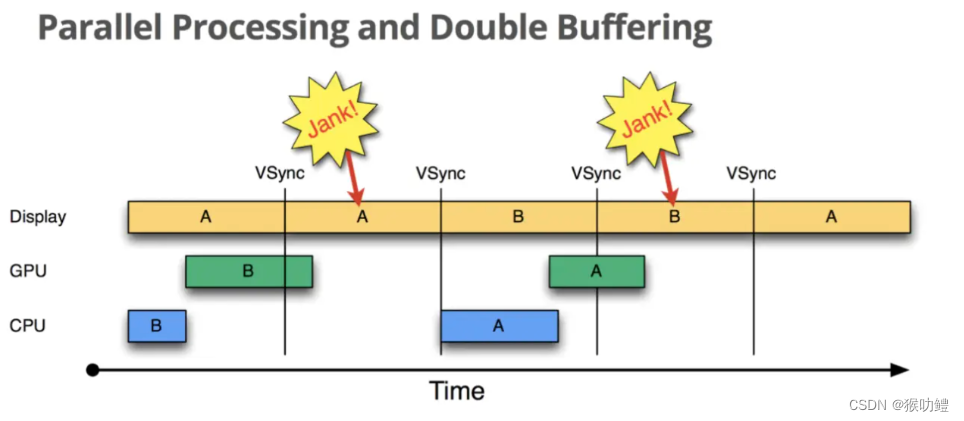
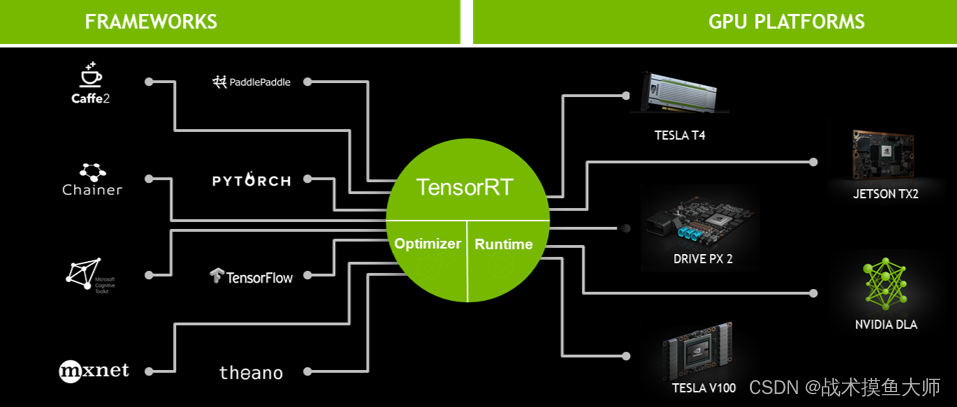
TensorRT的大致流程:

图片来自TensorRT的官方教程
构建期
- 模型解析
- 计算图优化
- 节点消除
- 多精度支持
- 优选kernel:选择最适合当下设备的实现
- 导入plugin:实现自定义操作
- 显存优化:显存池复用
运行期
- 运行时环境:对象生命周期管理,内存显存管理,异常处理
- 序列化反序列化:推理引擎保存为文件或者从文件中加载
具体流程
相关推理配置
需要配置logger,builder,builder_config
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
# autoinit是cuda初始化要用的,必须导入
logger = trt.Logger(trt.Logger.INFO)
# 日志器,等级分为:VERBOSE, INFO, WARNING, ERROR, INTERNAL_ERROR
# VERBOSE和INFO最常用,VERBOSE会输出模型优化的详细信息,INFO只会输出模型的输入输出信息
builder = trt.Builder(logger)
# 网络构建器,仅作为构建网络的工具,不用于设置网络属性
builder_conf = builder.create_builder_config()
# 构建器配置,用于设置构建器的属性,可以设置的有:最大显存,int8量化的校正器,设置推理精度等
TensorRT对于batchsize有两种模式:
- explicit batch模式:显式指定batchsize
- explicit batch模式支持BN层,支持reshape层,支持Loop结构,而implicit batch模式不支持
- implicit batch模式【为了向后兼容而保留的,不推荐使用】
根据输入尺寸的不同,可以分为dynamic shape模式
profile = builder.create_optimization_profile()
profile.set_shape("input", (1, 1, 28, 28), (1, 1, 28, 28), (1, 1, 28, 28))
builder_conf.add_optimization_profile(profile)
# dynameic shape模式下,必须使用explicit batch模式
# dynamic shape模式下,必须使用构建器配置
# dynamic shape模式下,几乎所有的维度都可以是-1,-1表示该维度可以是任意值,除了batch维度
# dynamic shape模式需要使用optimazation profile帮助网络进行优化
# optimization profile可以设置输入张量的常见尺寸,最大尺寸,最小尺寸等
解析模型
三种方式:
- 使用框架自带的TRT接口:Torch-TensorRT,不支持的算子会自动返回训练框架计算
- 使用Parser:导出为onnx,然后TensorRT的parser解析onnx模型,对于不支持的算子需要手写
- TensorRT中有自带的parser类,可以用于解析onnx模型
parser = trt.OnnxParser(network, logger) onnxFile = "/home/wyq/hobby/model_deploy/onnx/onnxruntime/MNIST/mnist.onnx" res = parser.parse_from_file(onnxFile) - 使用TensorRT原生API搭建网络
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
#网络本体,可以设置网络的输入输出,添加层,设置层的属性等
inputTensor = network.add_input(name="input", dtype=trt.float32, shape=(1,1, 28, 28))
identityLayer = network.add_identity(inputTensor)
network.mark_output(identityLayer.get_output(0))
# 添加输入层,添加一个identity层,将输入直接输出,作为输出层
设置推理精度
FP16模式
只要在建立网络的时候添加一个flag就可以指定模型使用fp16模式
builder_conf.flags = 1 << trt.BuilderFlag.FP16
设置为FP16模式后建立engine的时间比fp32模式要更长,更多kernel选择,需要插入reformat节点【数据类型转换节点】
部分层可能精度下降比较大,导致较大误差,需要使用polygraphy等工具找到误差较大的层,强制其使用fp32进行计算。
builder_conf.set_flag(trt.BuilderFlag.OBEY_PRECISION_CONSTRAINTS)
layer.precision = trt.float32
这里个人感觉还可以尝试一下用bf16来进行推理,bf16的精度比fp16高,范围比fp16小
Int8模式
INT8的精度损失比较严重,所以需要有校准集进行校准,通过范例数据来确定量化参数。
校准器需要我们自己进行实现calibrator。
config.set_flag(trt.BuilderFlag.INT8)
config.int8_calibrator = MyCalibrator
支持PTQ和QAT两种量化模式,只要模型中有量化器和解量化器,就会自动启用INT8
生成Engine
生成TRT内部表示
serializedNetwork = builder.build_serialized_network(network, builder_conf)
# 序列化网络,将网络序列化为字节流,可以保存到文件中,也可以用于反序列化
# 保存到网络文件
with open("test.engine", "wb") as f:
f.write(serializedNetwork)
TensorRT生成的Engine包含硬件相关的engine,不能跨平台使用,不同版本的TensorRT生成的engine也不能通用。
想要通用,需要确保硬件环境相同,CUDA/cuDNN/TensorRT环境都相同
相同环境下两次生成的engine也不一定完全一样
生成Engine并进行推理
engine = trt.Runtime(logger).deserialize_cuda_engine(serializedNetwork)
# 反序列化网络,将序列化的网络反序列化为可执行的引擎,可以用于推理
lTensorName = [engine.get_tensor_name(i) for i in range(engine.num_io_tensors)]
print(lTensorName)
# 获取引擎的输入输出名称
context = engine.create_execution_context()
# 创建执行上下文,用于执行推理,可以理解为GPU进程
context.set_input_shape(lTensorName[0], (1, 1, 28, 28))
# 设置输入形状
hInput = np.random.random((1, 1, 28, 28)).astype(np.float32)
# 创建输入数据,host端
dInput = cuda.mem_alloc(hInput.nbytes)
# 分配显存
houtput = np.empty((1, 1, 28, 28), dtype=np.float32)
# 创建输出数据
doutput = cuda.mem_alloc(houtput.nbytes)
# 分配显存
context.set_tensor_address(lTensorName[0], int(dInput))
context.set_tensor_address(lTensorName[1], int(doutput))
# 设置输入输出显存地址
#复制数据从host到device
cuda.memcpy_htod(dInput, hInput)
# 执行推理
context.execute_async_v3(0)
# 复制数据从device到host
cuda.memcpy_dtoh(houtput, doutput)
print(houtput)
![[<span style='color:red;'>深度</span><span style='color:red;'>学习</span>]使用python转换pt并<span style='color:red;'>部署</span>yolov10的<span style='color:red;'>tensorrt</span><span style='color:red;'>模型</span>封装成类几句<span style='color:red;'>完成</span>目标检测加速任务](https://img-blog.csdnimg.cn/direct/be7131e5fc8a455bbaefd995ef494757.png)