Pandas作为数据处理利器,在数据对比与处理方面发挥着重要作用。下面我们将通过实战案例来展示Pandas的强大功能。
一、数据导入与清洗
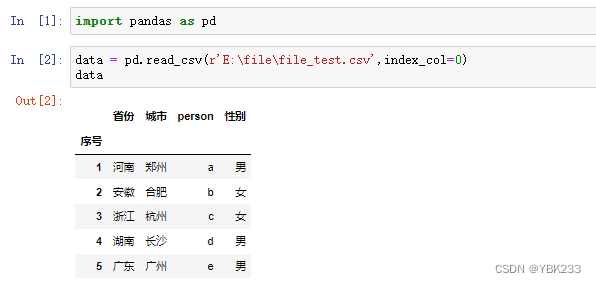
首先,我们需要从数据源导入数据,并进行必要的清洗。Pandas支持多种数据格式,如CSV、Excel、SQL等。以CSV文件为例,我们可以使用Pandas的read_csv函数来读取数据:
python复制代码
import pandas as pd |
|
# 读取CSV文件 |
|
data = pd.read_csv('data.csv') |
|
# 查看数据前5行 |
|
print(data.head()) |
如果数据中存在缺失值或异常值,我们可以使用Pandas的dropna函数和replace函数进行清洗:
python复制代码
# 删除含有缺失值的行 |
|
data = data.dropna() |
|
# 将异常值替换为均值 |
|
data['column_name'].replace(to_replace=value_to_replace, value=mean_value, inplace=True) |
二、数据对比
在数据对比方面,Pandas提供了多种功能强大的方法。例如,我们可以使用compare函数来对比两个DataFrame对象之间的差异:
python复制代码
# 创建两个DataFrame对象 |
|
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) |
|
df2 = pd.DataFrame({'A': [1, 2, 4], 'B': [4, 5, 7]}) |
|
# 对比两个DataFrame对象 |
|
diff = df1.compare(df2) |
|
# 显示差异 |
|
print(diff) |
此外,我们还可以使用merge函数来合并两个DataFrame对象,并进行对比:
python复制代码
# 合并两个DataFrame对象 |
|
merged_df = pd.merge(df1, df2, on='A', suffixes=('_df1', '_df2')) |
|
# 对比合并后的DataFrame对象的特定列 |
|
comparison = merged_df['B_df1'] != merged_df['B_df2'] |
|
# 显示对比结果 |
|
print(comparison) |
三、数据处理与分析
Pandas提供了丰富的数据处理与分析功能,如排序、分组、聚合等。我们可以使用sort_values函数对数据进行排序:
python复制代码
# 按列'A'的值进行升序排序 |
|
sorted_data = data.sort_values(by='A', ascending=True) |
|
# 显示排序后的数据 |
|
print(sorted_data) |
对于分组操作,我们可以使用groupby函数。例如,我们可以按某个列的值对数据进行分组,并对每个组应用聚合函数:
python复制代码
# 按列'group'的值进行分组,并计算每组的平均值 |
|
grouped_data = data.groupby('group').mean() |
|
# 显示分组后的数据 |
|
print(grouped_data) |
此外,Pandas还支持数据可视化,我们可以结合Matplotlib等库进行数据可视化分析。
总结来说,Pandas在数据对比与处理方面具有强大的功能,通过实战案例我们可以看到它在实际应用中的重要作用。无论是数据清洗、对比还是处理与分析,Pandas都能提供高效、便捷的解决方案。掌握Pandas的使用技巧,将使我们在数据处理与分析领域更具竞争力。