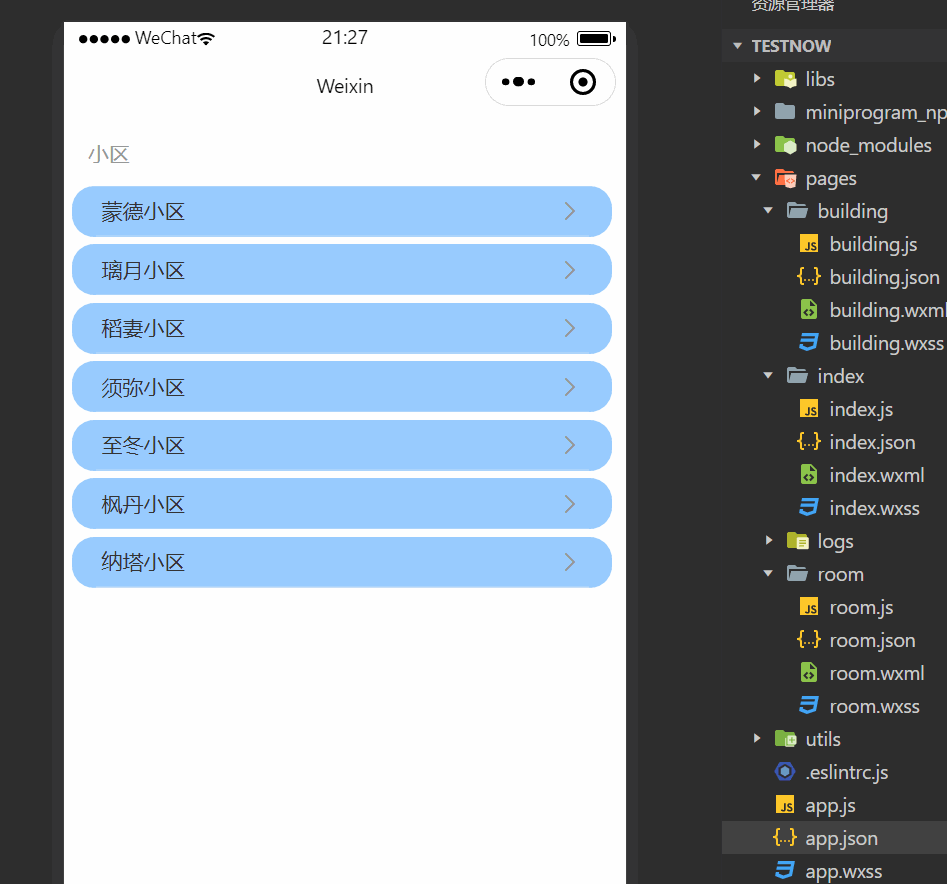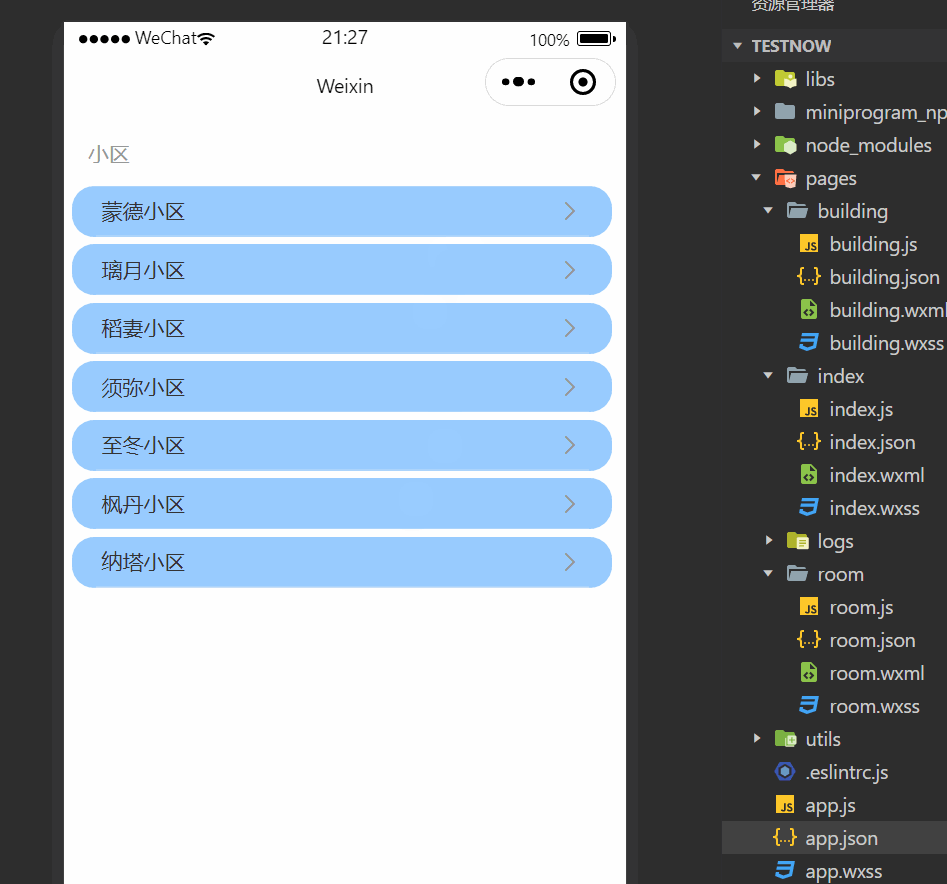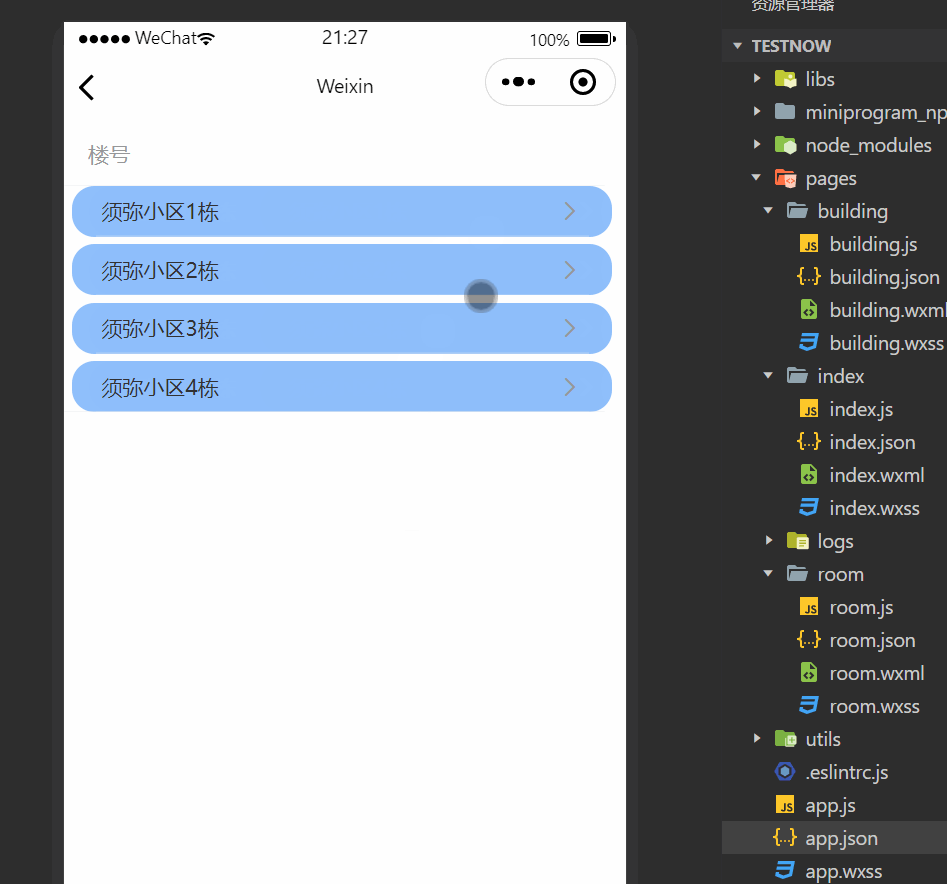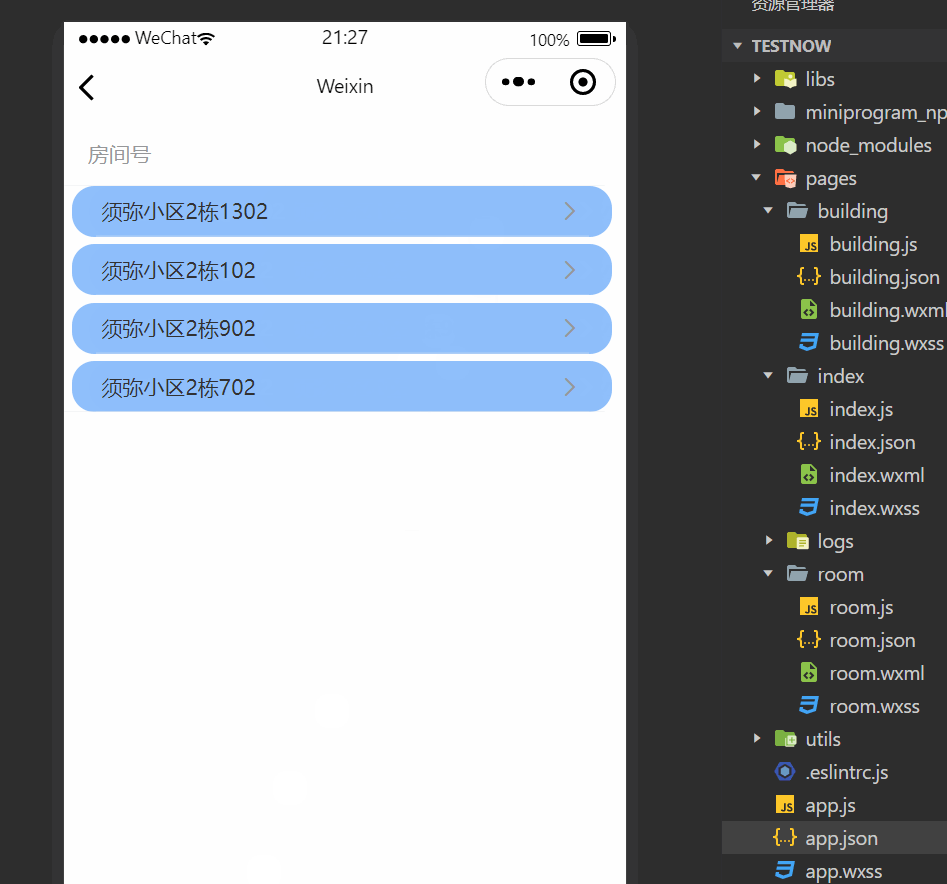
1.应用:性能提高技术
优化程序性能的基本策略如下:
1) 高级设计。为遇到的问题选择适当的算法和数据结构。要特别警觉,避免使用那些会渐进地产生糟糕性能的算法或编码技术。
2) 基本编码原则。避免限制优化的因素,这样编译器就能产生高效的代码
消除连续的函数调用。在可能时,将计算移到循环外。考虑有选择地妥协程序的模块性以获得更大的效率。
消除不必要的内存引用。引入临时变量来保存中间结果。只有在最后的值计算出来时,才将结果存放到数组或全局变量中。
3) 低级优化。结构化代码以利用硬件功能。
展开循环,降低开销,并且使得进一步的优化成为可能。
通过使用例如多个累积变量和重新结合等技术,找到方法提高指令级并行。
用功能性的风格重写条件操作,使得编译采用条件数据传送。
2.确认和消除性能瓶颈
之前我们都是优化小的程序,在这样的小程序中有一些很明显限制性能的地 方,因此应该是集中注意力对它们进行优化。在处理大程序时,连知道应该优化什么地方都是很难的。下面会描述如何使用代码剖析程序, 这是在程序执行时收集性能数据的分析工具。
2.1程序剖析
程序剖析(profiling)运行程序的一个版本,其中插人了工具代码,以确定程序的各个部分需要多少时间。这对于确认程序中我们需要集中注意力优化的部分是很有用的。剖析的一个有力之处在于可以在现实的基准数据(benchmark data)上运行实际程序的同时,进行剖析。
Umx系统提供了一个剖析程序GPROF。
这个程序产生两种形式的信息。
第一个是程序中每个函数花费了多少CPU时间。
第二个是计算每个函数被调用的次数,以执行调用的函数来分类。
这两种形式的信息都非常有用。这些计时给出了不同函数在确定整体运行时间中的相对重要性。调用信息使得我们能理解程序的动态行为。
用GPROF进行剖析需要3个步骤,就像C程序 prog.c所示,它运行时命令行参数为 file.txt:
1) 程序必须为剖析而编译和链接。
linux > gcc -Og -pg prog.c-o prog
2) 然后程序像往常一样执行:
Linux> ./prog file.txt
它运行得会比正常时稍微慢一点(大约慢2倍),还会产生一个文件gmon.out。
3) 调用GPROF来分析gmon.out中的数据。
Linux>gprof prog
剖析报告的第一部分列出了执行各个函数花费的时间,按照降序排列。
作为一个示例,下面列出了报告的一部分,是关于程序中最耗费时间的三个函数的:

其中每一行代表对某个函数的所有调用所花费的时间。
第一列表明花费在这个函数上的时间占整个时间的百分比。第二列显示的是直到这一行并包括这一行的函数所花费的累计时间。第三列显示的是花费在这个函数上的时间,而第四列显示的是它被调用的次数(递归调用不计算在内)。
剖析报告的第二部分是函数的调用历史。下面是一个递归函数find _ele_reC的历史:

这个历史既显示了调用 find_ele_rec 的函数,也显示了它调用的函数。头两行显示的是对这个函数的调用:被它自身递归地调用了158655725次,被函数insert_string调用 了95027次(它本身被调用了965027次)。函数 find_ele_rec 也调用了另外两个函数 save_string 和 new_ele,每个函数总共被调用了363039 次。
根据这个调用信息,我们通常可以推断出关于程序行为的有用信息。
GPR0F有些属性值得注意:
计时不是很准确。它的计时基于一个简单的间隔计数(intervalcounting)机制,编译过的程序为每个函数维护一个计数器,记录花费在执行该函数上的时间。可能出现在两次中断之间也可能运行其他某个程序,却因此根本没有计算花费。
假设没有执行内联替换,则调用信息相当可靠。编译过的程序为每对调用者和被调 用者维护一个计数器。每次调用一个过程时,就会对适当的计数器加1。
默认情况下,不会显示对库函数的计时。相反,库函数的时间都被计算到调用它们的函数的时间中。