程序的优化
- 编写高效的程序:
- 选取合适的数据结构和算法
- 编写出比那一起能够有效优化以转换成高效可执行源代码
- 将任务分成多个部分,可以在多核和多处理器的某种组合上并行的计算
- 程序开发的优化
程序员必须写容易优化的代码,以帮助编译器
- 消除不必要的工作(不必要的函数调用,条件测试,和内存引用)
- 复杂运算简化
- 通常我们通过确认关键路径来决定一个循环所需要的时间下界
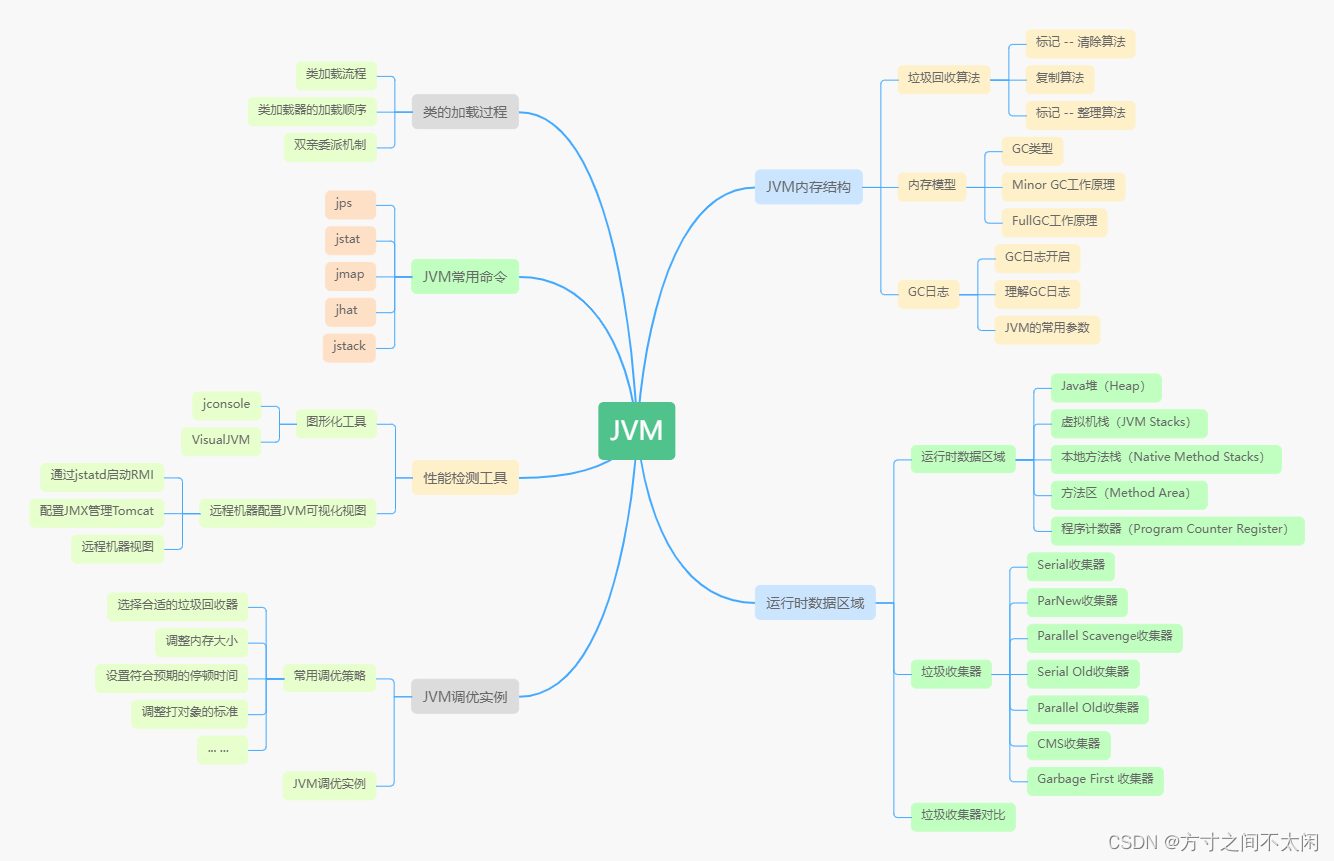
5.1优化编译器的能力和局限性
-o1的优化等级比-o2的优化等级低
- 内存别名使用:两个指针可能指向同一个内存的位置的情况
- 函数调用:函数里面有副作用(全局变量),编译器不会对其进行优化
用内联函数替换优化函数调用
5.2 表示程序性能
引入度量标准每元素的周期数(cycles per element CPE),作为表示程序性能并且知道我们改进代码的方法。他帮助我们在更加细节的级别上理解迭代程序的循环性能
GHz(千兆赫兹,十亿周期每秒)
一次循环计算两个CPE降低
5.3 程序示例
同一个参考机,32位整数操作和64位整数操作有相同的性能,单精度和双精度的浮点数性能也相同,所以就分析其中一个就行
5.4 消除循环的低效率
- 代码移动
5.5 减少过程调用
- 这一节从循环中拿出一个函数,但是性能没有提升,其他因素是限制性能的原因?
- 函数拿出来的这个转变小吃了每次迭代中用于检查向量索引是否在界限内的两个条件语句。对于这个函数来说这些检测总是确定索引是在界内的,所以是高度可预测的
5.6 消除不必要的内存引用
把中间结果放在临时变量中,消除了每次循环迭代中从内存中读出并将更新至写回的需要。
编译器不能自动将引用内存的部分转换到引用寄存器。原因是由于内存别名的使用,可能两个函数有不同的行为
5.7 理解现代处理器
在实际的处理器中,同时对多条指令求值的这个现象是指令级并行
- 延迟界限是由数据相关来引起的,
- 吞吐量界限:
5.7.1 真题操作
- 超标量:指令执行的顺序不一定要与他们在机器及程序中的顺序一致
- 指令控制单元(icu)执行单元(eu)
- 前置负责从内存中读出指令序列,并且根据这些指令序列生成一组针对程序数据的基本操作,;后者执行这些操作
- 乱序处理器的硬件构成更加复杂,但是它能够达到更高的指令级并行度
投机执行:吹起会开始取出位于他预测的分支回跳到的地方的指令,并对指令译码,甚至在他确定分支预测是否正确之前就开始执行这些操作。如果过后发现预测错误,会将状态重新设置到分支点的状态,并开始取出和执行另外一个方向上的指令
取值控制:标记为取值控制的块包括分支预测,以完成确定去哪些指令的任务
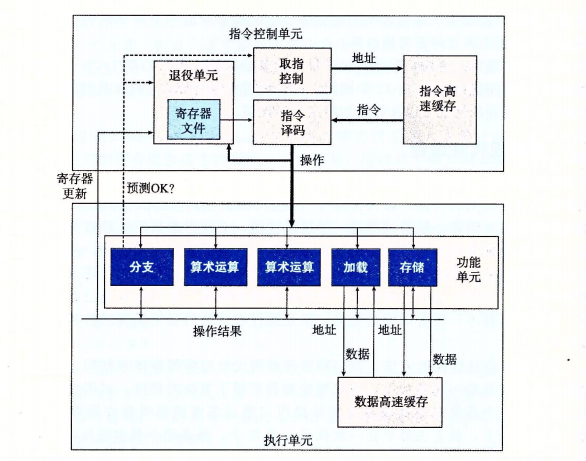
- 指令译码:接受实际指令转换成一组基本操作(一个或者多个操作)
如:addq %rax,8(%rax)会产生多个操作,把内存引用和算数运算分开。分成三个操作1. 从内存中加载一个值到处理器中,一个操作将加载进来的值加上寄存器%rax的值,另外一个操作时将结果存回到内存。 - EU是接受来自取值单元的操作。(注意是操作不是指令)这些操作会分派到一组功能单元中,他们会执行实际的操作

- ICU,退役单元记录正在处理的操作,并确保它遵守机器级程序的顺序语义。
- 任何对程序寄存器的更新都只会在指令退役的时候才会发生,只有在处理器能够缺勤导致这条指令的所有分支都预测正确。在EU中各个功能单元的结果也会互相传送
- 寄存器重命名:
5.7.2 功能单元的性能
- 发射时间为1的功能单元被称为完全流水化
- 表明发射时间的一种方式是最大吞吐量,发射时间的倒数
5.7.3 处理器操作的抽象模型
数据流-关键路径
优化关键路径使CPE的限制变成吞吐量的限制(吞吐量限制是极限)
- 其他影响因素:可用的功能单元的数量和任何一步中功能单元之间能传递值得数量。




循环展开
循环展开能从两方面改进程序的性能:1.它减少了不直接有助于程序结果得操作得数量,例如循环索引计算和分支条件2. 它提供了一些方法,可以进一步变化变化代码,减少整个计算中关键路径上的操作数量
要注意边界检查


关键路径上还是n个乘法
注:编译器可以很容易地执行循环展开,只要优化级别设置的足够高,许多编译器都能例行公事得做到这一点。
提高并行性
程序被延迟界限限制-打破这个限制-通过并行得方式(流水线)打破延迟界限-尽量接近吞吐量界限
多个累积变量
2X2循环展开

通过这种方式打破了延迟界限设下的限制。处理器不再需要延迟一个加法或者乘法操作以待前一个操作完成。查看数据流图发现将之前得一个关键路径变成两个关键路径
- 2x2没有将整数加效率提高到原来的二倍,是因为还有太多得循环开销

- 编译器可以做到

- 浮点乘法和浮点加法是不可结合的P372.。书上举一个极端的例子。
5.9.2 重新结合变换
括号的位置变一下位置,也可能影响程序的性能,这个是通过被操作的数的数值在哪来的有关系
- 大多数编译器不会尝试对浮点运算做重新结合,因为这些运算不保证是可结合的
用向量指令达到更高的并行度
5.10 优化合并代码的结果小结
原始代码-》减少不必要的消耗:内存引用,过程调用,循环展开-》优化好之后延迟界限(关键路径)-》减低延迟界限到吞吐量界限-》提高程序并行性:kxk(流水线),执行向量AVX
5.11 一些限制因素

5.11.1 寄存器溢出
循环并行性的好处受汇编代码描述的计算能力限制,如果我们的并行度P超过了可用寄存器数量,那么编译器就会溢出,将某些临时变量放到内存中,通常实在运送时堆栈上分配空间
5.11.2 分支预测和预测错误处罚
- 不要过分关注心可预测的分支(combine2-》combine3) (有个什么内联函数没看懂)
- 书写适用条件传送实现的代码
对于本质上无法预测的情况,如果编译器能够产生使用条件数据传送而不是使用条件控制转移代码,可以极大的提高程序的性能

理解内存性能
cache,加载和存储单元都有缓冲区
2.12.1 加载的性能
一个包含加载操作的程序性能既依赖于流水线的能力也依赖于加载单元的延迟
- 对于每个被计算的元素必须加载K个值得应用,我们不可能获得低于k/2得CPE
5.12.2存储的性能
存储操作不会产生数据相关








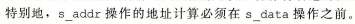

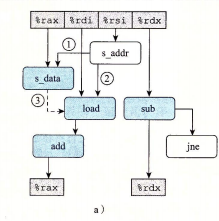
- 标号为以的弧线表示存储地址必须在数据被存储之前计算出来,标号二的弧线表示需要load操作将他的地址与所有未完成的存储操作的地址进行比较,标号三的虚线表示条件数据相关,当加载和存储地址相同时会出现。
- 首先加载出%rax要存在内存哪里,然后通过二号弧线比一比要操作的内存地址和正在写的内存地址相同不,如果相同的话就要等写入完成之后才能加载,就通过弧线3告诉load单元写入完成。然后进行加载操作,再运算。




程序优化