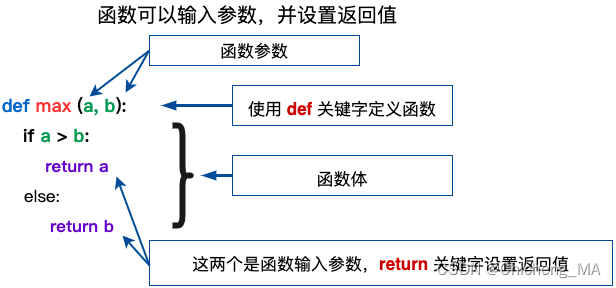
就以咱们csdn网站的结构来看看这些网页的基础内容
1、查看网页源代码
1、F12,或者右上角三个点找到更多工具里面有一个开发人员工具
之后点击左上角
你就能看见一个网页的源代码
当然你现抄是没法完全实现的
然后我们就以csdn的门面进行对网页结构进行认识
我们主要认识一下<body>里面的内容
1、<div>标签
他是干啥的为啥咱们这里会有这么多<div>
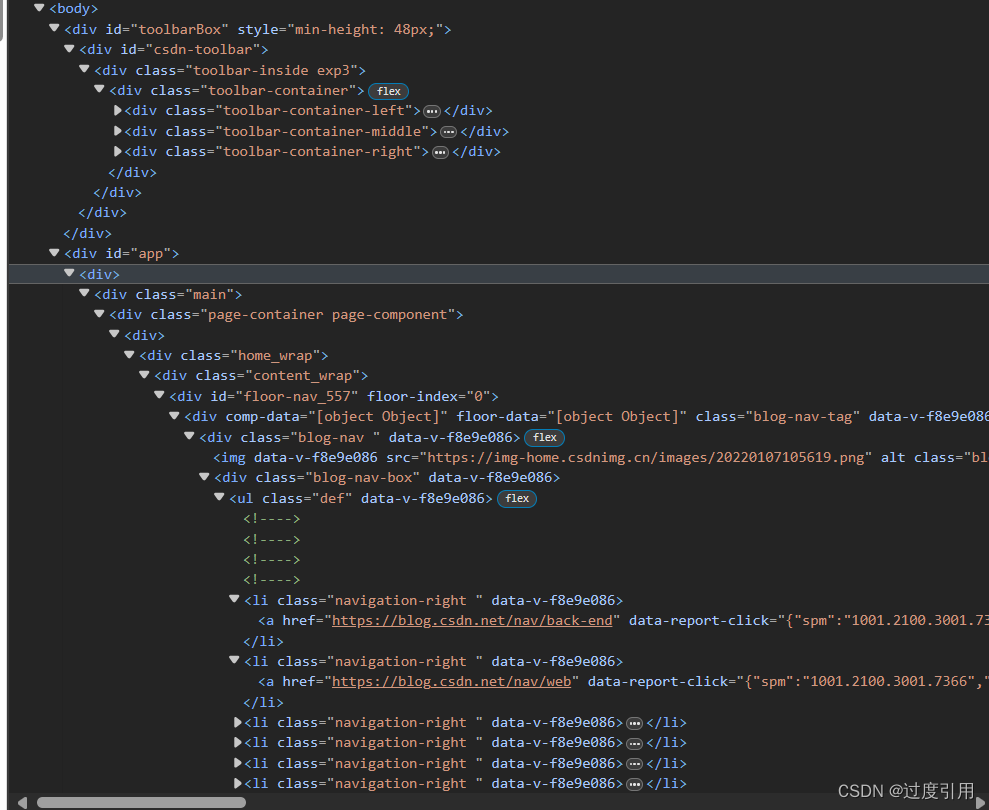
<div>标签 就是块标签,将网页中规划出一块区域进行显示内容
下面我将用一些代码来进行演示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>过度引用</title>
<style>
div{
background-color:pink;
display: inline-block;
width: 100px;
height:100px;
}</style>
</head>
<body>
<div>
</div>
</body>
</html>
这里的div 的格式完全可以按照自己的喜好进行设置大小背景色等等以及是否独占一行等等都是可以做到的
结果如下:

2、<ul> 标签<ol>标签 <li>标签
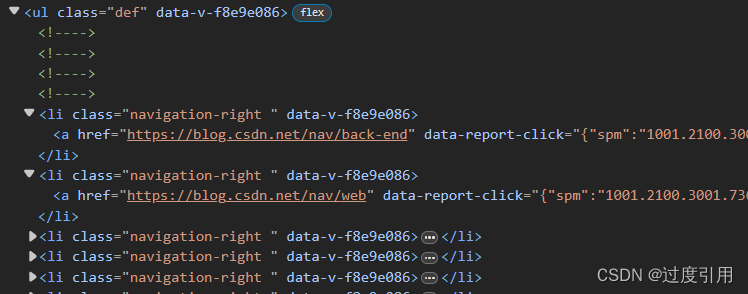
定义列表的元素 当然在csdn的门户是用ul嵌套li做的也就是最上面的一列
现在我们来试试看去使用requests模块去爬取一下csdn
import requests
resp = requests.get(url='https://www.csdn.net')
print(resp.text)
结果如下:
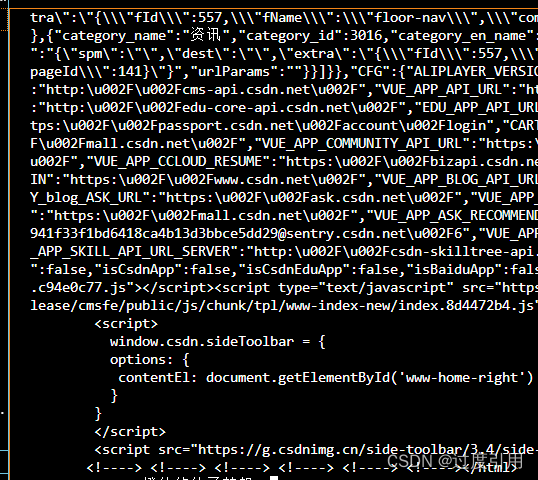
其实就是把源代码给拿过来了
关于动态数据的加载等下次再说。
























![【洛谷 P8625】[蓝桥杯 2015 省 B] 生命之树 题解(深度优先搜索+树形DP)](https://img-blog.csdnimg.cn/direct/c03e432f830740b8b940fcf2f441aeb7.png)