一、前言
1.1:目标跟踪VS目标检测:区别和联系
区别:
任务目标
- 目标跟踪任务的目标是在视频序列中跟踪一个特定目标的位置,即给定第一帧中的目标位置后,在后续帧中确定目标的位置。
- 而目标检测任务的目标是在静态图像中检测和定位出现的目标,即在给定图像中找到所有目标的边界框。
数据输入
- 目标跟踪任务通常涉及处理视频序列,需要在连续的帧之间跟踪特定的目标。
- 而目标检测任务则处理静态图像,每个图像都是独立的输入。
上下文信息利用
- 在目标跟踪任务中,由于连续帧之间存在时间和空间上的相关性,可以利用先前帧中的信息来帮助确定目标的位置。(前面所讲的限制区域搜索策略,就是利用这种连续帧之间的相关性,来确定下一帧的搜索区间)
- 而目标检测任务通常只使用单个图像,缺乏时间上的上下文信息。(联系之前做的安全帽视频检测,虽然也是对视频进行处理,但是本质还是每一帧都是一个单独的处理对象,无任何联系)
联系
目标表示
- 目标跟踪任务和目标检测任务都需要对目标进行有效的表示,通常使用边界框来表示目标的位置和大小。
特征提取
- 两个任务都需要从输入数据中提取特征以表示目标。常见的特征提取方法包括使用卷积神经网络(CNN)提取图像特征或使用光流等方法提取视频序列中的运动特征。
目标类别识别
- 虽然目标跟踪任务的主要目标是确定目标的位置,但有时也需要对目标进行类别识别,即确定目标属于哪个类别。在目标检测任务中,类别识别是一个重要的子任务,需要确定每个检测到的目标的类别标签。
1.2:目标跟踪任务分类
单目标跟踪:给定一个目标,追踪这个目标的位置
- 单目标,单摄像头
无模型的,只有第一帧指定的 框
短期跟踪,不支持重新检测,丢失后,就跟踪失败
跟踪器不使用任何未来帧。 - 主要逻辑
启动跟踪器 Setup tracker 设置目标区域 Read initial object region and first image 初始化跟踪器 Initialize tracker with provided region and image 循环 loop 读取下一张图像 Read next image 图像为空 if image is empty then 跳出循环 Break the tracking loop end if 更新跟踪器 Update tracker with provided image 记录目标区域 Write region to file 结束循环 end loop 清理跟踪器 Cleanup tracker- 单目标,单摄像头
多目标跟踪:追踪多个目标的位置
Person Re-ID - 行人重识别
利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合。MTMCT - 多目标多摄像头跟踪(Multi-target Multi-camera Tracking):跟踪多个摄像头拍摄的多个人
姿态跟踪
- Step1:姿态估计(Pose Estimation):在每一帧中检测人体的关键点。这可能是基于深度学习的方法,如使用卷积神经网络(CNN)来预测关键点的位置。
- Step2:姿态关联(Pose Association): 在视频序列的连续帧中将检测到的人体姿态与之前跟踪的姿态相匹配,以确保同一个人的姿态在整个视频中能够被正确地关联起来
按照任务计算类型又可以分为以下2类
- 在线跟踪:在线跟踪需要实时处理任务,通过过去和现在帧来跟踪未来帧中物体的位置。
- 离线跟踪 :离线跟踪是离线处理任务,可以通过过去、现在和未来的帧来推断物体的位置,因此准确率会在线跟踪高。
1.3:目标跟踪的困难点
形态变化 - 姿态变化是目标跟踪中常见的干扰问题。运动目标发生姿态变化时, 会导致它的特征以及外观模型发生改变, 容易导致跟踪失败。例如:体育比赛中的运动员、马路上的行人。
尺度变化 - 尺度的自适应也是目标跟踪中的关键问题。当目标尺度缩小时, 由于跟踪框不能自适应跟踪, 会将很多背景信息包含在内, 导致目标模型的更新错误:当目标尺度增大时, 由于跟踪框不能将目标完全包括在内, 跟踪框内目标信息不全, 也会导致目标模型的更新错误。因此, 实现尺度自适应跟踪是十分必要的。
遮挡与消失 - 目标在运动过程中可能出现被遮挡或者短暂的消失情况。当这种情况发生时, 跟踪框容易将遮挡物以及背景信息包含在跟踪框内, 会导致后续帧中的跟踪目标漂移到遮挡物上面。若目标被完全遮挡时, 由于找不到目标的对应模型, 会导致跟踪失败。
图像模糊 - 光照强度变化, 目标快速运动, 低分辨率等情况会导致图像模型, 尤其是在运动目标与背景相似的情况下更为明显。因此, 选择有效的特征对目标和背景进行区分非常必要。
二、目标跟踪算法介绍
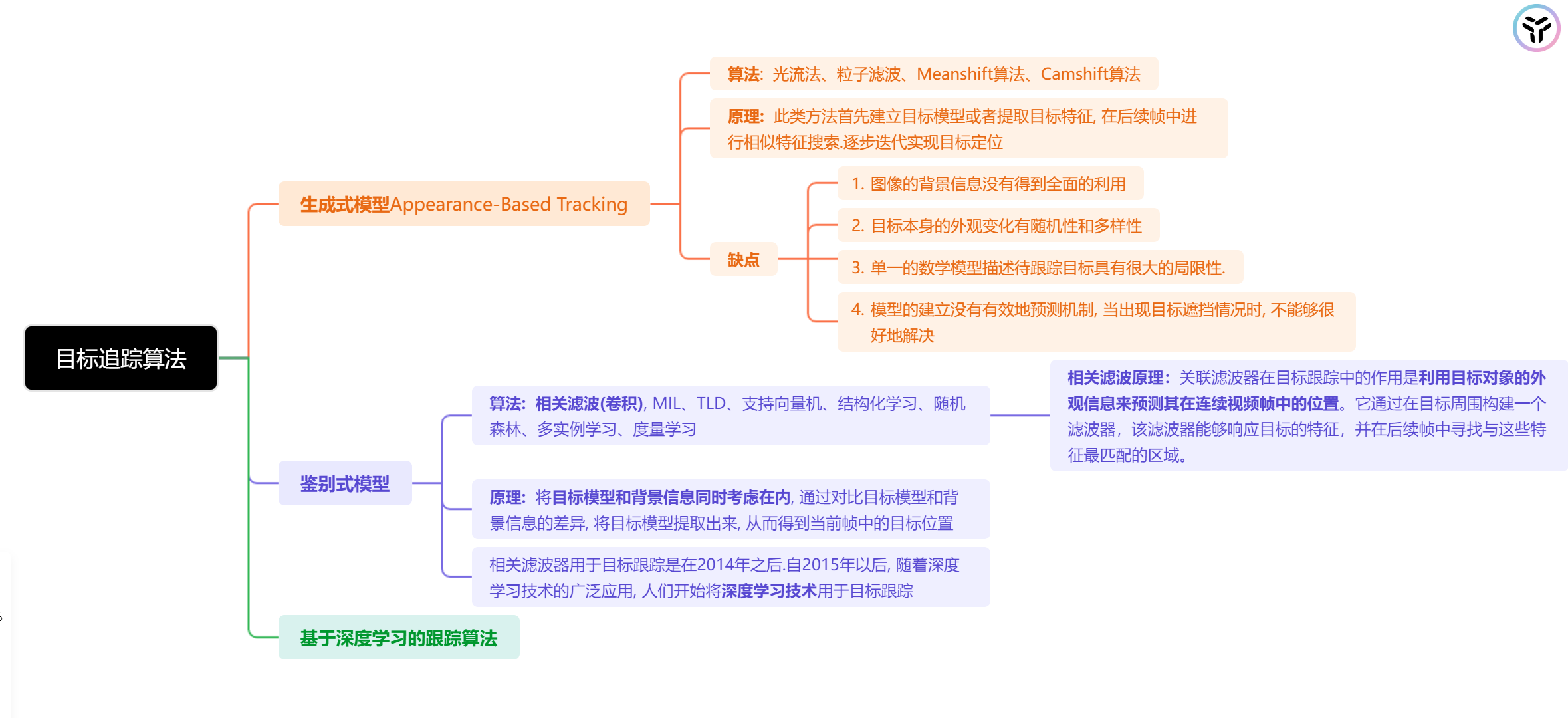
2.1:生成式模型
Appearance-Based Tracking 代表算法:均值漂移算法(Mean Shift)、LK光流等。

在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,与传统的盲搜不同,它利用相邻帧之间目标位置变化不大的特点,采用迭代逼近的方式提高算法的搜索速度

2.2:判别式模型
目前比较流行的是判别类方法(Discriminative Tracking)
参考:https://www.cse.psu.edu/~rtc12/CSE598C/classificationTracking.pdf
https://www.cse.psu.edu/~rtc12/CSE598C/LKintro.pdf

- 核心思想:在视频序列中区分目标对象和背景环境,即学习一个分类器或者一个滤波器来判别目标和非目标。
步骤如下:
- 特征提取:
从目标对象和周围的背景区域提取特征。这些特征可以是手工设计的,如HOG(方向梯度直方图)、SIFT(尺度不变特征变换)等,或者是深度学习方法自动学习得到的特征。 - 模型训练:
使用提取的特征训练一个判别模型。这个模型的任务是区分目标和背景。训练过程可以使用正样本(目标)和负样本(背景)来完成。 - 目标定位:
在后续的视频帧中,判别模型被用来搜索和定位目标。定位通常是通过在新帧中评估多个候选区域,并选择判别模型输出最高分数的区域作为目标的新位置。 - 在线更新:⭐
跟踪过程中,目标的外观可能会变化,因此判别模型需要在线更新以适应这些变化。更新策略可以是增量学习或者使用一种滑动窗口机制来逐渐忘记旧的样本这里其实就体现了目标跟踪和目标检测的不同,目标跟踪需要不断利用连续帧之间的信息,进行跟踪。而目标检测or分类是处理静态的图片帧,一旦模型训练的足够好,就可以达到理想效果。
- 尺度和旋转处理:
目标在移动过程中可能会发生尺度变化或旋转。判别式跟踪方法需要有一定的机制来适应这些变化。
判别式跟踪方法的代表包括:
- TLD (Tracking-Learning-Detection): TLD跟踪器将跟踪、学习和检测结合起来,以应对长时跟踪中的目标外观变化。
- Struck (Structured Output Tracking with Kernels): Struck跟踪器使用结构化输出SVM并结合核技巧来进行目标跟踪。
- MOSSE (Minimum Output Sum of Squared Error): MOSSE使用相关滤波器进行快速跟踪,并具有很好的实时性和准确性。
- KCF (Kernelized Correlation Filters): KCF通过核技巧增强相关滤波器的性能,能够处理非线性特征空间。
- DCF (Discriminative Correlation Filters): DCF基于相关滤波器,通过学习区分目标和背景的滤波器系数进行跟踪。
深度学习方法,如基于卷积神经网络(CNN)和孪生网络的跟踪器,其实也可以归类为判别式方法,因为它们通常涉及到训练一个能够区分目标和背景的网络。
判别式跟踪方法的优点在于它们通常能提供较高的跟踪精度,并且能较好地处理遮挡、光照变化和背景干扰等问题。然而,这些方法的挑战在于需要有效的在线更新机制以及对目标外观变化的适应性。
判别式方法的目标跟踪与目标检测的主要关联和区别在于后者通常作为跟踪任务的一个组成部分。在跟踪的开始阶段,可以使用目标检测来初始化跟踪器,之后目标跟踪算法会接管,持续追踪目标对象随时间的移动和变化。
2.4:总结
生成式目标跟踪方法与相关滤波的判别式目标跟踪方法有几个关键的区别:
- 模型概念:
- 生成式方法:生成式跟踪方法的核心思想是建模目标的外观,并尝试在后续帧中重新找到这个外观。它通常通过建立一个目标的外观模型,然后在新的帧中寻找与该模型最相似的区域。
- 判别式方法(如相关滤波):判别式方法是基于区分目标和背景的思想。它学习一个分类器或者滤波器来区分目标和周围的背景。相关滤波跟踪算法通过训练相关滤波器来最大化目标和非目标之间的响应差异。
- 目标定位:
- 生成式方法:在新的帧中,生成式方法通常通过寻找与模型最相似的区域来定位目标,通常使用搜索窗口在整个图像中搜索。
- 判别式方法:相关滤波算法使用滤波器在目标周围的区域进行卷积,产生一个响应图,并在这个响应图中找到最大响应值对应的位置作为目标的新位置。
- 处理遮挡和变化:
- 生成式方法:生成式方法依赖于目标的外观模型,如果目标发生显著变化或遭受遮挡,这种方法可能会丢失目标。
- 判别式方法:相关滤波算法能够在线更新滤波器来适应目标的外观变化,这使得它们在处理遮挡和外观变化时通常更为鲁棒。
- 实时性:
- 生成式方法:尽管一些生成式方法可以实现快速跟踪,但是它们在搜索过程中可能会受到计算效率的限制。
- 判别式方法:相关滤波算法特别适合于实时跟踪,因为它们在频域中进行计算,可以利用快速傅里叶变换来加速响应图的生成。
- 背景信息:
- 生成式方法:这种方法主要关注于目标的表示,没有显式地利用背景信息。
- 判别式方法:相关滤波以及其他判别式方法通过考虑背景,学习一个可以区分目标和背景的滤波器。
在实际应用中,选择哪种跟踪方法取决于特定的任务需求、环境条件以及性能要求。有时,为了提高跟踪的稳定性和准确性,也会将生成式和判别式方法结合起来使用。