R语言快速读取大文件

想象一下,一辆赛车在巴音布鲁克赛道上,嗖的一声飞驰而过,这种场景是不是很酷!R语言中,如果用vroom读取一个GB级别的大文件,也能体会到这种速度感。

今天分享的一个R小技巧是读取大文件的最佳方式,尤其是GB以上的文件,比如常见的csv、tsv、txt等类型的文件。还可以批量读取、远程读取、自动解压缩,用起来体验非常不错。
如何使用?
install.packages("vroom")
library(vroom)
# install.packages("pak")
pak::pak("tidyverse/vroom")
首先安装一下,这个包是属于tidyverse生态圈,由Rstudio公司官方维护,主要是用C++进行优化。
官方宣称的速度可以达到1.23 GB/s
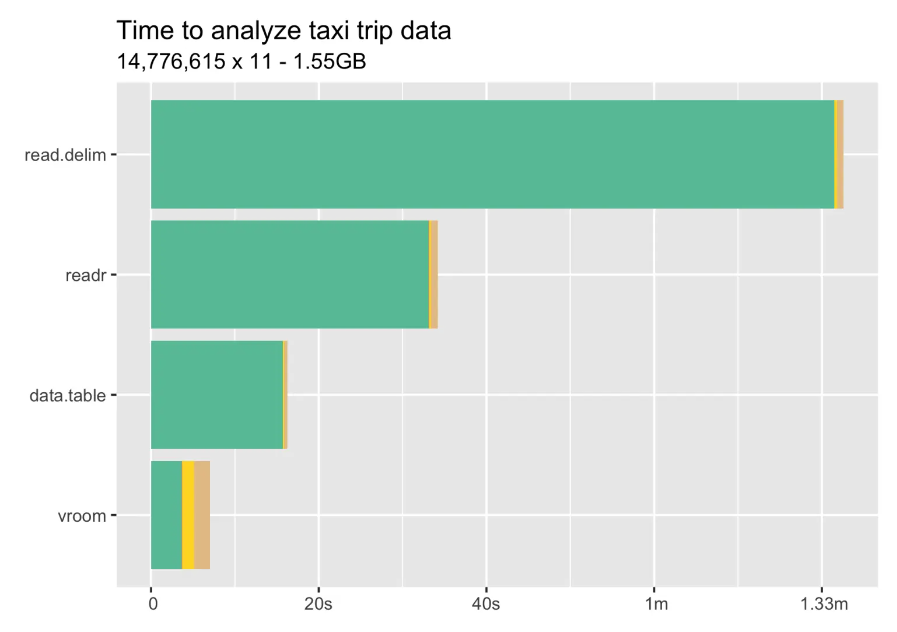
 读取一个1.55G的文件,使用传统方式一分半,用vroom几秒钟就完成
读取一个1.55G的文件,使用传统方式一分半,用vroom几秒钟就完成
vroom有自动识别文件格式功能,所以不管是csv,还是tsv文件都只需要同一个读取指令vroom(”xxx.csv”)就可以。
读取CSV文件
vroom::vroom("mtcars.tsv",
col_types = list(cyl = "i", gear = "f",hp = "i", disp = "_",
drat = "_", vs = "l", am = "l", carb = "i")
)
#> # A tibble: 32 × 10
#> model mpg cyl hp wt qsec vs am gear carb
#> <chr> <dbl> <int> <int> <dbl> <dbl> <lgl> <lgl> <fct> <int>
#> 1 Mazda RX4 21 6 110 2.62 16.5 FALSE TRUE 4 4
#> 2 Mazda RX4 Wag 21 6 110 2.88 17.0 FALSE TRUE 4 4
#> 3 Datsun 710 22.8 4 93 2.32 18.6 TRUE TRUE 4 1
#> # ℹ 29 more rows
使用vroom包的vroom函数来读取一个名为"mtcars.tsv"的TSV文件(制表符分隔的值)。它指定了列的类型通过col_types参数。按照指定的列类型读取TSV文件,忽略不需要的列,确保数据以正确的格式被导入R环境中。
批量读取多个文件
library(nycflights13)
purrr::iwalk(
split(flights, flights$carrier),
~ { .x$carrier[[1]]; vroom::vroom_write(head(.x, 2), glue::glue("flights_{.y}.tsv"), delim = "\t") }
)
使用vroom包的vroom_write函数,这个函数的目的是将数据写入文件。head(.x, 2)取每个航空公司的前两条航班记录;glue::glue("flights_{.y}.tsv")使用glue包生成文件名,文件名包含航空公司代码;最后指定文件的分隔符为制表符(\t),生成的文件是.tsv格式。
直接读写压缩文件
vroom_write(flights, "flights.tsv.gz")
# Check file sizes to show file is compressed
fs::file_size(c("flights.tsv", "flights.tsv.gz"))
#> 29.62M 7.87M
# Read the file back in
data <- vroom("flights.tsv.gz")
vroom_write函数可以将数据从R中导出为文件,比如这里直接导出为压缩文件,减少储存空间。
读取指定列的数据
data <- vroom("flights.tsv", col_select = c(year, flight, tailnum))
#> Observations: 336,776
#> Variables: 3
#> chr [1]: tailnum
#> dbl [2]: year, flight
有的时候只需要部分数据,并不想全部导入,就可以用这种方法。
今天分享的小技巧就到这里结束啦,感谢您的阅读,如果感觉有所收获欢迎点在转发分享。这个方法在处理生物信息学大量数据时还是挺有用的,避免把时间浪费在文件读写上,让数据分析更加的丝滑流畅!
本文由 mdnice 多平台发布