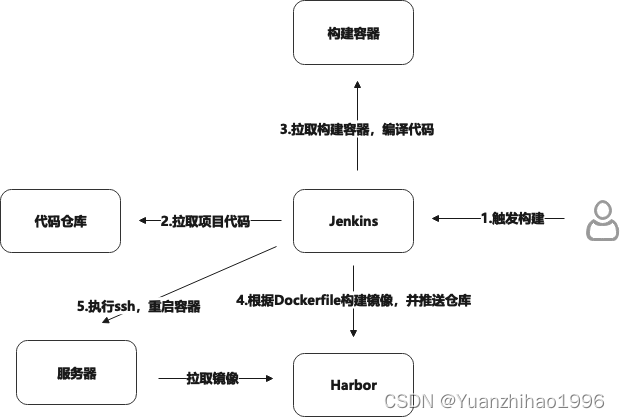
直接比较Hive和Spark SQL的并行能力并不是简单的任务,因为它们有着不同的架构和设计目标。以下是一些相关方面的考虑:
架构差异:
- Hive: Hive 是基于Hadoop MapReduce 的数据仓库工具,其执行查询的方式是通过将 Hive 查询转化为一系列的 MapReduce 任务。MapReduce 是一种批处理模型,它的并行处理是通过分布式计算框架来实现的。
- Spark SQL: Spark SQL 是基于Spark的组件,Spark 使用内存计算和弹性分布式数据集(RDD)的概念,支持更灵活的、交互式的数据处理。Spark SQL 可以在内存中执行计算,从而提高并行处理能力。
内存计算:
- Hive: Hive 主要是面向离线批处理的,其默认情况下使用磁盘存储中间数据,这可能限制了其并行计算的性能。
- Spark SQL: Spark SQL 支持内存计算,可以将中间数据缓存在内存中,从而加速查询。这种内存计算的特性使得 Spark SQL 在并行处理和响应时间上有一定的优势。
交互式查询:
- Hive: Hive 在处理交互式查询方面相对较慢,因为其基于 MapReduce 的执行模型可能导致较高的延迟。
- Spark SQL: Spark SQL 提供了更快的响应时间,支持交互式查询,这在需要快速分析和查询数据时是一个优势。
总的来说,Spark SQL 在某些方面可能具有更强的并行能力,尤其是在内存计算和交互式查询方面。然而,选择使用Hive还是Spark SQL取决于具体的使用场景、数据规模以及系统架构的需求。有些场景中,Hive 的批处理模型可能仍然是合适的,而在需要更灵活、交互式处理的情况下,Spark SQL 可能更具优势。
























![[递归、搜索、回溯]----递归 [数据结构]~二叉树 [数据结构]-玩转八大排序(二)&&冒泡排序&&快速排序 [数据结构]-玩转八大排序(三)&&归并排序&&非比较排序](https://img-blog.csdnimg.cn/f55a07090b3541518429c3017449bf1b.png)