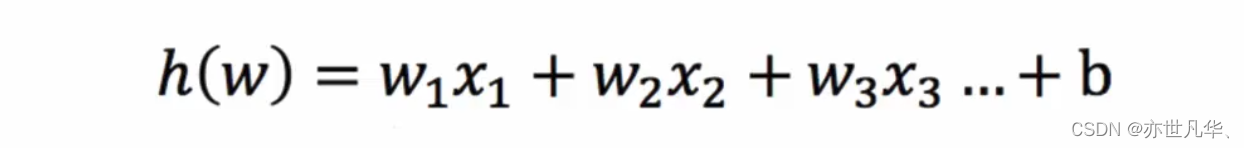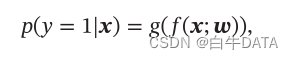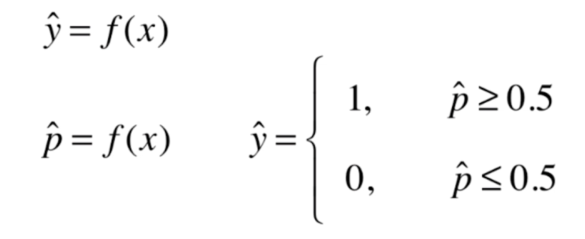1、引言
接着上篇《【机器学习】一文掌握逻辑回归全部核心点(上)。》我们继续来聊逻辑回归的核心要点。
2、逻辑回归核心点
2.5 特征工程
2.5.1 特征缩放
归一化(Normalization):将数据视为向量,再将向量除以其范数(通常采用L2范数),有量纲,对应sklearn中normalize方法。它针对数据集中单个样本进行缩放,适合依赖样本间相似性的算法。但会改变数据集中特征数值的分布,因此不适合依赖特征预测的算法。
标准化(Standardization):对数据大小按照标准方法进行调整,使值位于特定范围内,无量纲。这主要针对数据集中单个特征进行缩放。标准化方法有两种:
- Min-Max标准化:最大-最小值区间缩放,即减去最小值,再除以极差。标准化后数据位于[0,1]内,无量纲,对应sklearn中minmax_scale方法。
- Z-score标准化:即减去均值,再除以标准差。这是最常用的标准化方法。
特征缩放的优势:
- 帮助梯度下降法更快速地收敛。
- 避免“NaN 陷阱”,即模型中的一个数值因超出浮点精确率限制而变成NaN,导致所有其他数值也因数学运算而变成NaN。
- 使模型为每个特征确定合适的权重,避免模型对范围较大的特征投入过多精力。
2.5.2 多项式特征
多项式特征生成
- 特征乘积:这是最简单的方法,通过将两个或多个原始特征的乘积作为新的特征。例如,如果有两个特征x1和x2,可以生成一个新的特征x1*x2。这种方法在逻辑回归中特别有用,因为它可以帮助捕捉特征之间的交互作用。
- 幂次特征:通过将原始特征提升到不同的幂次来生成新的特征。例如,对于一个特征x,可以生成x2、x3等作为新的特征。这有助于捕捉数据的非线性关系。
- 多项式扩展:使用像sklearn.preprocessing.PolynomialFeatures这样的工具来进行多项式扩展。这种工具可以自动生成所有可能的特征组合和幂次,从而创建一个高维的特征空间。
多项式特征应用
- 回归问题:在回归问题中,多项式特征可以帮助捕捉数据中的非线性关系,从而提高回归模型的准确性。例如,在预测房价时,房屋面积的平方或立方可能是一个重要的特征。
- 分类问题:在分类问题中,多项式特征同样可以帮助提高模型的性能。通过捕捉特征间的交互作用和非线性关系,多项式特征可以增强分类器的判别能力。
- 特征选择:多项式特征生成后,通常需要进行特征选择,以消除冗余和无关的特征,提高模型的泛化能力。这可以通过使用特征选择算法或基于模型的特征选择方法来实现。
2.6 多分类
一对多(One-vs-Rest,OvR)和一对一(One-vs-One,OvO)是用于处理多类别分类问题的两种不同策略。这两种策略都是基于二分类器的组合,将多类别问题转化为多个二分类问题。
2.6.1 一对多(One-vs-Rest,OvR)策略
在一对多策略中,对于具有 个类别的问题,每个类别都训练一个二分类器。对于第 个类别,训练一个二分类器,将该类别的样本标记为正类别(1),其他所有类别的样本标记为负类别(0)。因此,针对每个类别都有一个独立的二分类器。
在测试阶段,将样本输入到所有的二分类器中,最终选择预测概率最高的类别作为最终的预测结果。一对多策略的优势在于每个二分类器只需关注一个类别,相对简单和高效。
2.6.2 一对一(One-vs-One,OvO)策略
在一对一策略中,对于具有 个类别的问题,每两个类别之间训练一个二分类器。因此,对于 个类别,需要 个二分类器。对于每个二分类器,只包含两个类别的样本,其他所有类别的样本都被忽略。
在测试阶段,将样本输入到所有的二分类器中,每个分类器产生一个预测结果。最终通过投票或其他集成方法,选择得票最多的类别作为最终的预测结果。
2.6.2 比较
计算复杂度:一对多策略通常比一对一策略更快,因为需要训练的二分类器数量较少。
存储开销:一对一策略在类别较多时可能需要较大的存储开销,因为需要存储多个二分类器。
类别不平衡:一对多策略在处理类别不平衡时可能更稳健,因为每个分类器关注一个类别。
预测时间:一对多策略的预测时间通常更短,因为只需进行 次预测。
选择使用一对多还是一对一策略通常取决于具体的问题和数据集。在实际应用中,一对多策略更为常见。某些算法,如支持向量机(SVM),在类别较多时可能更适合使用一对一策略。
2.7 评估指标
2.7.1 准确率
准确率是分类任务中最常用的评估指标之一,它表示模型正确预测的样本数与总样本数之比。然而,当数据集存在类别不平衡问题时,准确率可能不是一个很好的指标。
公式:
Accuracy = TP + TN TP + TN + FP + FN \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} Accuracy=TP+TN+FP+FNTP+TN
代码示例
from sklearn.metrics import accuracy_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
accuracy = accuracy_score(y_true, y_pred)
print(f"Accuracy: {accuracy}")
2.7.2 精确率
精确率是指模型预测为正例的样本中,真正为正例的样本所占的比例。它有助于了解模型在预测为正例的样本中的准确性。
公式:
Precision = TP TP + FP \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} Precision=TP+FPTP
代码示例
from sklearn.metrics import precision_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
precision = precision_score(y_true, y_pred)
print(f"Precision: {precision}")
2.7.3 召回率
召回率是指所有真正的正例样本中,被模型正确预测为正例的样本所占的比例。它有助于了解模型在识别所有正例样本时的能力。
公式:
Recall = TP TP + FN \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} Recall=TP+FNTP
代码示例
from sklearn.metrics import recall_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
recall = recall_score(y_true, y_pred)
print(f"Recall: {recall}")
2.7.4 F1分数
F1 分数是精确率和召回率的调和平均值,用于综合考虑精确率和召回率的表现。当精确率和召回率都很高时,F1 分数也会很高。
公式:
F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
代码示例
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
f1 = f1_score(y_true, y_pred)
print(f"F1 Score: {f1}")
2.7.5 混淆矩阵(Confusion Matrix)
混淆矩阵展示了模型预测结果的实际情况,包括真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)。通过混淆矩阵,可以直观地了解模型在各种情况下的表现。
代码示例
from sklearn.metrics import confusion_matrix
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
cm = confusion_matrix(y_true, y_pred)
print(f"Confusion Matrix:\n{cm}")
2.7.6 均方误差(Mean Squared Error, MSE)
MSE 是回归任务中常用的评估指标,它计算了模型预测值与真实值之间平方差的平均值。MSE 越小,说明模型的预测性能越好。
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
代码示例
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
print(f"MSE: {mse}")
2.7.7 均方根误差(Root Mean Squared Error, RMSE)
RMSE 是 MSE 的平方根,它同样用于衡量模型预测值与真实值之间的误差。与 MSE 相比,RMSE 的单位与真实值的单位相同,更容易解释。
公式:
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \ RMSE=n1i=1∑n(yi−y^i)2
代码示例
from sklearn.metrics import mean_squared_error
import numpy as np
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
print(f"RMSE: {rmse}")
2.7.8 平均绝对误差(Mean Absolute Error, MAE)
MAE 计算了模型预测值与真实值之间绝对误差的平均值。与 MSE 和 RMSE 不同,MAE 对误差的敏感性较低,可以更好地反映模型在极端情况下的性能。
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
2.7.9 R²(Coefficient of Determination)
R² 表示模型解释的变异度与总变异度的比例。R² 的值越接近 1,说明模型的拟合效果越好。然而,需要注意的是,当数据集中的变量之间存在多重共线性时,R² 的值可能会过高,此时需要谨慎解读。
公式:
R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
3、总结
看到这里,关于逻辑回归的核心点的内容都讲完了。
逻辑回归在许多领域有着广泛应用,包括但不限于信用评分、疾病诊断、市场营销中的用户行为预测等。它的简洁性和有效性使其成为许多机器学习项目的基础构建块。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 多个名企认证讲师等;
- 认证金牌面试官;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,学习机器学习领域的知识。