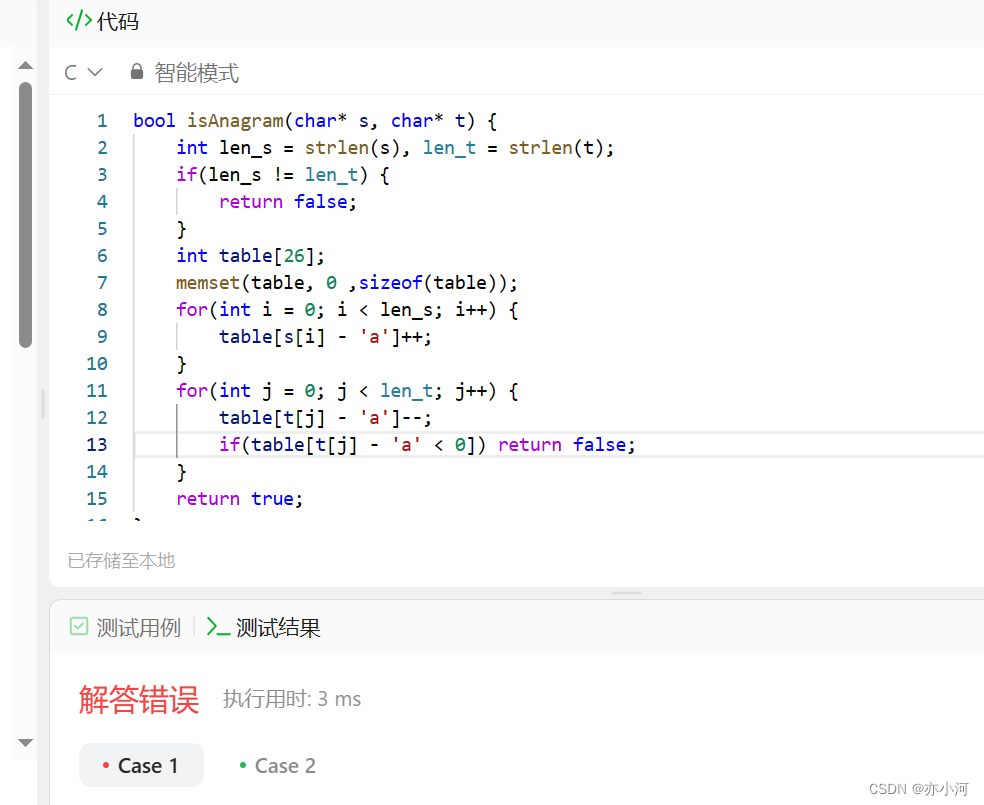
大数据与Hadoop
大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
Hadoop是什么?
Hadoop是一种分析和处理海量数据的软件平台,是一款开源软件,使用JAVA开发,可以提供一个分布式基础架构
Hadoop特点:
高可靠性 :Hadoop按位存储和数据处理的能力值得信赖
高扩展性:Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性
高效性:Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性
高容错性:Hadoop能够自动保存数据的多个副本(默认是3个),并且能够自动将失败的任务重新分配
Hadoop版本:
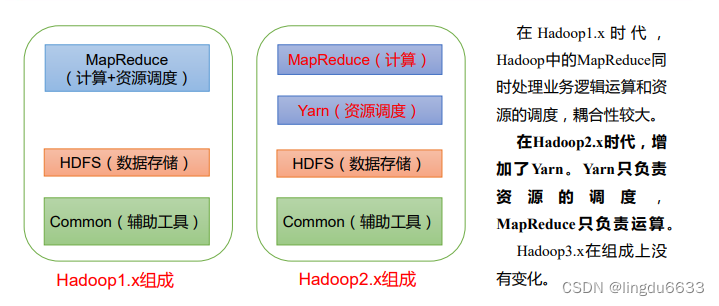
Hadoop1.0:包含Common,HDFS和MapReduce,停止更新
Hadoop2.0:包含了Common,HDFS,MapReduce和YARN。Hadoop2.0和Hadoop1.0完全不兼容。
Hadoop3.0:包含了Common,HDFS,MapReduce,YARN。Hadoop3.0和Hadoop2.0是兼容的
Hadoop核心组件
HDFS(Hadoop Distributed File System)
HDFS:分布式存储,解决海量数据的存储
HDFS特点及原理:HDFS具有扩展性、容错性、海量数量存储的特点,原理为将大文件切分成指定大小(默认128M)的数据块, 并在分布式的多台机器上保存多个副本
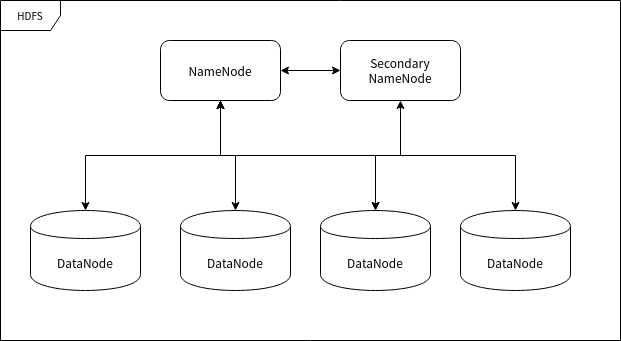
HDFS角色和概念
Client
1.1 切分文件
1.2 与namenode交互获取节点或文件元数据
1.3 与datanode交互写入或读取数据
Namenode(管理节点)
2.1 存入文件元数据信息
2.2 配置副本策略
2.3 处理客户端的所有请求(读和写)
Secondarynode
3.1 定期同步NameNode的元数据和日志信息,紧急情况下,可转正
Datanode(数据节点)
4.1 存储具体数据
4.2 汇报存储信息给namenode(datanode定期向namenode发送心跳消息。)
Block
每块默认128MB大小
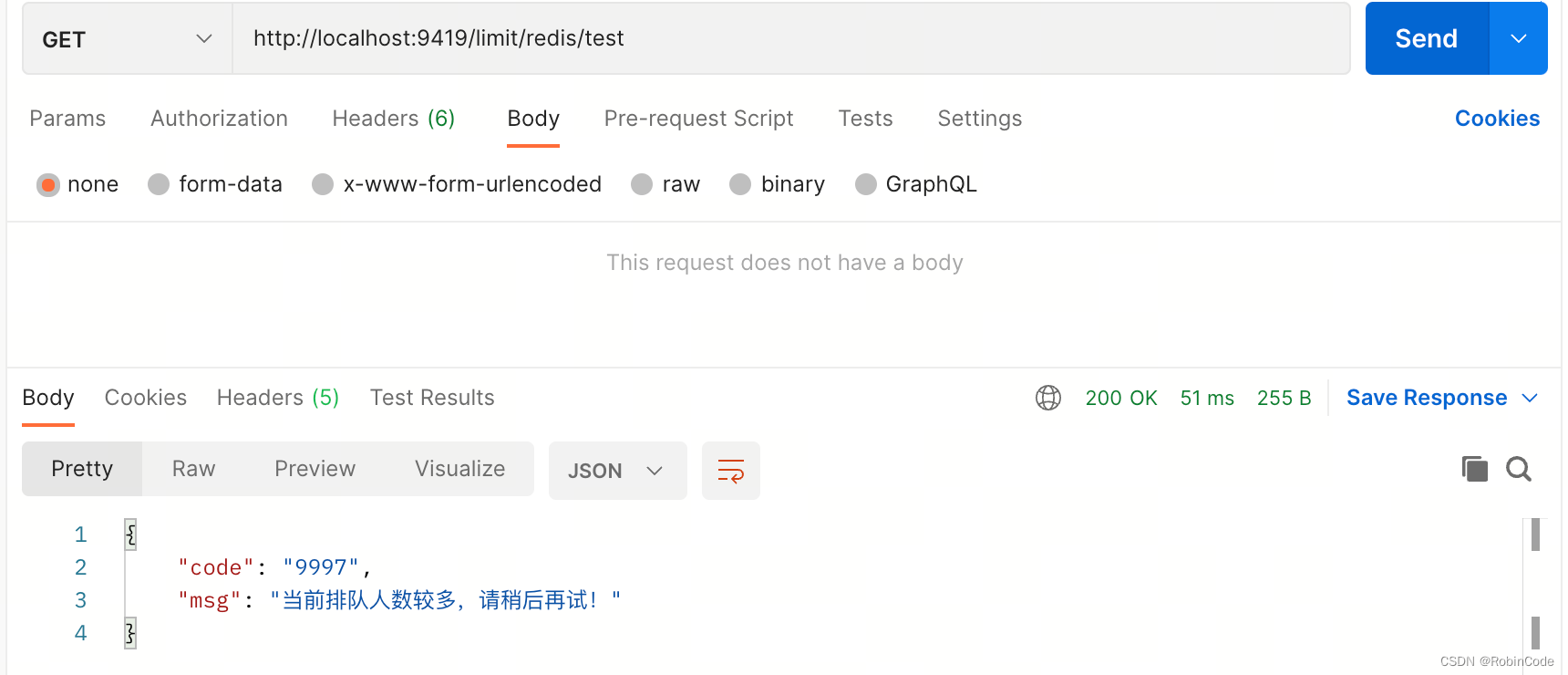
HDFS写文件流程
【1】客户端将文件拆分成固定大小128M的块,并通知namenode 【2】namenode找到可用的datanode返回给客户端 【3】客户端根据返回的datanode,对块进行写入 【4】通过流水线管道流水线复制 【5】更新元数据,告诉namenode已经完成了创建新的数据块,保证namenode中的元数据都是最新的状态

HDFS读文件流程
【1】客户端向namenode发起读请求,把文件名,路径告诉namenode
【2】namenode查询元数据,并把数据返回客户端
【3】此时客户端就明白文件包含哪些块,这些块在哪些datanode中可以找到

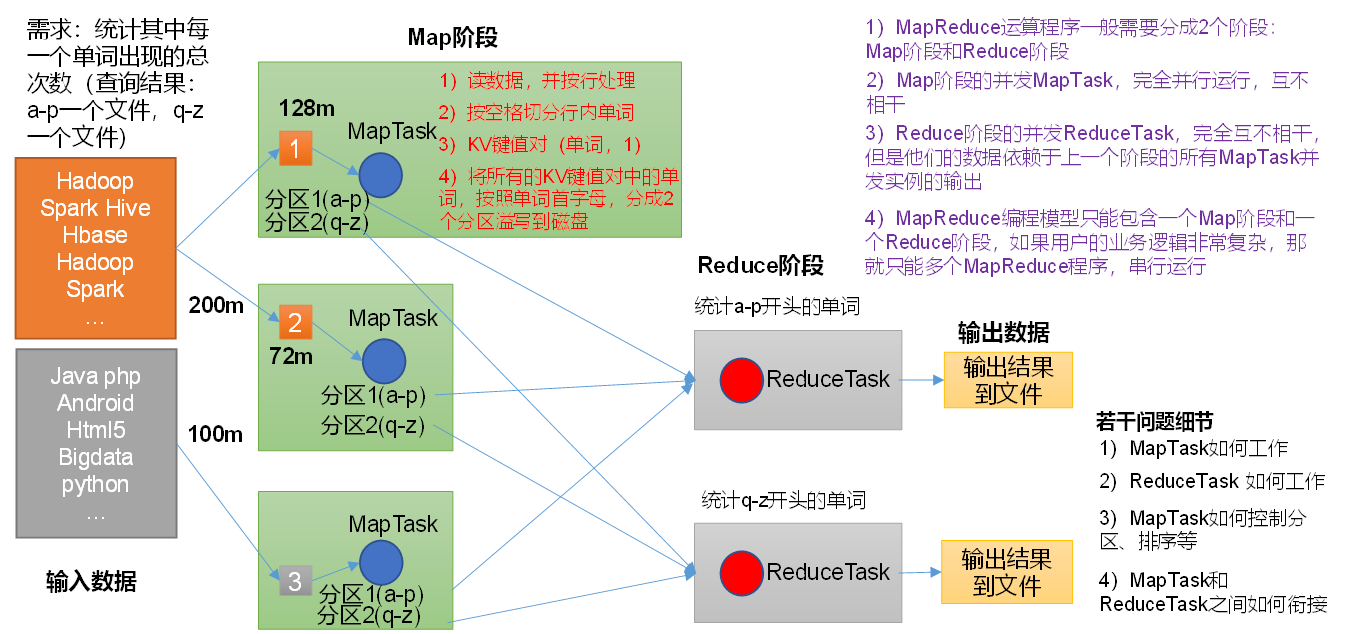
MapReduce
MapReduce实现了分布式计算
Hadoop的MapReduce是对google三大论文的MapReduce的开源实现,实际上是一种编程模型,是一个分布式的计算框架,用于处理海量数据的运算,由JAVA实现
MapReduce角色及概念
JobTracker
–Master节点只有一个
–管理所有作业/任务的监控、错误处理等
–将任务分解成一系列任务,并分派给TaskTracker
TaskTracker
–Slave节点,一般是多台
–运行Map Task和Reduce Task
–并与JobTracker交互,汇报任务状态
Map Task
–解析每条数据记录,传递给用户编写的map()并执行,将结果输出
Reducer Task
–从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行
Yarn
作用:负责整个集群资源的管理和调度,是Hadoop的一个通用的资源管理系统
定义:Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
Yarn角色及概念
Resourcemanager
–处理客户端请求
–启动/监控ApplicationMaster
–监控NodeManager
–资源分配与调度
Nodemanager
–单个节点上的资源管理
–处理来自ResourceManager的命令
–处理来自ApplicationMaster的命令
ApplicationMaster
–为应用程序申请资源,并分配给内部任务
–任务监控与容错
Container
–对任务运⾏行环境的抽象,封装了CPU 、内存等
Client
–用户与Yarn交互的客户端程序
–提交应用程序、监控应用程序状态,杀死应用程序等
用程序申请资源,并分配给内部任务
–任务监控与容错
Container
–对任务运⾏行环境的抽象,封装了CPU 、内存等
Client
–用户与Yarn交互的客户端程序
–提交应用程序、监控应用程序状态,杀死应用程序等