爬取百度热搜的实例
直接上代码
import tkinter as tk
from tkinter import messagebox
import requests
from bs4 import BeautifulSoup
def fetch_data_from_url(url):
try:
response = requests.get(url)
response.raise_for_status() # 确保请求成功
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有具有特定类的div元素
category_divs = soup.find_all('div', class_='category-wrap_iQLoo horizontal_1eKyQ')
# 遍历这些div元素,并找到嵌套元素的innerHTML
results = []
for div in category_divs:
content_div = div.find('div', class_='content_1YWBm')
hot_num = div.find('div', class_='hot-index_1Bl1a')
if content_div:
a_tag = content_div.find('a')
if a_tag:
text_div = a_tag.find('div', class_='c-single-text-ellipsis')
if text_div:
results.append('热搜主题:'+text_div.get_text(strip=True))
if hot_num:
results.append('热搜指数:'+hot_num.get_text(strip=True))
# 换行输出所有结果
return '\n'.join(results)
except (requests.RequestException, Exception) as e:
print(f"发生错误: {e}")
return None
def on_fetch_data():
url = entry_url.get()
if not url:
messagebox.showerror("错误", "请输入有效的网址!")
return
data = fetch_data_from_url(url)
if data:
result_text.delete('1.0', tk.END) # 清空文本框内容
result_text.insert(tk.END, data) # 插入新数据
else:
result_text.insert(tk.END, "无法获取数据,请检查网址或稍后重试。")
# 创建主窗口
root = tk.Tk()
root.title("获取网页数据")
root.geometry("400x400") # 设置窗口大小
# 创建标签和文本框用于输入网址
label_url = tk.Label(root, text="请输入网址:")
label_url.pack()
entry_url = tk.Entry(root,width=100)
entry_url.pack()
# 创建按钮用于获取数据
button_fetch = tk.Button(root, text="获取数据", command=on_fetch_data)
button_fetch.pack()
# 创建文本框用于显示结果
result_text = tk.Text(root, height=20, width=100) # 调整高度和宽度以适应更多内容
result_text.pack()
# 运行主循环
root.mainloop()
在这个代码中,我们定义了一个 fetch_data_from_url 函数,它使用 BeautifulSoup 来解析网页并找到所有具有指定类的 div 元素。然后,它遍历这些 div 元素,查找嵌套的 a 标签和 div.c-single-text-ellipsis,并获取它们的文本内容。最后,它使用换行符 \n 将所有结果连接成一个字符串并返回。
在图形用户界面部分,我们使用了 tk.Text 控件来显示多行文本结果,而不是使用 tk.Label。这样,即使结果很长,也能在文本框中完整显示。在 on_fetch_data 函数中,我们先清空文本框的内容,然后插入新的结果。
请确保替换代码中的类名为网页中实际的类名,因为这些类名可能会根据网页的具体结构而有所不同。如果网页结构发生变化,你可能需要更新选择器以匹配新的结构。
注意,请遵守相关法律法规,以及网站相关规定,合法爬取数据
运行效果
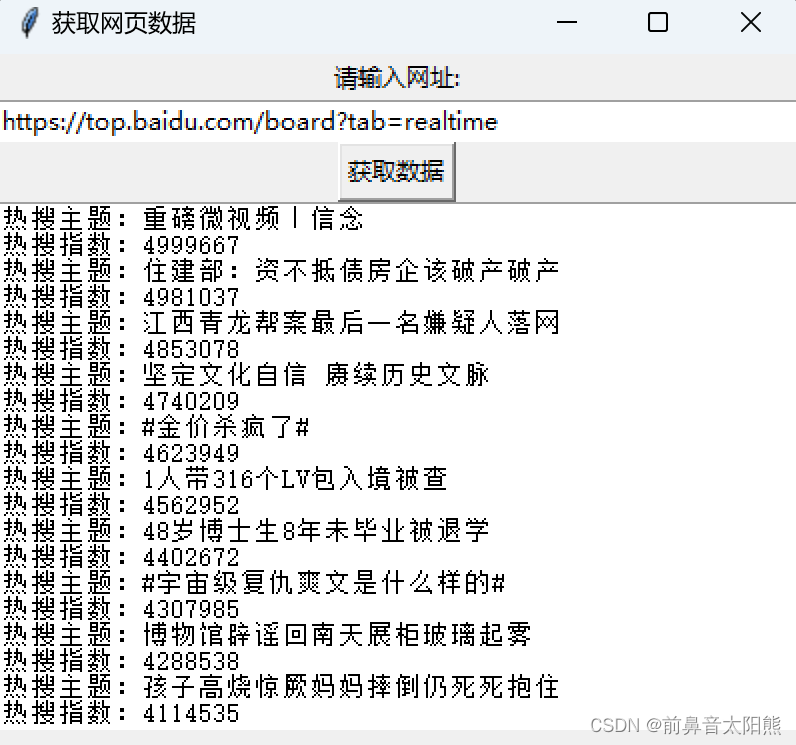
上面就是我们爬取到的运行结果了,可以直接将上述代码作为后台服务,定时采集数据,存入我们自己的的业务数据库,就可以服务于不同的功能模块了。