1、简介
在日常项目开发中,经常会遇到解析excel文件中的数据、或者将某些数据导出成excel文件的需求,目前Java解析、生成Excel比较有名的框架有Apache POI、jxl,但是它们都存在一个严重的问题就是非常的耗内存。POI有一套Sax模式的API可以在一定程度上解决一些内存溢出的问题,但是POI还是有一些缺陷,比如07版Excel解压缩以及解压缩存储都是在内存中完成的,内存消耗依然很大。如果系统并发量不大的话可能还行,但是一旦并发上来以后一定会导致OOM(内存溢出)或者JVM频繁的full gc。
EasyExcel是阿里巴巴提供的一个基于Java的快速、简洁、解决大文件内存溢出的Excel开源处理工具,它重写了POI对07版Excel的解析,一个3M的Excel用POI sax解析依然需要100M左右内存,但是改用EasyExcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
2、使用介绍
EasyExcel能大大减少占用内存的主要原因是在解析excel文件时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。POI与EasyExcel的区别如下:
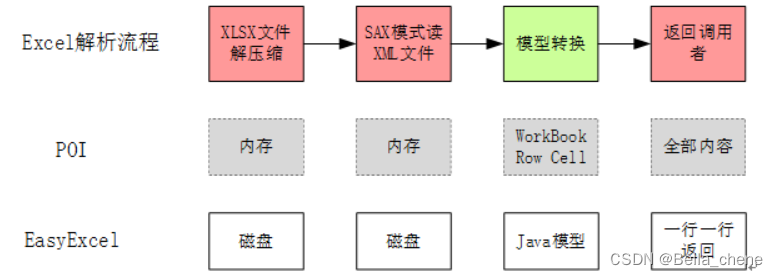
POI是通过WookBook来解析表格文件的,虽然内部有使用到Sax模式,能够大大提高效率,但是要解析大文件(10w、100w行)的话很容易出现OOM(内存溢出)。相比之下:
- EasyExcel的解析是在磁盘上进行的,几乎可以将几mb级别的内存压缩到kb级别,几乎不用担心OOM;
- 用Java模型进行关系映射,通过 @ExcelProperty注解就可以完成行与列的映射;
- EasyExcel中有一个类AnalysisEventListener,里面有一个方法invoke实现了一行一行返回,另外还可以重写该类的doAfterAllAnalysed方法,用来做事后处理之类的操作,相当的灵活。
3、代码实现
在实际使用过程中,首先需要引入Easyexcel的maven依赖。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.5</version>
</dependency>
对象注解@ExcelProperty用于匹配excel和实体类的匹配,参数如下:
名称 |
默认值 |
描述 |
value |
空 |
用于匹配excel中的头,必须全匹配,如果有多行头,会匹配最后一行头 |
order |
Integer.MAX_VALUE |
优先级高于value,会根据order的顺序来匹配实体和excel中数据的顺序 |
index |
-1 |
优先级高于value和order,会根据 |
converter |
自动选择 |
指定当前字段用什么转换器 |
3.1 excel简单读
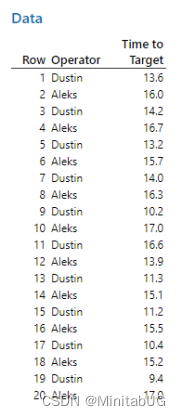
比如读取的excel表头如下:

则对应的数据模型为:
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Data;
@Data
public class CaseInfoDto {
/**
* 案件名称
*/
@ExcelProperty(value = "案件名称", index = 0)
private String caseName;
/**
* 案件类型
*/
@ExcelProperty(value = "案件类型", index = 1)
private String caseType;
/**
* 嫌疑人数
*/
@ExcelProperty(value = "嫌疑人数", index = 2)
private Integer suspectsNum;
/**
* 案件状态
*/
@ExcelProperty(value = "案件状态", index = 3)
private String caseStatus;
/**
* 发案时间
*/
@ExcelProperty(value = "发案时间", index = 4)
private String happenTime;
/**
* 发案地点
*/
@ExcelProperty(value = "发案地点", index = 5)
private String location;
}在读的时候,推荐使用index进行映射,因为有时候我们拿到的excel文件其表头文字可能会非常长,此时用value显示不适合。如果Java类中的属性字段顺序和Excel中的表头字段顺序完全一致, 甚至可以不写@ExcelProperty注解也能顺利解析。
读取excel的关键是写一个监听器,实现ReadListener,如下所示是ReadListener的源码,每解析一行数据就会调用invoke()方法返回解析的数据,当全部解析完成后会调用doAfterAllAnalysed()方法,因为我们只需要重写这两个方法即可。
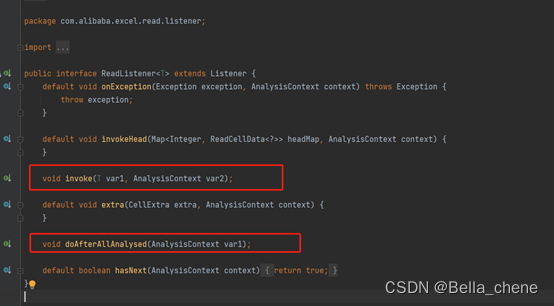
下面介绍几种监听器实现的方案:
第一种:手动实现ReadListener
如下所示是自定义的监听器,每解析到一条数据判断案例名称是否为空,如果不为空才加入到结果集中,最后全部解析完毕后,分批入库。
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.hikvision.ga.common.BusinessException;
import com.hikvision.js.ctm01visual.entity.dto.CaseInfoDto;
import com.hikvision.js.ctm01visual.exception.ErrorCode;
import com.hikvision.js.ctm01visual.mapper.CaseInfoMapper;
import com.hikvision.js.ctm01visual.util.ApplicationContextUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.context.annotation.DependsOn;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @ClassName EasyExcelDataListener
* @Description
* @Author
* @Date 2023/4/21 9:36
* @Version 1.0
**/
@Slf4j
@Component
@DependsOn("applicationContextUtils")
public class DemoDataListener1 implements ReadListener<CaseInfoDto> {
/**
* 结果集
*/
List<CaseInfoDto> resultList = new ArrayList<>();
/**
* 每执行一条数据操作一次
* @param
* @param analysisContext
*/
@Override
public void invoke(CaseInfoDto caseInfoDto, AnalysisContext analysisContext) {
//只有名称不为空才保存
if (!StringUtils.isEmpty(caseInfoDto.getCaseName())) {
resultList.add(caseInfoDto);
}
}
/**
* 解析完成后进行的操作
* @param analysisContext
*/
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("本次共导入{}条点位信息", resultList.size());
batchInsertCaseInfo(resultList);
}
private void batchInsertCaseInfo(List<CaseInfoDto> list) {
//要使用该方式注入,不能使用@Resource注入
CaseInfoMapper caseInfoMapper = (CaseInfoMapper) ApplicationContextUtils.getBean("caseInfoMapper");
int size = list.size();
int offset = 0;
try {
while (offset < size) {
List<CaseInfoDto> tempList = list.stream().skip(offset).limit(500).collect(Collectors.toList());
offset += 500;
caseInfoMapper.insertBatch(tempList);
}
} catch (Exception e) {
log.error(ErrorCode.ERR_DATA_INSERT.getCode(), ErrorCode.ERR_DATA_INSERT.getMsg(), e);
throw new BusinessException(ErrorCode.ERR_DATA_INSERT.getCode(), ErrorCode.ERR_DATA_INSERT.getMsg(), e);
}
}
}
读excel的代码:
@Override
public void importCaseInfo(MultipartFile file) {
try {
//第一种:采用固定的监听器,全部解析完后再入库处理
EasyExcel.read(file.getInputStream(), CaseInfoDto.class, new DemoDataListener1()).sheet().doRead();
} catch (Exception e) {
log.error("解析excel失败:", e);
}
}
但是该方法是错误使用easyexcel的典型例子,虽然可以正常解析,但是存在以下几点问题:
(1)将全部excel的数据解析完成保存在内存中,最后入库,那么当数据量非常大的时候,仍然会导致OOM的问题。
(2)由于依赖注入的前后关系,无法使用@Resource注入其他的实例,只能通过ApplicationContextUtils.getBean()的方式去获取。
(3)如果一个项目中需要导入多个不同的excel文件,就要对应写多个监听器,不通用。
基于以上考虑,采用固定方式的监听器不推荐使用。
第二种:使用较为通用的监听器,且解析到一定条数的数据后就入库
使用泛型,并定义数据校验predicate和数据消费的consumer,将校验方式和消费方式通过构造器传入,实现多变的数据校验和消费方式。
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Predicate;
/**
* @ClassName EasyExcelDataListener
* @Description
* @Author
* @Date 2023/4/21 9:36
* @Version 1.0
**/
@Slf4j
public class DemoDataListener2<T> implements ReadListener<T> {
/**
* 结果集
*/
private List<T> resultList ;
/**
* 每满500条进行一次入库操作
*/
private int BATCH_COUNT = 500;
/**
* 校验数据
*/
private Predicate<T> predicate;
/**
* 满足 BATCH_COUNT 条后数据应该进行的操作
*/
private Consumer<List<T>> consumer;
/**
* 读取每一条数据进行predicate操作,
* 读取到count行数进行consumer操作
* @param count 读取的行数
* @param predicate 读取一条数据执行的方法。例:校验数据规则
* @param consumer 读取规定行数后执行的方法
*/
public DemoDataListener2(int count, Predicate<T> predicate, Consumer<List<T>> consumer) {
BATCH_COUNT = count;
this.consumer = consumer == null ? ts -> {
} : consumer;
this.predicate = predicate == null ? t -> true : predicate;
resultList = new ArrayList<>(BATCH_COUNT);
}
/**
* 每执行一条数据操作一次
* @param
* @param analysisContext
*/
@Override
public void invoke(T data, AnalysisContext analysisContext) {
log.debug("解析到一条数据:{}", JSON.toJSONString(data));
//对数据进行校验,如果不需要操作,直接注释即可
if (!predicate.test(data)) {
return;
}
//满足条件后加入列表中
resultList.add(data);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (resultList.size() >= BATCH_COUNT) {
consumer.accept(resultList);
resultList.clear();
}
}
/**
* 解析完成后进行的操作
* @param analysisContext
*/
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
//将最后一次的数据处理掉
if (resultList.size()>0) {
consumer.accept(resultList);
}
log.info("解析excel数据完成");
}
}
此时的invoke()方法中先进行数据校验,符合条件后加入结果集,当结果集数据条数到达规定的量后,直接消费入库存储,然后将结果集resultList清空,防止过多数据保留在内存中造成OOM。当所有数据解析完成后,再将最后存储在内存的一部分数据入库。
该方式通过边解析边消费的方式,解决大批量数据下可能存在的OOM问题,且采用泛型,如果多个excel解析时,只要生成不同的predicate和consumer传入即可实现不同excel的解析。
上述监听器可采用更简单的实现方式,编写一个工具类,根据传入的consumer生成一个AnalysisEventListener对象,从而让代码更简洁。
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import java.util.LinkedList;
import java.util.List;
import java.util.function.Consumer;
/**
* className EasyExcelUtils
* description easyexcel监听器优化
*
* <p>
* 原始监听器:
*(1)每次解析不同数据模型都要新增一个监听器, 重复工作量大;
* (2)即使用了匿名内部类,程序也显得臃肿;
* (3)数据处理一般都会存在于项目的service中, 监听器难免会依赖dao层, 导致程序耦合度高.
* 解决方案:
* (1)通过泛型指定数据模型类型, 针对不同类型的数据模型只需要定义一个监听器即可;
* (2)使用jdk8新特性中的函数式接口, 将数据处理从监听器中剥离出去, 进行解耦
* </p>
*
* @author
* @version 1.0
* @date 2023/7/26 15:38
**/
public class EasyExcelUtils {
/**
* 获取读取Excel的监听器对象
* 为了解耦及减少每个数据模型bean都要创建一个监听器的臃肿, 使用泛型指定数据模型类型
* 使用jdk8新特性中的函数式接口 Consumer
* 可以实现任何数据模型bean的数据解析, 不用重复定义监听器
* @param consumer 处理解析数据的函数, 一般可以是数据入库逻辑的函数
* @param threshold 阈值,达到阈值就处理一次存储的数据
* @param <T> 数据模型泛型
* @return 返回监听器
*/
public static <T> AnalysisEventListener<T> getReadListener(Consumer<List<T>> consumer, int threshold) {
return new AnalysisEventListener<T>() {
/**
* 存储解析的数据 T t
*/
// ArrayList基于数组实现, 查询更快
// List<T> dataList = new ArrayList<>(threshold);
// LinkedList基于双向链表实现, 插入和删除更快
List<T> dataList = new LinkedList<>();
/**
* 每解析一行数据事件调度中心都会通知到这个方法, 订阅者1
* @param data 解析的每行数据
* @param context
*/
@Override
public void invoke(T data, AnalysisContext context) {
dataList.add(data);
// 达到阈值就处理一次存储的数据
if (dataList.size() >= threshold) {
consumer.accept(dataList);
dataList.clear();
}
}
/**
* excel文件解析完成后,事件调度中心会通知到该方法, 订阅者2
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 最后阈值外的数据做处理
if (dataList.size() > 0) {
consumer.accept(dataList);
}
}
};
}
/**
* 获取读取Excel的监听器对象, 不指定阈值, 默认阈值为 2000
* @param consumer
* @param <T>
* @return
*/
public static <T> AnalysisEventListener<T> getReadListener(Consumer<List<T>> consumer) {
return getReadListener(consumer, 2000);
}
}
此时读excel的代码:
@Override
public void importCaseInfo(MultipartFile file) {
try {
//第二种:采用较为通用的监听器,每解析count条数据后就入库
EasyExcel.read(file.getInputStream(), CaseInfoDto.class, new DemoDataListener2<>(500, dataCheck(), dataProcess())).sheet().doRead();
//采用工具类
EasyExcel.read(file.getInputStream(), CaseInfoDto.class, EasyExcelUtils.getReadListener(dataProcess(), 500)).sheet().doRead();
} catch (Exception e) {
log.error("解析excel失败:", e);
}
}第三种:使用Easyexcel提供的官方自定义的监听器器
Easyexcel提供了一个官方自定义的监听器PageReadListener,该监听器默认每解析到100条数据就消费一次,无法自定义修改BATCH_COUNT值。该方法的源码如下:
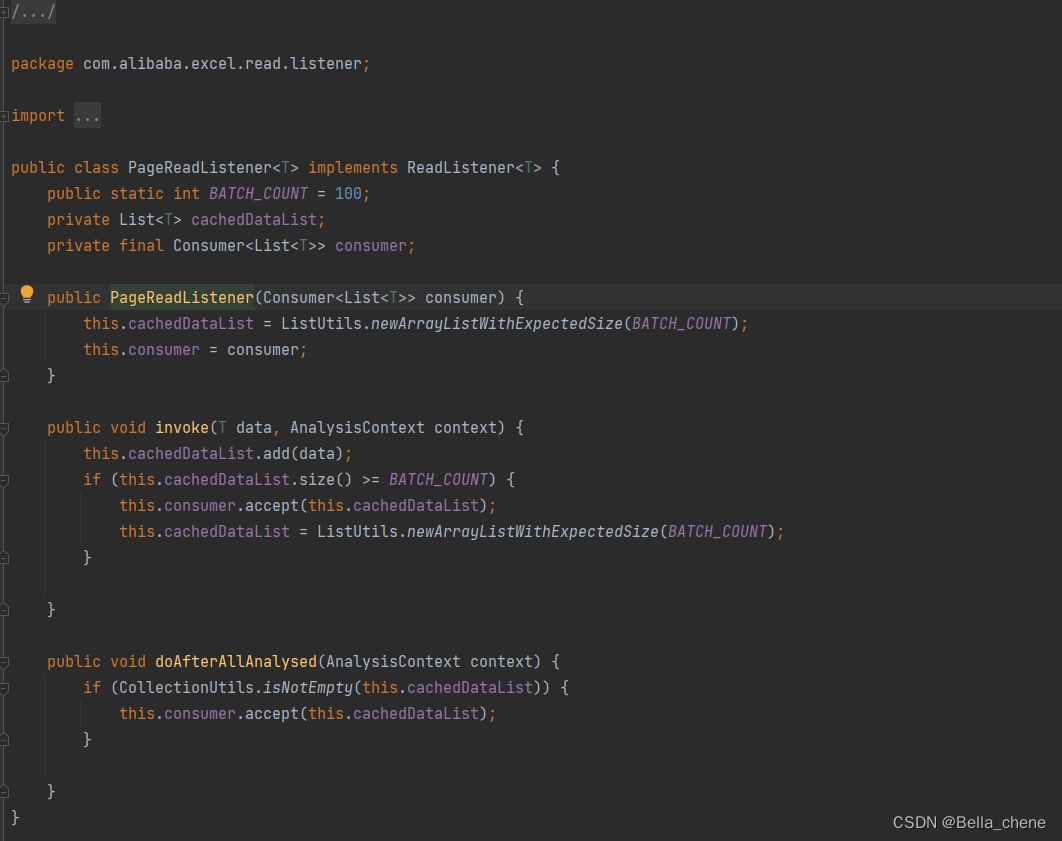
此时读excel的代码是:
@Override
public void importCaseInfo(MultipartFile file) {
try {
//第三种:采用官方自定义的监听器,每解析100条数据就入库
EasyExcel.read(file.getInputStream(), CaseInfoDto.class, new PageReadListener<>(dataProcess())).sheet(1).doRead();
} catch (Exception e) {
log.error("解析excel失败:", e);
}
}如果一个excel有多个sheet,可以在sheet()中指定读取某个sheet即可。

3.2 excel简单写
相对于读需要自定义监听器,easyexcel的写就简单多了,只要建立好实体类的映射后,直接使用EasyExcel.write()方法即可。
@Override
public void exportExcel(HttpServletResponse response) throws IOException {
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHHmmss");
String fileName = "测试easyexcel_" + df.format(new Date());
fileName = URLEncoder.encode(fileName, "UTF-8");
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName+".xlsx");
//全部结果
List<DeviceInfoDto> assetMatchResultList = queryAll();
ServletOutputStream outputStream = response.getOutputStream();
//写入excel
EasyExcel.write(outputStream, DeviceInfoDto.class)
.sheet("测试结果")
.doWrite(assetMatchResultList);
}读的过程通常会遇到数据转换,比如常用的人员性别,1表示男,2表示女性,0表示未知,那么数据库中存储的是通常是0,1,2这样的数字,而导出成excel文件的时候需要切换成对应的“未知”“男”“女”。前面我们说到@ExcelProperty注解的converter属性,就是进行转换用的,写的时候只要实现Converter接口中的convertToExcelData()方法即可。
import com.alibaba.excel.converters.Converter;
import com.alibaba.excel.converters.ReadConverterContext;
import com.alibaba.excel.converters.WriteConverterContext;
import com.alibaba.excel.enums.CellDataTypeEnum;
import com.alibaba.excel.metadata.GlobalConfiguration;
import com.alibaba.excel.metadata.data.ReadCellData;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.metadata.property.ExcelContentProperty;
import io.swagger.models.auth.In;
/**
* className SexConverter
* description
*
* @author
* @version 1.0
* @date 2023/10/20 11:17
**/
public class SexConverter implements Converter<Integer> {
@Override
public WriteCellData<?> convertToExcelData(Integer value, ExcelContentProperty contentProperty, GlobalConfiguration globalConfiguration) {
switch (value) {
case 1:
return new WriteCellData<>("男");
case 2:
return new WriteCellData<>("女");
default:
return new WriteCellData<>("未知");
}
}
}
然后在实体类上添加这个转换器。即可轻松实现数据转换。

同样的,在读excel的时候也可以进行转化,可以看下Converter接口的源码,其中convertToJavaData()方法就是用于读的时候进行转化的。
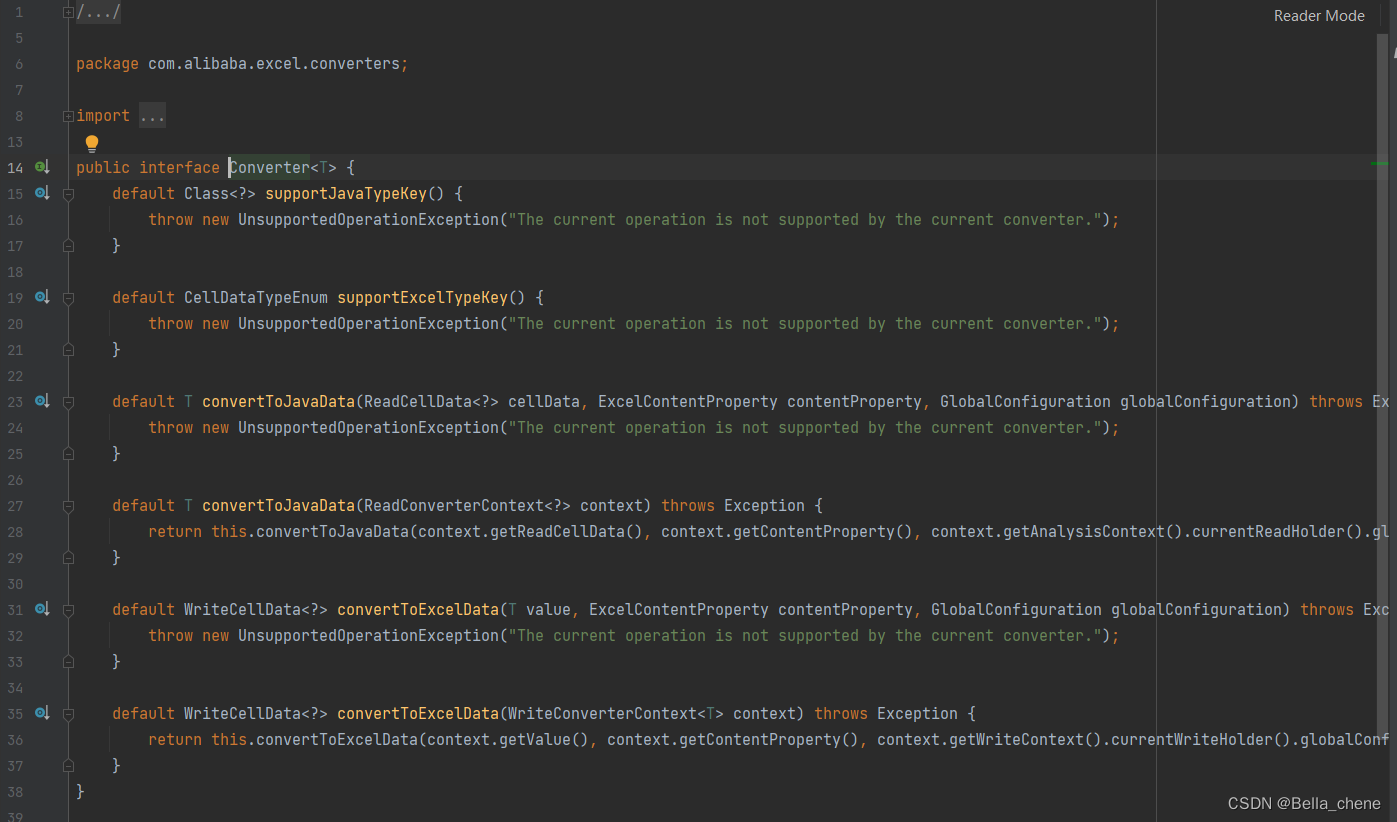
4、总结
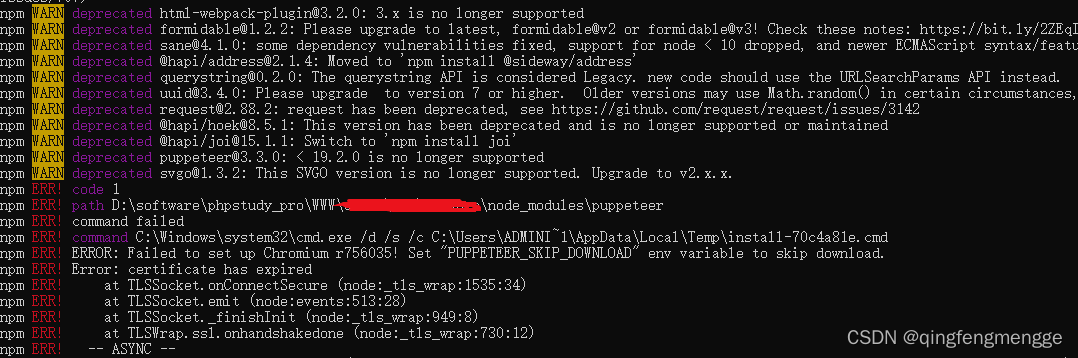
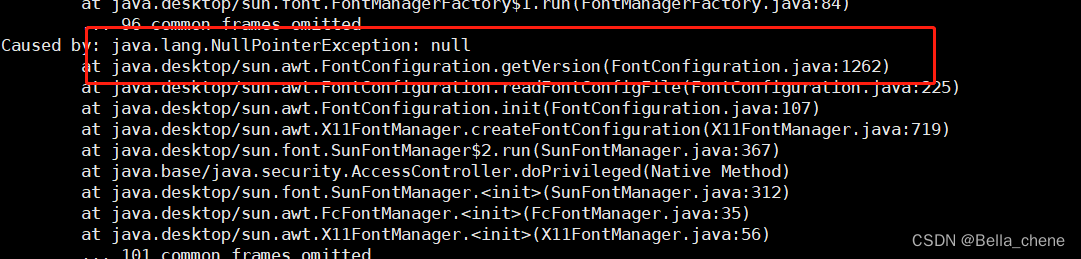
在实际项目使用过程中,postman测试导出接口成功且文件能正常打开,但是将组件部署到服务器上使用导出功能时,导出的报表打不开,提示如下错误:

查看组件的debug日志,发现报了一个FontConfiguration.getVersion()的错误。
且在多个服务器上都出现过该问题。这个因为服务器上没有安装字体包导致的,总结的完整解决办法如下:
Xshell连接组件安装的服务器,执行:
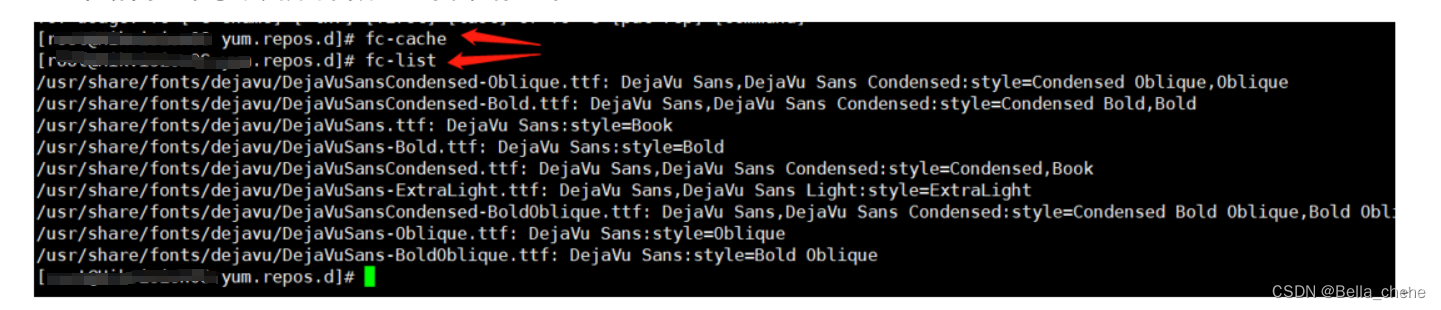
a. 安装字体包:yum -y install fontconfig
b. 刷新内存中的字体缓存: fc-cache
c. 查看字体是否安装成功(有一种即可): fc-list
d. 重启代码运行(不必重启服务器)
通常即可解决该问题,但是如果:在执行a步骤后出现下述错误:
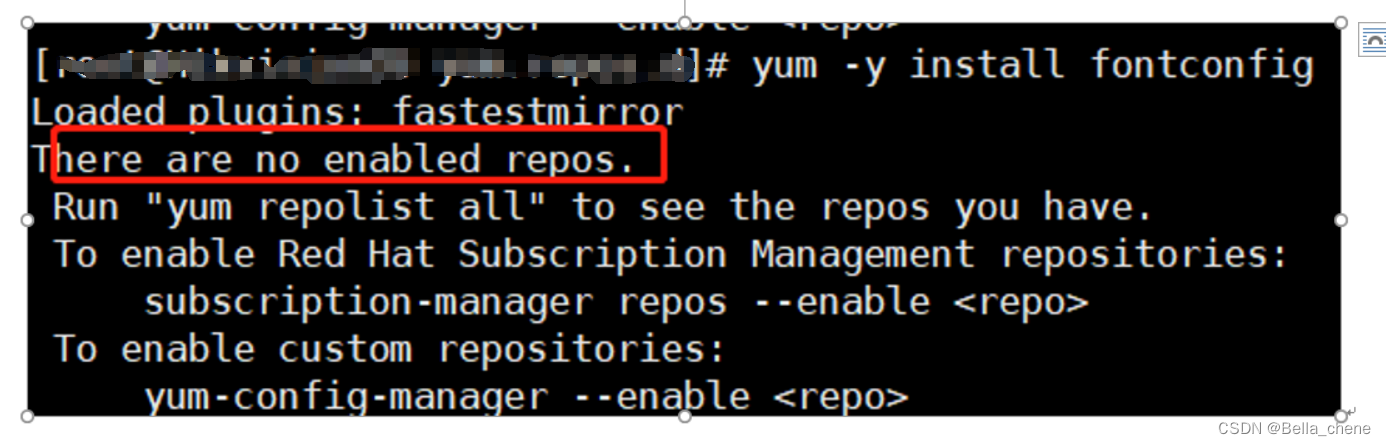
需要:
a.a进入目录:cd /etc/yum.repos.d/
a.b备份原始文件:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
若是找不到yum.repos.d文件夹,用mkdir创建一一个:mkdir /etc/yum.repos.d即可
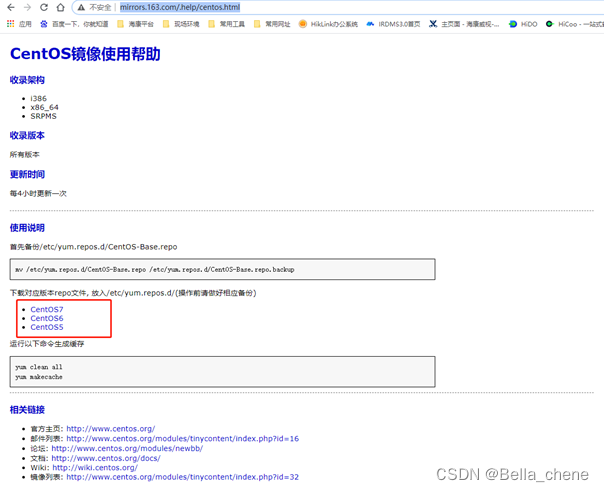
a.c下载对应版本的repo文件:访问网址CentOS镜像使用帮助,根据服务器CentOS版本下载对应版本即可。
a.d将新的repo文件放到 /etc/yum.repos.d 目录下,使用ll查看目录下的文件,可见多了一个备份文件和新的repo文件。

a.e继续执行a中的安装字体包的操作
如果:新报出下面这个错误

则:修改resolve.conf文件:cd /etc、vim resolv.conf,在后面加入nameserver 8.8.8.8,保存。
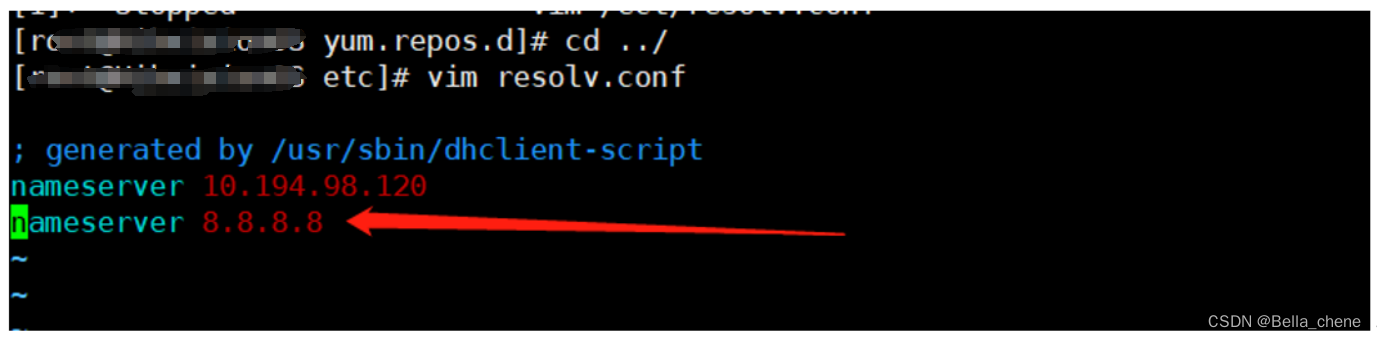 继续执行a中的操作,等待一段时间后,直到出现Complete!即可。
继续执行a中的操作,等待一段时间后,直到出现Complete!即可。

正常情况下安装成功后的界面如下:
注意:以上所有操作均在root用户下执行。操作完成后重启组件后,新导出一次excel,即可成功打开。
EasyExcel作为轻量级快速、简洁、解决大文件内存溢出的java处理Excel工具,还有很多其他的读写操作功能,比如复杂表头的读取、获取excel额外信息如批注、超链接、合并单元格等等。本文中只介绍了最为简单的读写方式,读者可根据实际项目需求实现其他复杂功能,可参考官方网址:EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel。