1.hadoop 配置文件 core-site hdfs-site yarn-site.xml worker
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>xiemeng-01:9870</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>xiemeng-02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>xiemeng-01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>xiemeng-02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xiemeng-01:8485;xiemeng-02:8485;xiemeng-03:8485/mycluster</value>
</property>
<!--配置journalnode的工作目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/xiemeng/software/hadoop-3.2.0/journalnode/data</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/xiemeng/software/hadoop-3.2.0/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/xiemeng/software/hadoop-3.2.0/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalnode/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.64.128:2181,192.168.64.130:2181,192.168.64.131:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xiemeng/software/hadoop-3.2.0/var</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establisha server connection.</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait forbefore retrying to establish a server connec
tion.
</description>
</property>
<property>
<name>hadoop.proxyuser.xiemeng.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.xiemeng.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>xiemeng-01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>xiemeng-02</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>xiemeng-01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>xiemeng-02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.64.128:2181,192.168.64.130:2181,192.168.64.131:2181</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程查询每个任务使用的虚拟内存量,如果任务超出内存值直接杀掉,默认为true-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- 开启标签功能 -->
<property>
<name>yarn.node-labels.enabled</name>
<value>true</value>
</property>
<!-- 设置标签存储位置-->
<property>
<name>yarn.node-labels.fs-store.root-dir</name>
<value>hdfs://mycluster/yn/node-labels/</value>
</property>
<!-- 开启资源抢占监控 -->
<property>
<name>yarn.resourcemanager.scheduler.monitor.enable</name>
<value>true</value>
</property>
<!-- 设置一轮抢占的资源占比,默认为0.1 -->
<property>
<name>yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round</name>
<value>0.3</value>
</property>
</configuration>workers
xiemeng-01
xiemeng-02
xiemeng-03<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/xiemeng/software/hadoop-3.2.0/etc/hadoop,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/common/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/common/lib/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/hdfs/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/hdfs/lib/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/mapreduce/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/mapreduce/lib/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/yarn/*,
/home/xiemeng/software/hadoop-3.2.0/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.leaf-queue-template.ordering-policy</name>
<value>fair</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,low</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.maximum-capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.default-application-priority</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.default-application-priority</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.acl_administer_queue</name>
<value>xiemeng,root</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.low.acl_submit_applications</name>
<value>xiemeng,root</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>xiemeng,root</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>xiemeng,root</value>
</property>
</configuration>
Hadoop
启动Hadoop集群:
Step1 : 在各个JournalNode节点上,输入以下命令启动journalnode服务: sbin/hadoop-daemon.sh start journalnode
Step2: 在[nn1]上,对其进行格式化,并启动: bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode
Step3: 在[nn2]上,同步nn1的元数据信息: hdfs namenode -bootstrapStandby
查看执行任务日志
yarn logs -applicationId application_1607776903207_0002
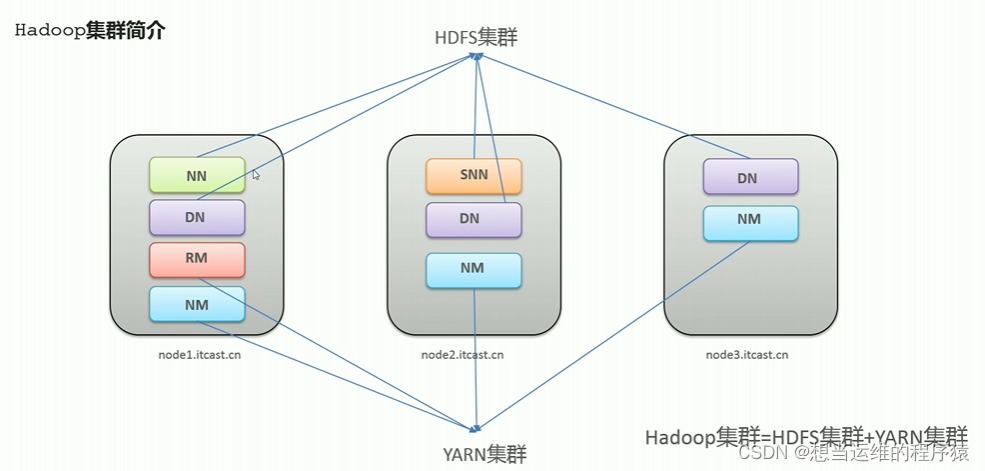
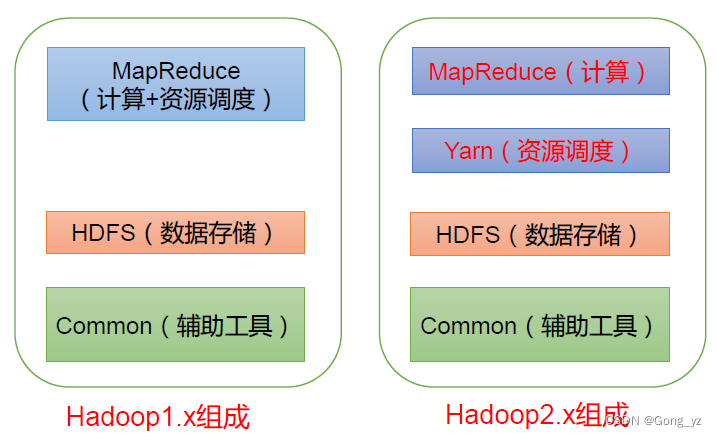
2. 基本架构 jobMannager resourceManager TaskMananger 一些流程
3.hadoop 命令行操作
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>
hadoop hdfs dfs –put [本地目录] [hadoop目录]
hadoop fs -mkdir -p < hdfs dir >3.hadoop java 操作
Mapper,Reducer,InputFormat OutPutFormat Comparator Partition Comperess
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
/**
* 初始化
*
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
/**
*
* 用户业务
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String str = value.toString();
String [] words = StringUtils.split(str);
for(String word:words){
context.write(new Text(word),new LongWritable(1));
}
}
/**
* 清理资源
*
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count =0;
for(LongWritable value:values){
count += value.get();
}
context.write(key,new LongWritable(count));
}
}
public class WordCountDriver {
public static void main(String[] args) {
Configuration config = new Configuration();
System.setProperty("HADOOP_USER_NAME", "xiemeng");
config.set("fs.defaultFS","hdfs://192.168.64.128:9870");
config.set("mapreduce.framework.name","yarn");
config.set("yarn.resourcemanager.hostname","192.168.64.128");
config.set("mapreduce.app-submission.cross-platform", "true");
config.set("mapreduce.job.jar","file:/D:/code/hadoop-start-demo/target/hadoop-start-demo-1.0-SNAPSHOT.jar");
try {
Job job = Job.getInstance(config);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountCombiner.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job,new Path("/wordcount2/output"));
instance.setGroupingComparatorClass(OrderGroupintComparator.class);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
boolean complete = job.waitForCompletion(true);
System.exit(complete ? 0:1);
} catch (Exception e) {
e.printStackTrace();
}
}public class OrderGroupintComparator extends WritableComparator {
public OrderGroupintComparator() {
super(OrderBean.class,true);
}
@Override
public int compare(Object o1, Object o2) {
OrderBean orderBean = (OrderBean) o1;
OrderBean orderBean2 = (OrderBean)o2;
if(orderBean.getOrderId() > orderBean2.getOrderId()){
return 1;
}else if(orderBean.getOrderId() < orderBean2.getOrderId()){
return -1;
}else {
return 0;
}
}
}
public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
CustomWriter customWriter = new CustomWriter(taskAttemptContext);
return customWriter;
}
protected static class CustomWriter extends RecordWriter<Text, NullWritable> {
private FileSystem fs;
private FSDataOutputStream fos;
private TaskAttemptContext context;
public CustomWriter(TaskAttemptContext context) {
this.context = context;
}
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
fs = FileSystem.get(context.getConfiguration());
String key = text.toString();
Path path = null;
if (StringUtils.startsWith(key, "137")) {
path = new Path("file:/D:/hadoop/output/format/out/137/");
} else {
path = new Path("file:/D:/hadoop/output/format/out/138/");
}
fos = fs.create(path,true);
byte[] bys = new byte[text.getLength()];
fos.write(text.toString().getBytes());
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeQuietly(fos);
IOUtils.closeQuietly(fs);
}
}
}public class WholeFileInputFormat extends FileInputFormat<Text, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
WholeRecordReader reader = new WholeRecordReader();
reader.initialize(inputSplit, taskAttemptContext);
return reader;
}
}@Data
public class FlowBeanObj implements Writable, WritableComparable<FlowBeanObj> {
private long upFlow;
private long downFlow;
private long sumFlow;
@Override
public int compareTo(FlowBeanObj o) {
if(o.getSumFlow() > this.getSumFlow()){
return -1;
}else if(o.getSumFlow() < this.getSumFlow()){
return 1;
}else {
return 0;
}
}
}
public class WholeRecordReader extends RecordReader<Text, BytesWritable> {
private Configuration config;
private FileSplit fileSplit;
private boolean isProgress = true;
private BytesWritable value = new BytesWritable();
private Text k = new Text();
private FileSystem fs;
private FSDataInputStream fis;
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException, InterruptedException {
fileSplit = (FileSplit) inputSplit;
this.config = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
try {
if (isProgress) {
byte[] contents = new byte[(int) fileSplit.getLength()];
Path path = fileSplit.getPath();
fs = path.getFileSystem(config);
fis = fs.open(path);
IOUtils.readFully(fis,contents, 0,contents.length);
value.set(contents, 0, contents.length);
k.set(fileSplit.getPath().toString());
isProgress = false;
return true;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
IOUtils.closeQuietly(fis);
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return k;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
fis.close();
fs.close();
}
}public class HdfsClient {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration config = new Configuration();
config.set("fs.defaultFS","hdfs://localhost:9000");
config.set("dfs.replication","2");
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"),config,"xieme");
fs.mkdirs(new Path("/hive3"));
fs.copyFromLocalFile(new Path("file:/d:/elasticsearch.txt") ,new Path("/hive3"));
fs.copyToLocalFile(false,new Path("/hive3/elasticsearch.txt"), new Path("file:/d:/hive3/elasticsearch2.txt"));
fs.rename(new Path("/hive3/elasticsearch.txt"),new Path("/hive3/elasticsearch2.txt"));
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/"), true);
while(locatedFileStatusRemoteIterator.hasNext()){
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.print(next.getPath().getName()+"\t");
System.out.print(next.getLen()+"\t");
System.out.print(next.getGroup()+"\t");
System.out.print(next.getOwner()+"\t");
System.out.print(next.getPermission()+"\t");
System.out.print(next.getPath()+"\t");
BlockLocation[] blockLocations = next.getBlockLocations();
for(BlockLocation queue: blockLocations){
for(String host :queue.getHosts()){
System.out.print(host+"\t");
}
}
System.out.println("");
}*/
//fs.delete(new Path("/hive3"),true);
/*FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for(FileStatus fileStatus:fileStatuses){
if(fileStatus.isDirectory()){
System.out.println(fileStatus.getPath().getName());
}
}*/
// 流copy
FileInputStream fis = new FileInputStream("d:/elasticsearch.txt");
FSDataOutputStream fos = fs.create(new Path("/hive/elasticsearch.txt"));
IOUtils.copyBytes(fis,fos, config);
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
FSDataInputStream fis2 = fs.open(new Path("/hive/elasticsearch.txt"));
FileOutputStream fos2 = new FileOutputStream("d:/elasticsearch.tar.gz.part1");
fis2.seek(1);
IOUtils.copyBytes(fis2,fos2,config);
/*byte [] buf = new byte[1024];
for(int i=0; i<128;i++){
while(fis2.read(buf)!=-1){
fos2.write(buf);
}
}*/
IOUtils.closeStream(fis2);
IOUtils.closeStream(fos2);
fs.close();
}
}3. hadoop 优化