什么是神经网络
机器学习和神经网络
机器学习(Machine Learning)
- 学习数据
- 解决和预测有关的问题
- 可以不断改进
人工智能(Artificial Intelligence),机器学习,深度学习(Deep Learning)的关系:人工智能 > 机器学习 > 深度学习。(">"表示包含)
而神经网络是深度学习中才用到的:深度学习基于神经网络(更准确地说是人工神经网络, ANN)
生物神经网络(Biological Neural Network)
神经元(neuron)
中间神经元(Interneuron):用于处理信息
人工神经网络(Artificial Neural Network)
人工神经元(Artificial Neuron)是一个数学函数。每一个“神经元”接收带权重的输入,求和,然后将其通过一个非线性的函数(称为激活函数,Activation Function)传递给其输出。
单层感知机(Single-Layer Perceptron,SLP)
最简单的ANN。有多个输入,一个输出的人工神经元。单层是指仅包含一个计算结点。
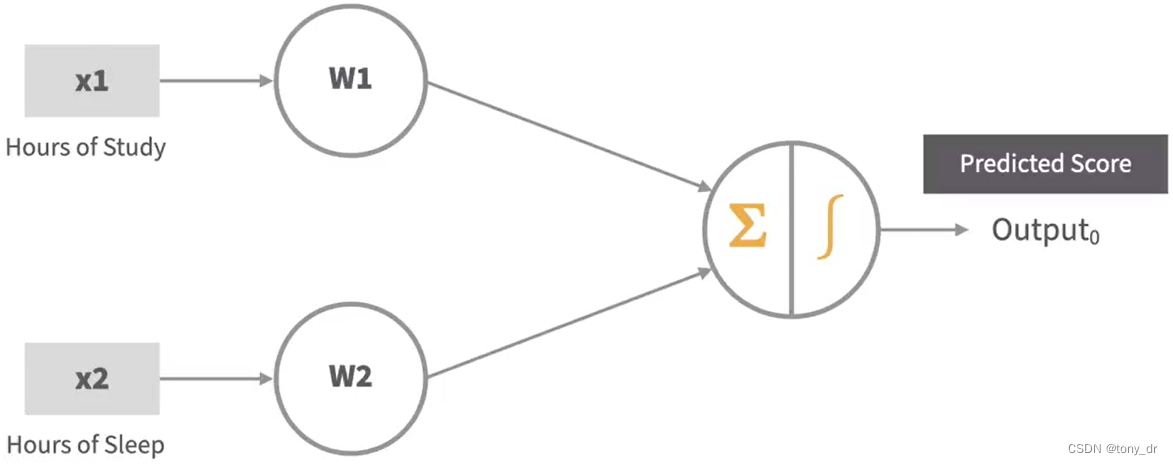
感知机包含以下元素:
- 一个输入层
- 权重和偏好
- 网络求和
- 传递函数(Transfer Function)和激活函数
神经网络的关键组成
本节介绍的实际上是最基本的前馈神经网络(Feed-Forward Neural Network,FNN)
多层感知机(Multilayer Perceptron, MLP)
- 是一种前馈网络(Feed-forwad NNetwork)
- 多层感知机,至少包含三层神经元(或者结点):1个输出层,1个隐藏层,1个输出层
- 每一层的一个感知机和下一层的多个感知机相连
- 每一个感知机的输出作为下一个感知机的输入
SLP只能学习带标签的数据,MLP可以学些带标签和不带标签的数据
根据层数多少,一般可以分为:
- 浅层神经网络(Shallow Neural Network):只有一个隐藏层的神经网络
- 深度神经网络(Deep Neural Network):一般有3个或更多的隐藏层
层:输入,隐藏和输出
- 输入层没有任何计算,仅仅接收输入数据,并传递给隐藏层
- 隐藏层位于输入层和输出层之间,执行计算
- 输出层给出预测结果
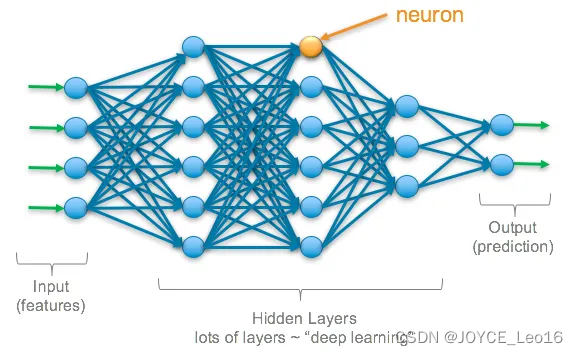
传递和激活函数
传递函数:使用权重和偏好对当前层的结点进行求和计算的函数
激活函数:是一种特殊的传递函数,主要目的是为模型引入非线性。
常用激活函数:ReLU, Sigmoid, Tanh
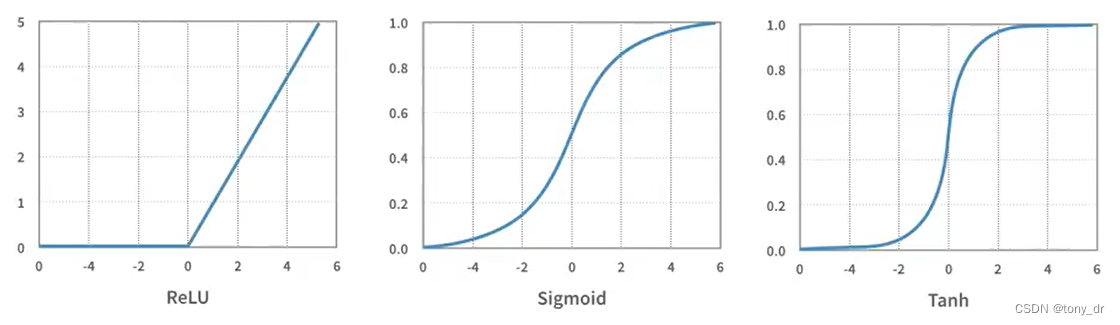
更多的激活函数可以参考这篇文章:
神经网络怎样学习
以回归(Regression)问题为例
- 根据当前的权重,偏好计算预测值y_hat
- 使用损失函数(Loss Function)计算标签值(label,即真实采样结果)和预测值y_hat之间的差异
- 使用反向传播(Back Propagation)更新权重和偏好
- 循环以上过程,使得预测结果不断接近标签值。这个过程就是学习
其它几种常用的神经网络
卷积神经网络(Convolutional Neural Network,CNN)
典型使用场景:
- 图像识别
- 物体识别
- 社交媒体人脸识别
- 医学图像分析
为什么不能使用经典的前馈神经网络:像素点+三原色带来的输入数据量太大
CNN有五个种类的层:
- 输入层
- 卷积层(Convolutional layer)
- 汇聚层(Pooling layer,也有翻译为池化层)
- 全连接输入层(Fully-Connected input layer)
- 全连接输出层(Fully-Connected output layer)
其中,输入层,卷积层和汇聚层用于提取图像特征。
卷积层,承载了CNN的主要计算部分,它包含输入数据,过滤器,和特征图。它会通过不同的过滤器提取图像中不同的特征,例如脸颊,耳朵,鼻子,眼睛等等。
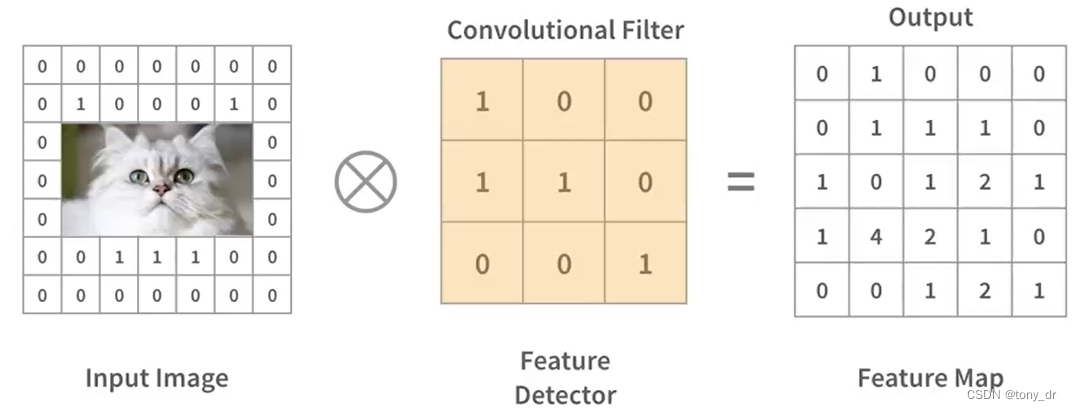
汇聚层,会卷积层产生的结果,提取一个小矩形块的数据,并对这个小矩形块的数据进行子采样,从而得到一个输出。常用的汇聚层算法有:取最大值,取平均值,取线性组合等。经过汇聚层的处理后,每一个小矩形块的数据最终化为一个输出数据,因此汇聚层会降低输入数据量的大小。这也是汇聚层的重要目的之一:减少参数规模,降低运算量。

全连接层输入层,将汇聚层之后产生的矩形数据块展开成一个向量,然后使用经典的神经网络,得到分类问题的结果。全连接层(包括全连接输入层和全连接输出层)一般放在CNN的最后。

循环神经网络(Recurrent Neural Network,RNN)
序列数据(Sequential Data):是一种无结构的数据(Unstructured Data),数据集中的某些点依赖于这个数据集中的其它点,即数据是有顺序的。序列数据包含文本流(text streams),音频剪辑(audio clips),视频剪辑(vedio clips),语音识别(speech recognition),时间序列数据(time series data)等等。
为什么不能使用经典的前馈神经网络:只考虑当前层的输入,不能记住以前的输入,因此不能处理有顺序的数据。
RNN背后的原理是:通过传递一系列带有顺序的数据来训练网络。一旦训练完后,可以预测在当前数据之后、大概率出现的新数据。例如,有如下两个句子用于训练
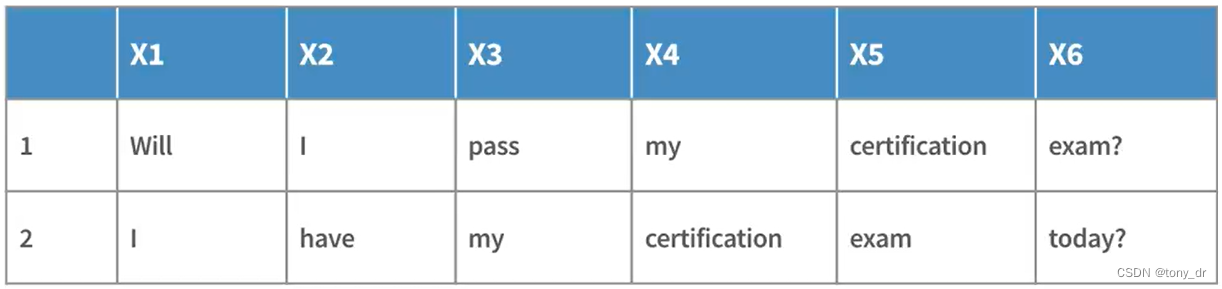
通过上述两个句子的训练,"certification"这个单词前面出现"my"的概率、和其后面出现“exam”的概率会比较高。设想有大量的句子用于训练,那么必然会得出一个更一般、适用性更广的单词组合的概率。
和FNN相比,RNN最大的特点是:输入和输出不再独立,输出会循环到之前的计算环节、并作为其输入之一。注意:不要和FNN中的反向传播混淆了。反向传播是用于调整权重和偏好的,并不改变输入,而RNN的循环返回(Loops Back)会改变输入。

5种类型的RNN:参考
Educative Answers - Trusted Answers to Developer Questions
https://www.linkedin.com/pulse/types-recurrent-neural-network-harsh-shrivastava
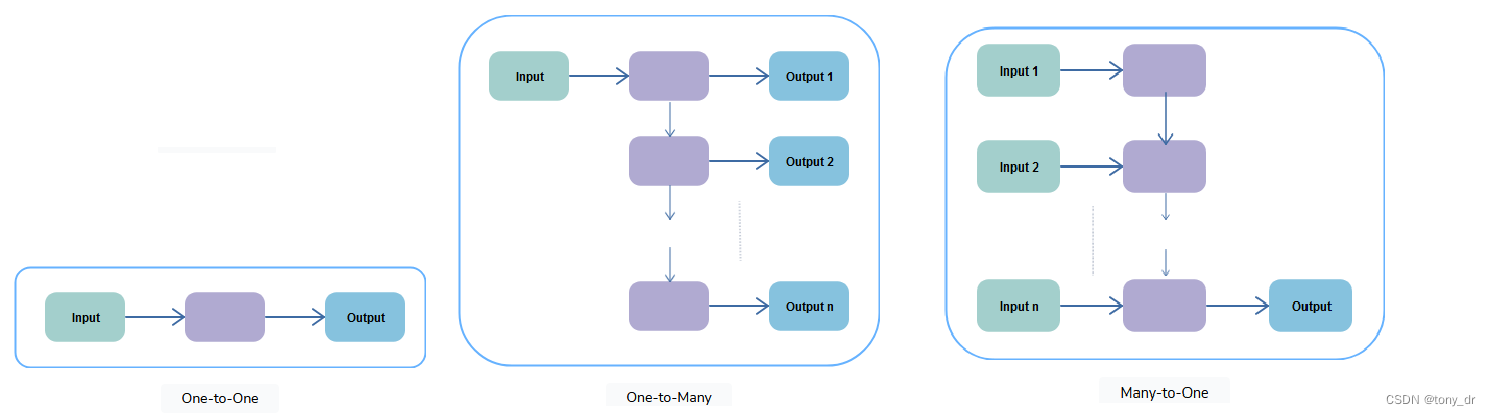
- 一对一:行为上和传统神经网络一样
- 一对多:典型的应用场景是音乐生成(Music Generation,没有翻译为作曲,我理解是因为作曲是一个专业概念,而AI现在的行为还不能称之为作曲)。在这个应用场景中,RNN通过一个音符(musical note),产生一个音乐片段。
- 多对一:典型的应用场景是情绪分析(sentiment analysis),即对每一个句子分析其是正面或者负面的情绪。例如用于电影评级。
- 多对多(输入等于输出):典型应用场景是名称实体识别(Name-Entity Recognition)。在这个应用场景中,需要识别一个句子中的实体,例如人名,公司等。其输入可以是句子,而输出将是单词各个位置的1和0序列,以表示单词是否是实体。因此在这种情况下,输入序列和输出序列的长度是相等的。
- 多对多(输入不等于输出):典型应用场景是机器翻译。例如RNN学习英文句子,将其翻译为法语句子。

RNN的应用领域:
- 样式检测(pattern detection)
- 语音识别(speech and voice recognition)
- 自然语言处理(natural language processing)
- 时间序列预测(time-series prediction)
- 图像描述(image captioning)
- 语言翻译(language translation)
改造的结构(Transformer Architecture)
在处理具体的问题(如机器翻译,文本总结,回答问题等)的时候,RNN很难利用一些高速运算的设备,例如TPU(Tensor Processing Unit,张量处理单元),GPU(Graphical Processing Unit,图形处理单元),二者都支持大规模的并行处理。
改造的结构是一种适用于以下任务的机器神经网络:
- 机器翻译
- 文本总结
- 回答问题
改造的结构具有可并行化(parallelizable)的特点,和RNN相比,它没有顺序(因此可以很方便地进行并行化处理)。具体来说改造的结构是:
- 一种神经网络
- 包含编码器和解码器
利用注意力机制学习句子不同部分之间的各种关系
编码器对输入序列编码,产生对输入序列的一种表示,然后传给解码器。解码器会学习怎样解码这种表示。
对于Transformer,可以参考: https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture)
其中这样一段说得比较清楚:“文本被转换为称为标记的数字表示,每个标记通过从单词嵌入表中查找被转换为向量。在每一层,通过并行的多头注意力机制(multi-head attention mechanism)将每个标记与其它(unmasked)标记在上下文窗口的范围内被上下文化(contextualized,赋予前后文语境),从而允许放大关键标记的信号并减少不太重要的标记。”
在我的另一篇博文初步理解什么是NLP中,其实已经对上述描述进行了具体化的实操。在这篇文章中,可以看到,有顺序依赖的单词被转化为了词向量以及句向量,而词向量和句向量是没有顺序的。
下表给出了各种神经网络的对比: