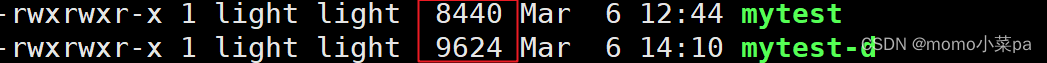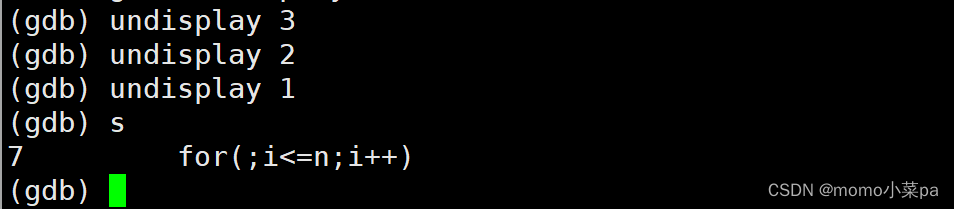1. 背景
程序的发布方式有两种,debug模式和release模式
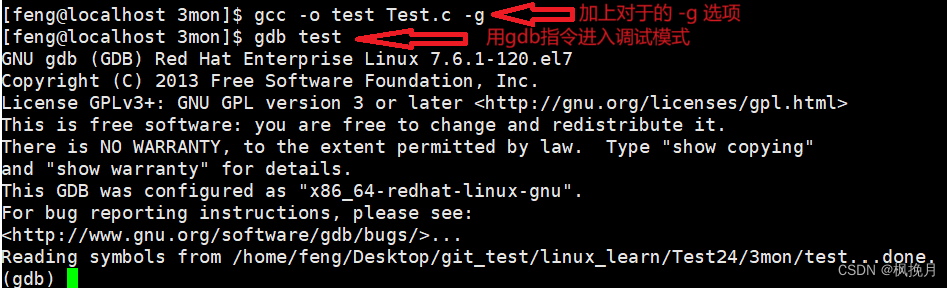
Linux gcc/g++出来的二进制程序,默认是release模式
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
2. 命令
gdb binFile 退出: ctrl + d 或 quit 调试命令:
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名:列出某个函数的源代码。
r或run:运行程序。
n 或 next:单条执行。
s或step:进入函数调用
break(b) 行号:在某一行设置断点
break 函数名:在某个函数开头设置断点
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
set var:修改变量的值
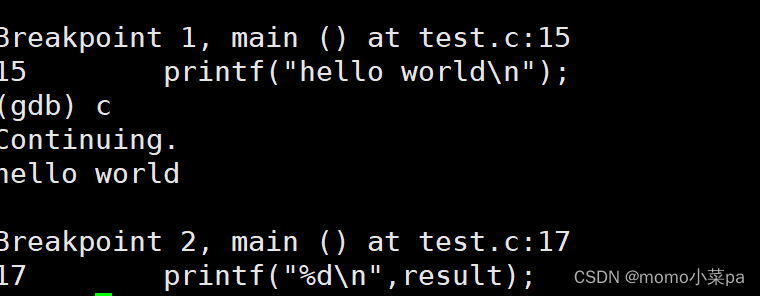
continue(或c):从当前位置开始连续而非单步执行程序
run(或r):从开始连续而非单步执行程序
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
disable breakpoints:禁用断点
enable breakpoints:启用断点
info(或i) breakpoints:参看当前设置了哪些断点
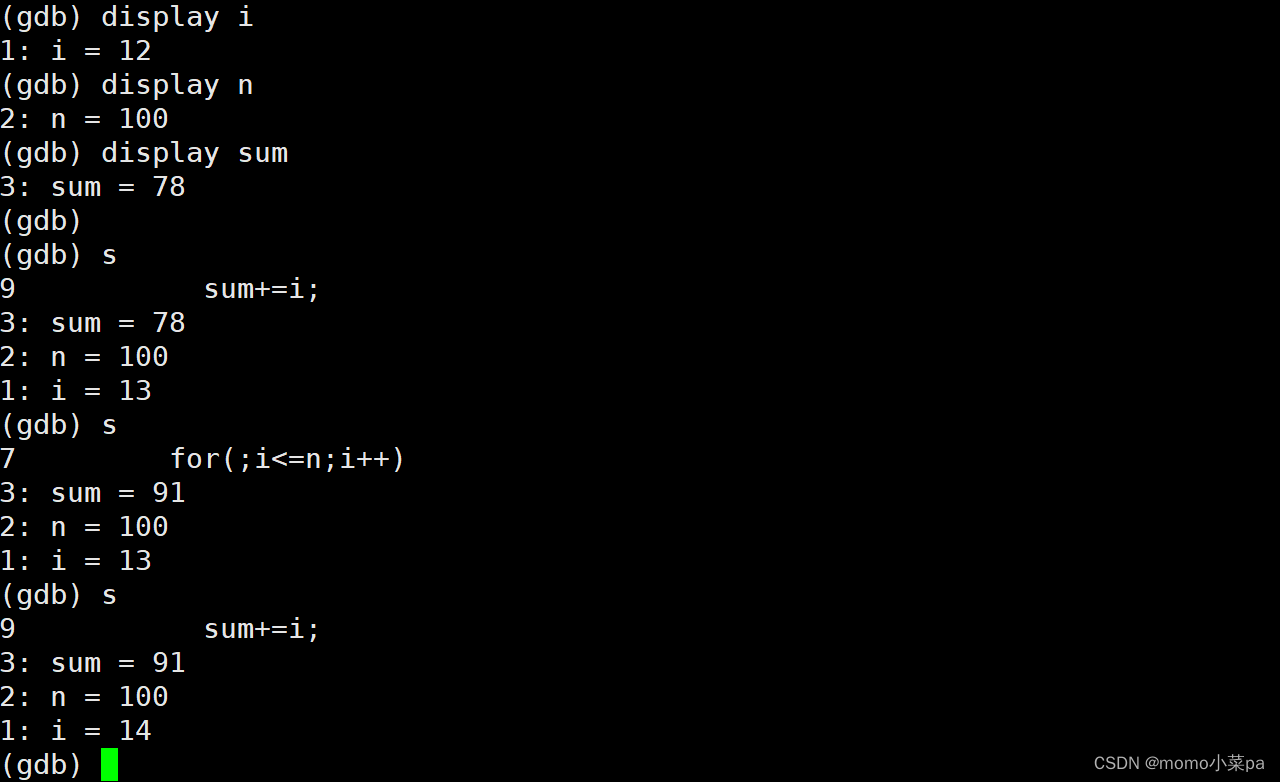
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay:取消对先前设置的那些变量的跟踪
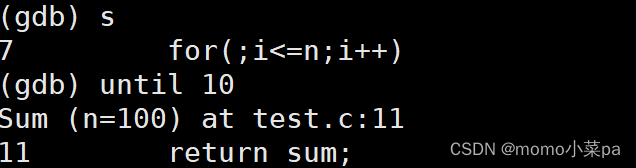
until X行号:跳至X行
breaktrace(或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值
quit:退出gdb
3.一个例子
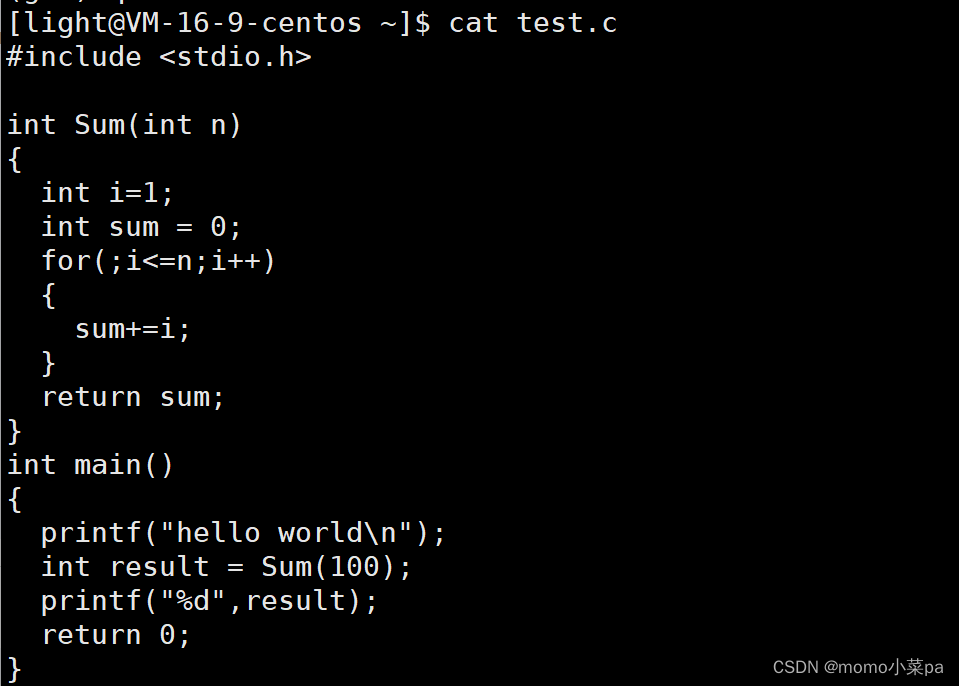
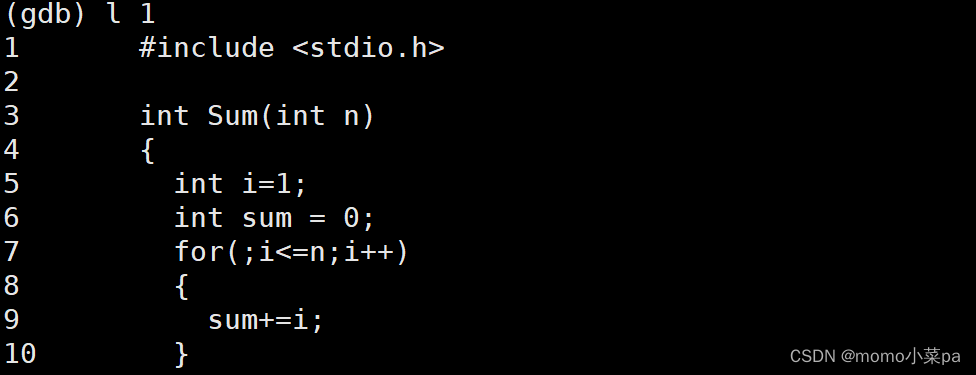
这里有一个C语言的代码:
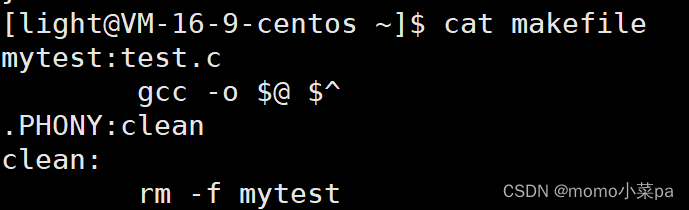
我们在makefile中构建自动化:
运行测试:
运行成功
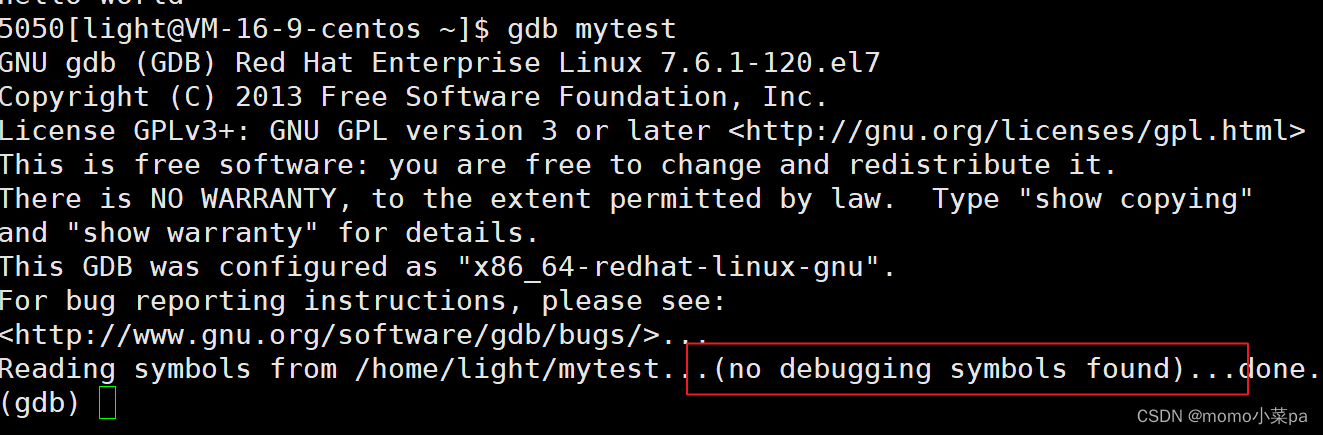
尝试调试:
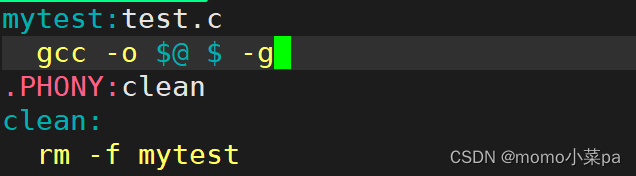
报错了,这是因为Linux gcc/g++出来的二进制程序,默认是release模式,我们要在编译时加上-g指定为debug模式
Debug版本和Release版本是软件开发中常见的两种构建版本,它们之间有一些重要的区别:
1. **Debug版本**:
- **编译优化低**:Debug版本通常不进行优化,以便开发人员能够更容易地调试代码。
- **包含调试信息**:Debug版本包含了大量的调试信息,如符号表、源代码行号等,以便开发人员在调试时能够准确定位问题。
- **运行速度较慢**:由于没有进行优化,Debug版本的运行速度通常比Release版本慢。
- **体积较大**:由于包含了大量调试信息,Debug版本的体积通常比Release版本大。2. **Release版本**:
- **编译优化高**:Release版本通常进行了各种优化,如代码优化、去除无用代码等,以提高程序的运行效率。
- **不包含调试信息**:Release版本通常不包含调试信息,以减小程序体积和提高运行效率。
- **运行速度较快**:由于进行了优化,Release版本的运行速度通常比Debug版本快。
- **体积较小**:由于不包含调试信息,Release版本的体积通常比Debug版本小。总的来说,Debug版本适合开发和调试阶段,能够提供更多的调试信息和便于定位问题;而Release版本适合发布和生产环境,能够提供更高的运行效率和更小的体积。
我们可以看到,在debug版本下,同一个程序的体积要大一些。
接下来我们就开始调试:
我们要与windows中的基本调试功能做个平替:
Linux中也要提供这些功能
1. 在Linux中运行起来才能调试
2. 我们也要看到代码
3. 打断点
4. 局部调试
5. 看到局部变量的内容和地址
6. 看到调用栈
7. 单步
8. 进入函数
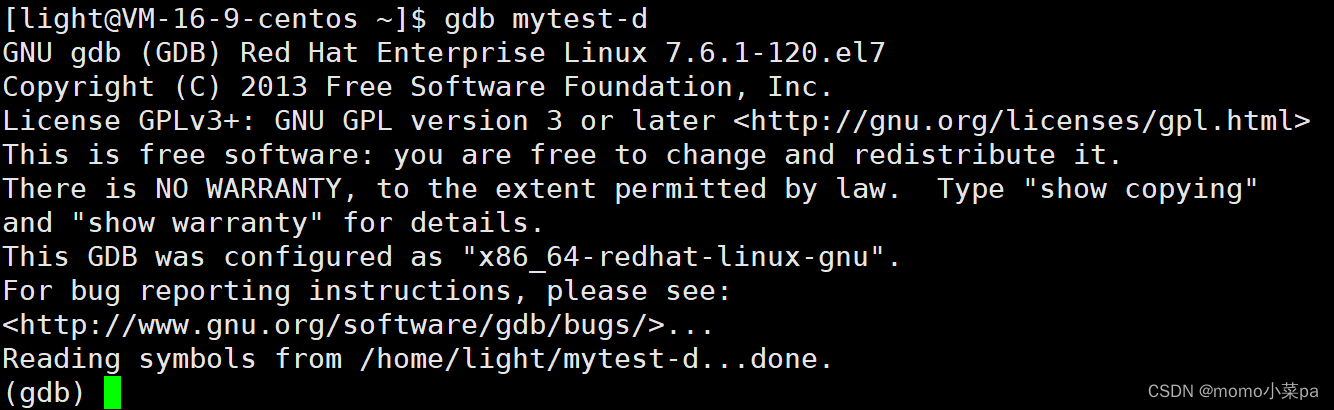
1.gdb mytest-d 进入调试
2.“l 1"(l+行号,显示指定行之后的代码) 从头开始罗列代码,想要看更多的代码,直接按回车
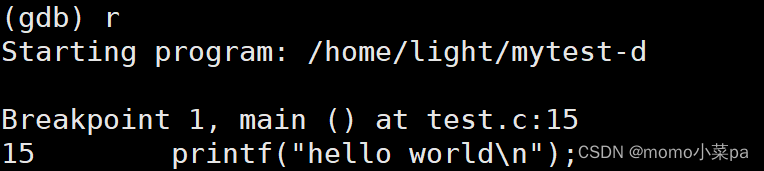
3.运行调试”r“,输入r后程序直接走完了,但我们不想让他直接走完,这时我们就要进行设置断点。
4.设置断点 ”b+行号/函数名/file:行号“
对函数设置断点的时候,是在函数体内的第一行代码开始
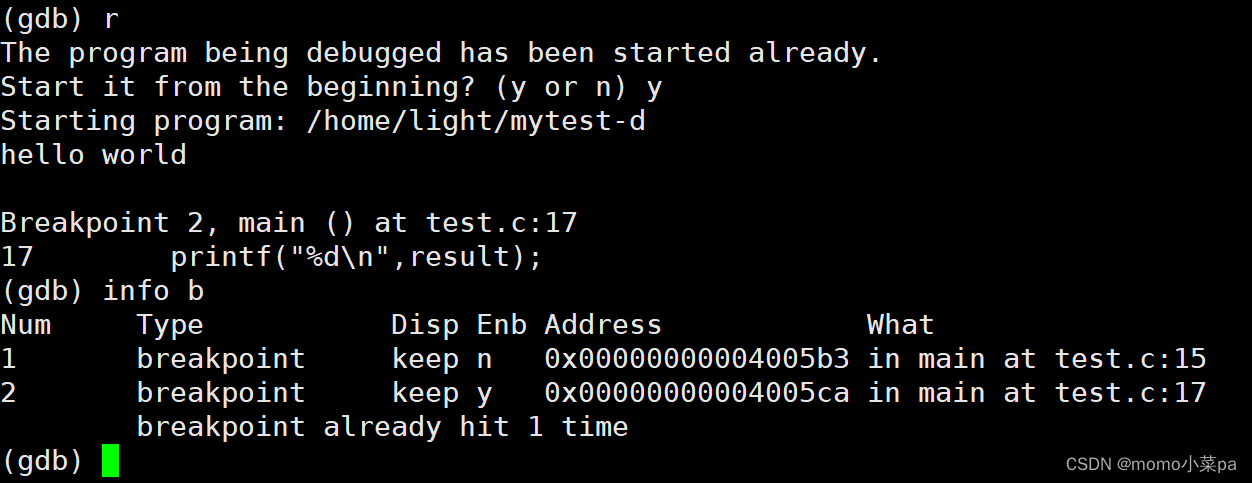
查看断点:“info+b”
删除断点:删除断点是根据info中断点的编号来进行删除的,“d+编号”
在info中 Enb表示的是:这个断点是否开启,y表示开启了。r开始运行,此时程序就在第一个断点处停下来了
当我们再用info查看的时候,发现第一个断点已经提示被命中一次了
我们尝试将1号断点关闭:“disable+编号“关闭此段点,info查看,Enb显示为n,表示此断点被关闭了。
我们再次运行一下,这时编译器会提示你正常调试是否要重新开始,输入y重新开始调试。我们发现编译器跳过了1号断点,在2号断点处停下来了。
重新启用断点:”enable+编号“
5.逐语句和逐过程的进行调试
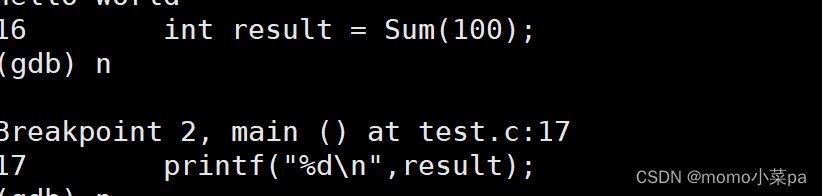
逐过程:不区分语句还是函数,遇到函数不进入函数:”n“回车就好了
逐语句:遇到函数进入函数,函数也是一条一条语句构成的:"s"回车就好了
此时就进入函数了。
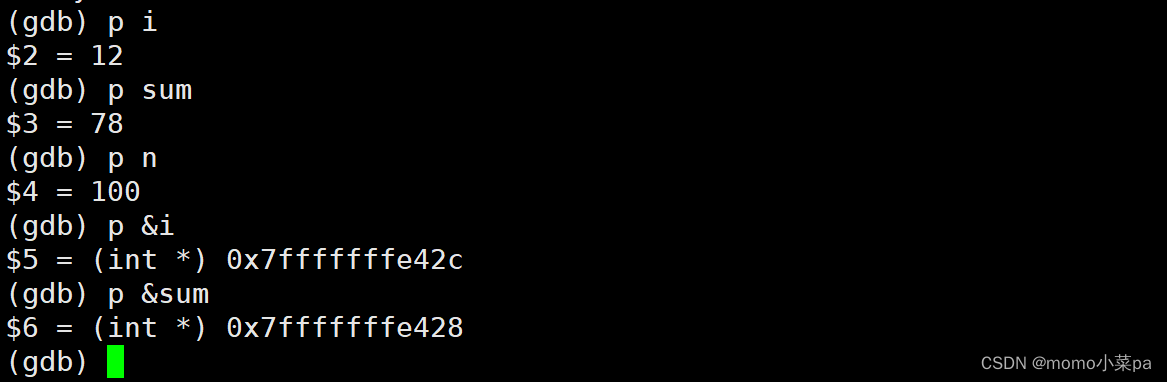
6.显示变量的内容和地址
”p”:查看指向neir
display:指定局部变量内容(地址),让其常显示且自动更新
取消常显示:undisplay+编号:取消指定常显示的内容(编号就是变量前面的数字)
这样就取消变量的常显示了
7.单步操作
在调试中单步操作是非常重要的,如果代码量庞大,单步操作可以初步的确定错误的范围,然后在这个范围里进行逐过程或者逐语句的进行调试。
单步:从一个断点处跳到下一个断点处,如果没有报错,那么两个断点间不存在错误。
“c”然后回车
8.调用堆栈
调试中调用堆栈是一个非常有用的工具,它记录了程序在执行过程中函数调用的顺序和位置。调用堆栈的作用包括:
1. **跟踪函数调用关系**:调用堆栈可以显示程序执行过程中每个函数的调用顺序,帮助开发人员理解函数之间的调用关系。
2. **定位问题来源**:当程序发生错误或异常时,调用堆栈可以指示错误发生的位置,帮助开发人员快速定位问题的根源。
3. **调试过程中的上下文**:调用堆栈提供了函数调用的上下文信息,包括每个函数的参数、局部变量和返回地址,有助于开发人员在调试过程中了解每个函数的执行情况。
4. **追踪递归调用**:对于递归函数或多层嵌套调用的情况,调用堆栈可以清晰地显示每一层函数调用的情况,帮助开发人员追踪递归调用的执行过程。
5. **优化程序性能**:通过分析调用堆栈,开发人员可以了解程序中哪些函数被频繁调用,从而帮助他们进行性能优化,减少不必要的函数调用或优化关键函数的执行效率。
一句话:函数级别的范围查找(如果报错,则证明函数出错)
bt:调用堆栈
finish:将一个函数运行结束,就停下来
until:在一个范围内,直接运行到指定行
在这里我们直接跳过了一个循环
9.其它调试指令
set var name = value :修改一个变量的内容(不用改代码,进行多分支的测试)