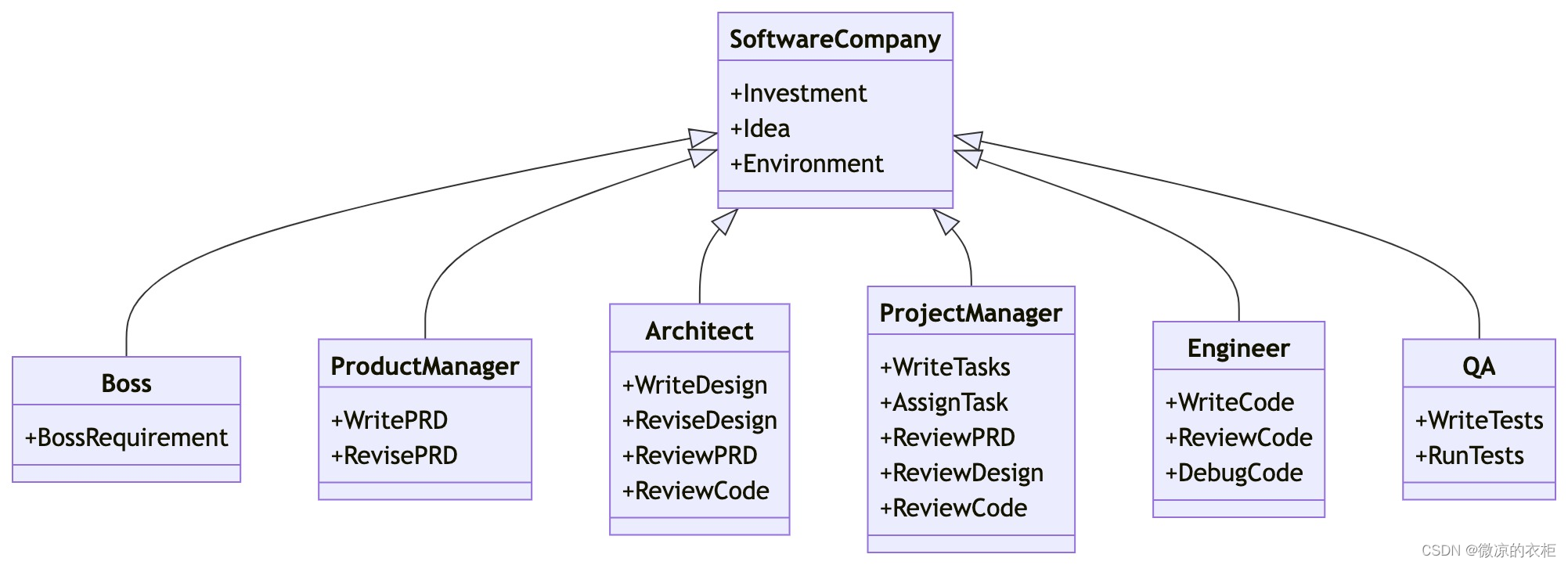
我们定义智能体应该具备哪些行为,为智能体配备这些能力,我们就拥有了一个简单可用的智能体!MetaGPT具有高度灵活性,可定义自己所需的行为和智能体!
最终效果
一键生成技术文档,比如字数约有5千7的Mysql教程。

一键输出长篇网络小说,字数长达1万7千字!(存在大纲层级问题,预计是提示词工程问题。)

智能体概念
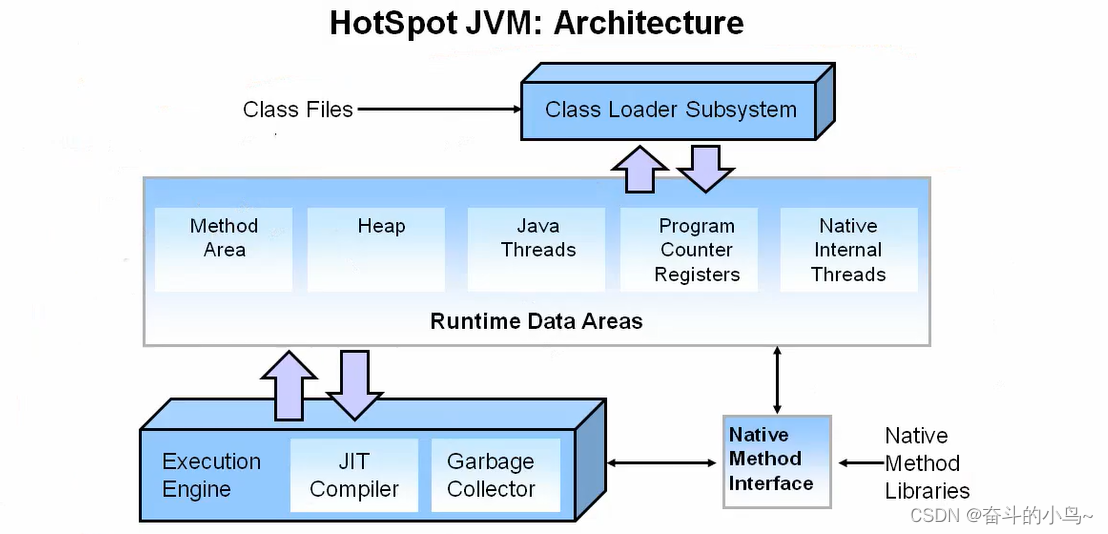
我们先看一下单智能体执行任务的运行周期:

显然,智能体执行的周期包含: 观察 + 思考 + 行动 三部分。
然而,在MetaGPT框架中,一个智能体封装成一个角色🤖(Role)。
一个角色往往具有:
- 大语言模型加持的大脑(可选)
- 能够记住自己之前做过什么的记忆(可选)
此时我们使用下面更加丰富的框架表示:

了解了大致流程之后,针对本节内容,我们以技术文档生成(官方示例代码)和一键生成小说(魔改)为例,我们需要着重学习一下,其中的Action、Role、Memory。
整体思路
如果我们需要生成一个技术文档,我们可以先攥写该技术的所有知识点,随后,我们遍历所有的知识点,逐一细化即可生成一份完整的技术文档。
Action概念
类
Action是动作的逻辑抽象。可以在这里通过代码执行任何事情,包括执行代码,检索,也可以通过简单地调用 self._aask 函数令 LLM 赋予这个动作能力,即这个函数将在底层调用 LLM api。
技术文档生成
如果我们需要生成一个技术文档,我们可以先攥写该技术的所有知识点,随后,我们遍历所有的知识点,逐一细化即可生成一份完整的技术文档。
所以我们提炼出两个动作,一个写大纲,一个根据知识点攥写细化文档。


这里的prompt其实就是根据变量填充的字符串,通过调用_aask获取生成结果。当然,写大纲的话我们需要额外做一点格式化输出和提取。
小说生成
同样地,在攥写小说时,我们可以先攥写一个小说的大纲,随后根据大纲,再去丰富完善我们每一个章节的小说内容。

此处我们修改了prompt,使得询问LLM时预先定义好小说的人物角色以及关系。限定其额外返回characters。
为什么要这么做
考虑到分章节后,每次传入如果仅给出一个小说的标题和要求,那么小说的连贯性以及其他配角角色会出现遗忘。

故我们除了像技术文档给出大纲知识点(title)之外,为了确保连续性,我们也需要生成出小说的角色(characters),最后在写具体内容的时候提供角色以及上一次的情节(memory)。
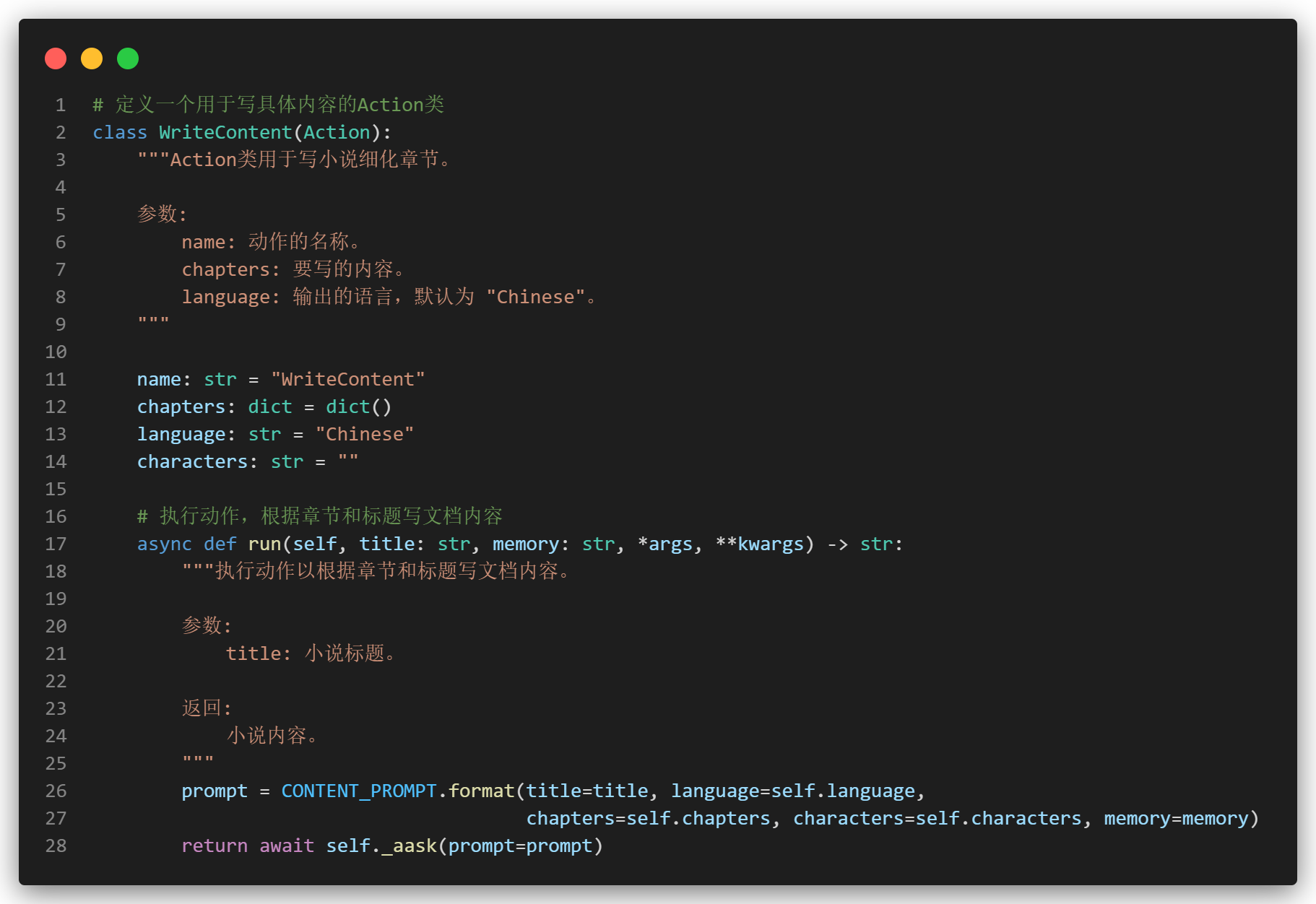
我猜你会问到,为什么多了一个memory。
我知道你很急,但是你先别急。
下面我们先说说我们在哪里用到这些Action
Role概念
Role顾名思义就是我们定义好的智能体角色。最简单的角色只需要指定 Role 的 name(昵称) 和 profile(人设),并重写Role基类的 __init__ 与 _act 方法。
相关源代码如下:
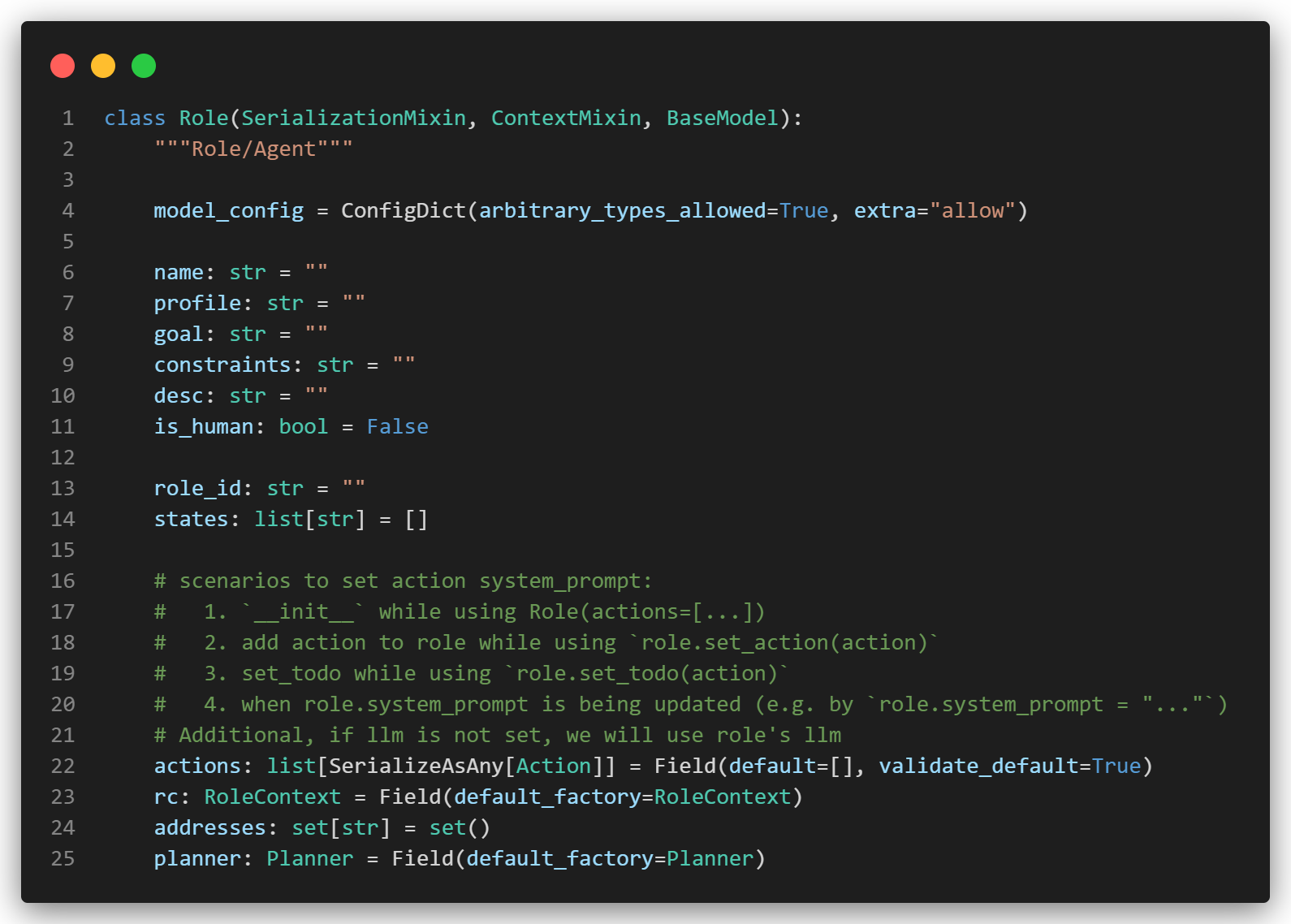
我们可以看到,我们还可以设定goal、constraints、desc等属性。实际上这些都会作为prompt辅助提示大模型。
通过注释,可知设置动作系统的场景:
1. 在使用 Role(actions=[…]) 时调用 __init__
2. 使用 role.set_action(action) 为角色添加动作
3. 使用 role.set_todo(action) 设置待办事项
4. 当 role.system_prompt 正在更新时(例如,通过 role.system_prompt = "...")
另外,如果尚未设置 llm,我们将使用角色的 llm
技术文档助手
我们看下教程助手的角色定义:(重点__init__)
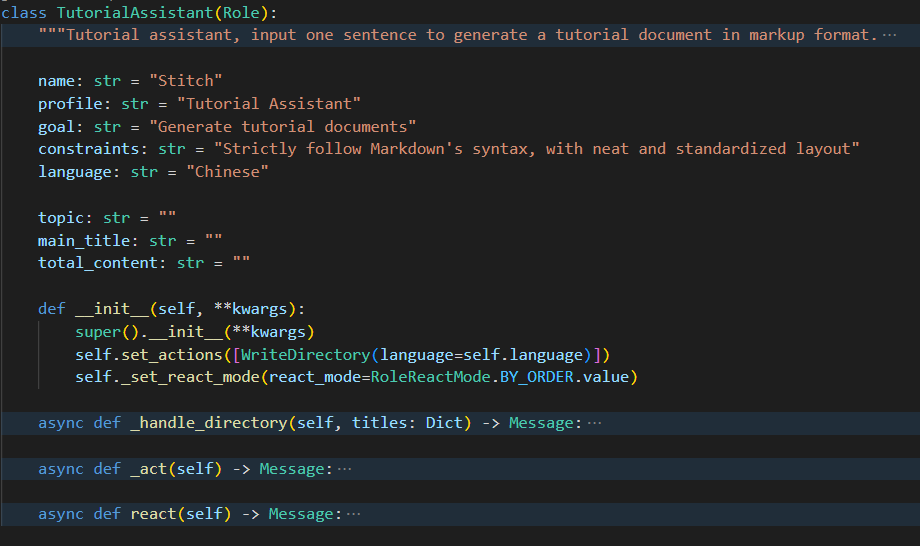
super().__init__(**kwargs) 调用了基类 Role 的构造函数。
self.set_actions([WriteDirectory(language=self.language)]) 设置角色的动作,这里定义了一个 WriteDirectory 动作,该动作将生成目录结构。
self._set_react_mode(react_mode=RoleReactMode.BY_ORDER.value) 设置角色的反应模式,按顺序执行。
从现在来看,似乎这个Role只会写大纲,我们再去看看当实际触发这个动作之后,Role调用_act会发生什么。

此处的todo.run就会去调用我们开始定义的Action。
随后通过自定义的大纲处理函数,拆分我们需要的知识点。
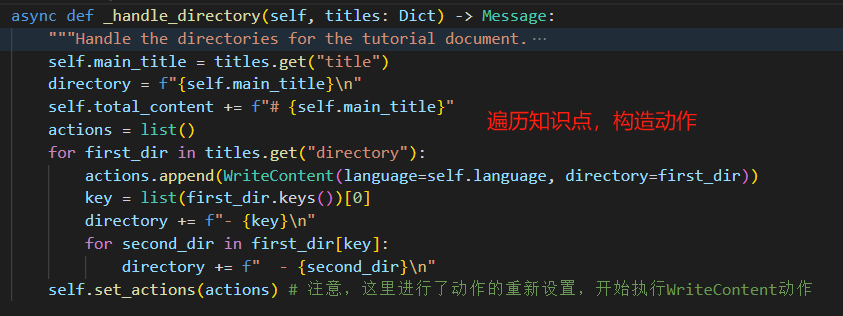
最终的react便是直接输出文件。

至此,我们便捋清了我们的技术文档生成的部分。
小说家
小说家和教程助手最大的差别在于不仅需要传输章节标题给具体内容细化的动作,同时还需要:
- 记住人名,不然换一个章节就换一个人名了。
- 记住上一次的剧情,方便下一章节的小说可以继续流畅地延续。
好,现在我们想想,我们可以一开始让大模型设想一个角色介绍。所以我们定义小说家的时候,其实可以将characters作为这个小说的一个属性。方便我们构造WriteContent动作。

但是我们在定义的时候,小说家会知道自己上一章写了什么吗?
不,在他开始动笔前是不知道的。
只有每次动笔之后,才知道上一章写了什么。
因此,在执行动作时,我们额外为生成的内容进行记忆,存储memory中,并且在下一次调用时获取最新的章节。(详见WriteContent部分代码。后续memory部分仅做介绍。)

Memory概念
记忆是智能体的核心组件之一。智能体需要记忆来获取做出决策或执行动作所需的基本上下文,还需要记忆来学习技能或积累经验。
在MetaGPT中,Memory类是智能体的记忆的抽象。当初始化时,Role初始化一个Memory对象作为self.rc.memory属性,它将在之后的_observe中存储每个Message,以便后续的检索。简而言之,Role的记忆是一个含有Message的列表。
检索记忆
当需要获取记忆时(获取LLM输入的上下文),你可以使用self.get_memories。函数定义如下:
def get_memories(self, k=0) -> list[Message]:
"""A wrapper to return the most recent k memories of this role, return all when k=0"""
return self.rc.memory.get(k=k)要是我们再往下翻一级源码,就会发现,此处的memory.get(k=k)实际上是逆序取的k个。

添加记忆
可以使用`self.rc.memory.add(msg)`添加记忆,其中msg必须是Message的实例。
建议在定义_act逻辑时将Message的动作输出添加到Role的记忆中。通常,Role需要记住它先前说过或做过什么,以便采取下一步的行动。
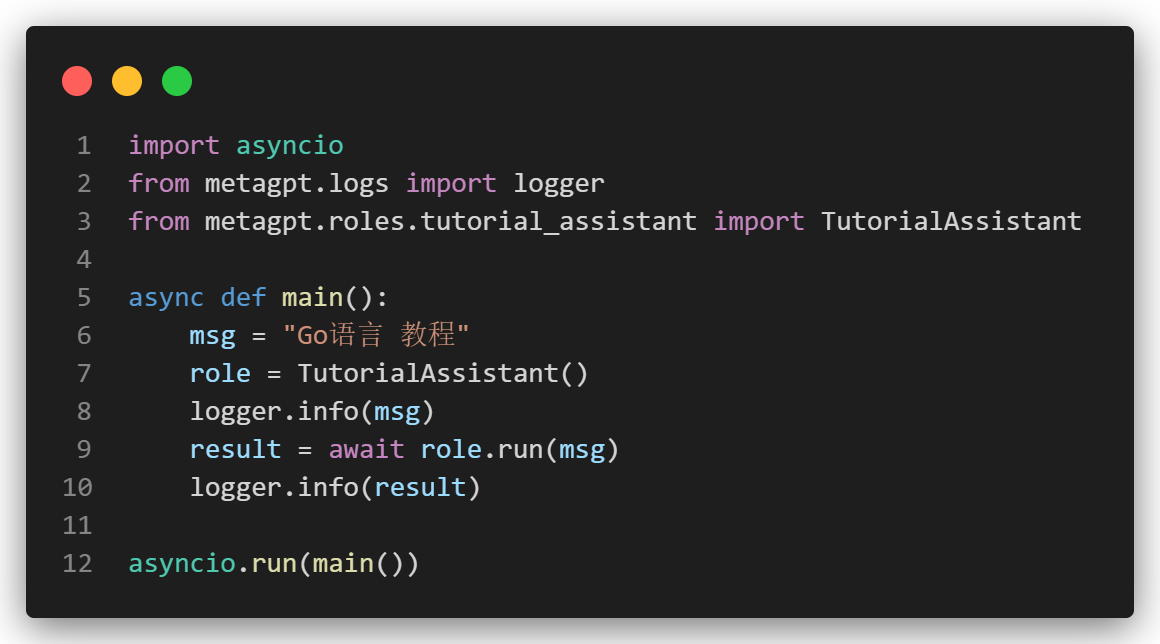
测试函数
最后我们只需要调用如下代码即可。(AI小说同理)
总结
我们借着 技术文档生成 以及 小说生成 为例, 主要学习了Action、Role、Memory概念。当然,其中重要的概念不止这些,包括传递的消息类Message。
但是!胖子不是一口吃成的,是一口一口吃成的。
随着后续进一步的扩展,包括源码的研读,这个过程本身就颇具收获。
当然,AI小说家的prompt需要自己编写,这里没有放出来,或许就能写一个更优秀的小说呢?