论文标题: Deep Learning for Multivariate Time Series Imputation: A Survey
链接:https://arxiv.org/abs/2402.04059
作者:Jun Wang ; Wenjie Du ; Wei Cao ; Keli Zhang ; Wenjia Wang ; Yuxuan Liang ; Qingsong Wen
机构:香港科技大学,PyPOTS,华为诺亚方舟实验室,香港科技大学(广州),松鼠AI
Cool Paper:https://papers.cool/arxiv/2402.04059

项目地址:https://github.com/WenjieDu/Awesome_Imputation

摘要
普遍存在的缺失值导致多元时间序列数据只有被部分观测,破坏了时间序列的完整性,阻碍了有效的时间序列数据分析。 最近,深度学习插补方法在提高损坏的时间序列数据的质量方面取得了显着的成功,从而提高了下游任务的性能。 在本文中,对最近提出的深度学习插补方法进行了全面的调查。 首先,提出了所有调研的方法的分类,然后通过强调这些方法的优点和局限性来对这些方法进行结构化介绍。 同时还进行了实证实验来研究不同的方法并比较它们对下游任务的增强。 最后,指出了多元时间序列插补未来研究的开放问题。 这项工作的所有代码和配置,包括定期维护的多元时间序列插补论文列表,都可以在 GitHub 仓库中找到。
Q: 这篇论文试图解决什么问题?
A: 这篇论文《Deep Learning for Multivariate Time Series Imputation: A Survey》旨在解决多变量时间序列数据中普遍存在的缺失值问题。缺失值破坏了时间序列数据的完整性,阻碍了有效的时间序列数据分析。论文通过以下几个方面来应对这一挑战:
- 方法分类:提出了一种新的分类方法,根据插补不确定性和神经网络架构对现有的深度学习插补方法进行分类。
- 系统性回顾:对近年来提出的深度学习插补方法进行了全面的调查,强调了这些方法的优势和局限性。
- 实证实验:通过实证实验研究不同方法,并比较它们在下游任务中的性能提升。
- 未来研究方向:指出了多变量时间序列插补未来研究的开放性问题。
- 资源提供:提供了所有代码和配置,包括一个定期维护的多变量时间序列插补论文列表,以便研究者和实践者能够访问和使用这些资源。
总的来说,这篇论文试图通过深度学习方法来提高缺失时间序列数据的质量,从而增强下游任务(如分类、预测等)的性能。
Q: 有哪些相关研究?
A: 这篇论文提到了多篇与多变量时间序列插补(MTSI)相关的研究,这些研究涵盖了不同的方法和模型。以下是一些关键的相关研究:
- 统计和机器学习方法:
- KNNI:基于K-最近邻的插补方法。
- TIDER:一种基于时间序列的插补方法。
- MICE:多重插补方法,用于处理缺失数据。
- 深度学习方法:
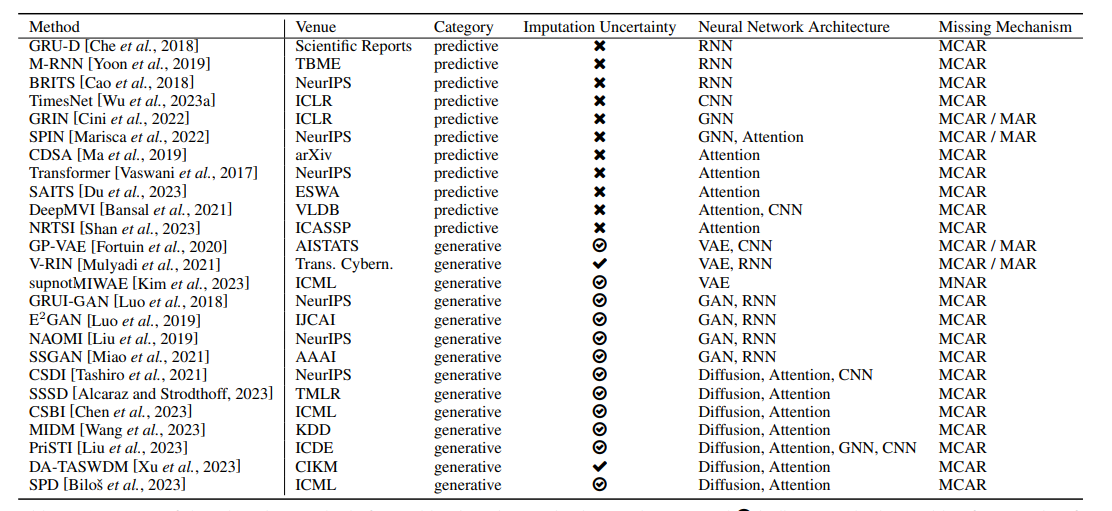
- GRU-D:一种基于门控循环单元(GRU)的插补方法,考虑了时间序列中的缺失值。
- M-RNN:多方向循环神经网络,用于处理时间序列中的缺失数据。
- BRITS:双向循环神经网络,用于时间序列插补。
- TimesNet:结合了卷积神经网络(CNN)和傅里叶变换的时间序列插补方法。
- GRIN:基于图神经网络(GNN)的时间序列插补方法。
- CDSA:结合了Transformer和注意力机制的时间序列插补方法。
- SAITS:自监督训练方法,用于处理缺失数据。
- 生成模型:
- GP-VAE:基于变分自编码器(VAE)的时间序列插补方法。
- V-RIN:不确定性感知的循环神经网络插补方法。
- E2GAN:端到端的生成对抗网络(GAN)插补方法。
- CSDI:基于条件分数的扩散模型,用于时间序列插补。
- 工具和库:
- imputeTS:R语言中的一个库,提供多种插补方法。
- mice:用于处理缺失数据的R包,实现链式方程多变量插补。
- GluonTS:一个用于时间序列的生成机器学习包。
- Sktime:一个统一的接口,用于机器学习处理时间序列数据。
- PyPOTS:一个专注于部分观测时间序列建模的Python工具箱。
这些研究展示了在多变量时间序列插补领域的多样性,包括不同的模型架构、学习方法和应用场景。通过这些研究,研究者可以更好地理解现有方法的优势和局限性,并为未来的研究提供指导。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决多变量时间序列插补(MTSI)的问题:
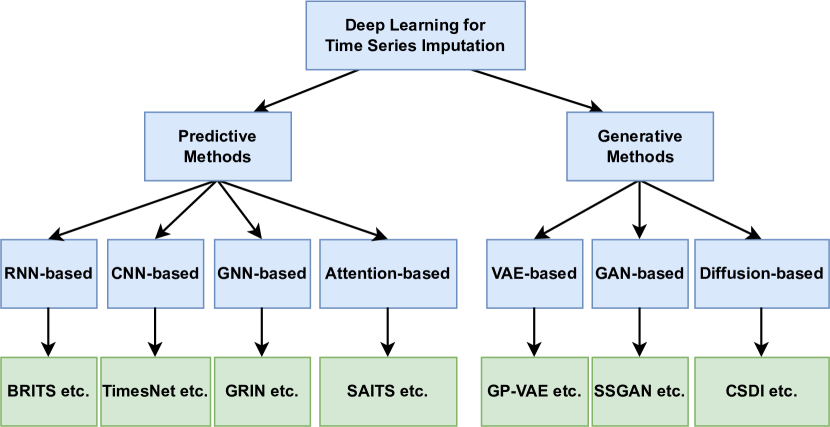
- 提出分类法:论文首先提出了一种新的分类法,将深度学习插补方法分为两大类:基于预测的方法和基于生成的方法。预测方法提供固定估计值,而生成方法提供可能值的分布,以反映插补的不确定性。
- 系统性回顾:对现有的深度学习插补方法进行了结构化的回顾,强调了这些方法的优势和局限性。这包括对基于循环神经网络(RNN)、卷积神经网络(CNN)、图神经网络(GNN)、注意力机制、变分自编码器(VAE)、生成对抗网络(GAN)和扩散模型的插补方法的详细讨论。
- 实证实验:通过实证实验,研究了不同插补方法的性能,并比较了它们在下游任务(如分类)中的性能提升。这有助于理解不同方法在实际应用中的有效性。
- 指出未来研究方向:论文最后指出了MTSI领域的开放性问题,为未来的研究提供了方向。这包括处理更复杂的缺失数据模式(如MNAR)、提高下游任务性能、提高算法的可扩展性,以及探索大型语言模型(LLMs)在MTSI中的应用。
- 资源提供:论文提供了所有相关代码和配置,包括一个定期维护的多变量时间序列插补论文列表,这些都可以在GitHub上找到。这为研究者和实践者提供了便利,以便他们可以访问和使用这些资源。
通过这些步骤,论文不仅总结了当前的研究成果,而且为未来的研究提供了框架和指导,有助于推动MTSI领域的发展。
Q: 论文做了哪些实验?
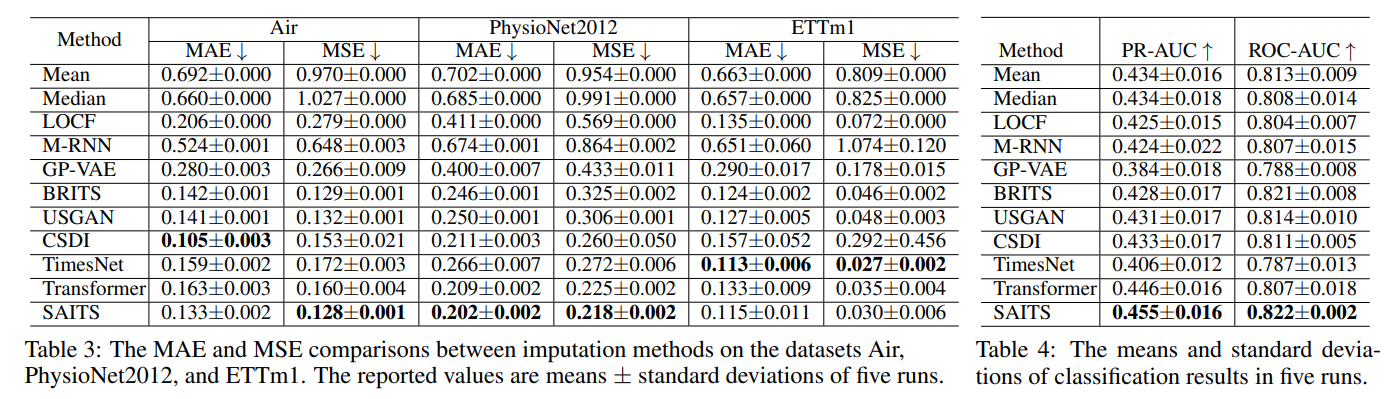
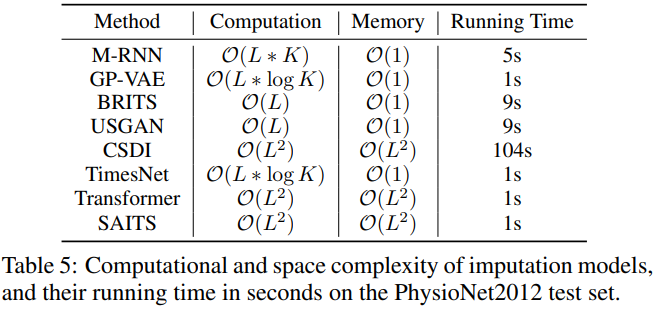
A: 论文中进行了一系列的实证实验,以评估和分析不同类别的深度多变量时间序列插补方法。以下是实验的主要方面:
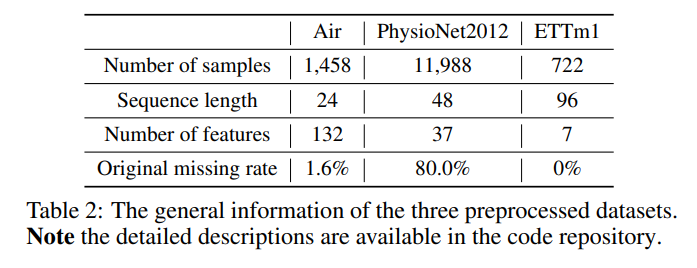
- 数据集:实验使用了三个真实世界的数据集进行测试,分别是Air、PhysioNet2012和ETTm1。这些数据集在时间序列分析领域中常用,具有不同的样本数量、序列长度、特征数量和缺失率。
- 插补方法:实验比较了三种简单的插补方法(均值、中位数和最后观测值向前填充)以及八种代表性的深度学习模型。这些模型涵盖了不同的类别,包括基于RNN、CNN、GNN、VAE、GAN和扩散模型的插补方法。
- 性能评估:通过计算均方误差(MSE)和平均绝对误差(MAE)等误差指标,评估了各种插补方法在三个数据集上的准确性。此外,还通过下游任务(如二分类任务)来评估插补质量对整体数据集质量的影响。
- 复杂性分析:对深度学习插补模型的时间和内存复杂性进行了总结,并在PhysioNet2012测试集上记录了实际的推理时间,以便清晰地比较不同模型的性能。
- 实验结果:实验结果显示,深度学习插补方法在处理高缺失率的数据集(如PhysioNet2012)时,相较于统计方法有显著的性能提升。此外,实验还发现,通过更好的插补可以提高下游分类任务的性能。
这些实验旨在提供一个全面的评估,以帮助理解不同插补方法在实际应用中的有效性,并为未来的研究提供指导。
Q: 有什么可以进一步探索的点?
A: 论文指出了多变量时间序列插补(MTSI)领域的几个未来研究方向,这些方向可以进一步探索以推动该领域的研究和应用:
- 处理缺失数据的复杂模式(MNAR):研究如何在非随机缺失数据(MNAR)的情况下进行有效的插补。这需要开发新的方法来处理观察数据和缺失数据之间的复杂关系。
- 下游任务性能:探索如何将插补任务与下游任务(如分类、预测等)结合起来,以实现端到端的学习。这可能涉及到开发新的模型架构,使得插补过程能够更好地服务于后续的分析任务。
- 可扩展性:鉴于深度学习模型在处理大规模数据集时的高计算成本,研究如何设计可扩展的插补算法,以便在资源有限的情况下处理大规模的缺失数据问题。
- 大型语言模型(LLMs)在MTSI中的应用:探索如何利用大型语言模型(如GPT-3)来处理时间序列数据。LLMs在处理自然语言和图像数据方面取得了显著成果,研究其在时间序列数据插补中的潜力,可能会带来新的突破。
- 多模态数据融合:考虑将时间序列数据与其他类型的数据(如文本、图像等)结合起来,以提供更丰富的上下文信息。这可能需要开发新的模型来处理多模态数据,并在插补过程中利用这些信息。
- 模型解释性和透明度:提高插补模型的可解释性,以便用户能够理解模型是如何进行插补的。这对于医疗、金融等领域尤为重要,因为这些领域的决策通常需要高度的信任和透明度。
- 实时插补:研究实时或近实时的插补方法,这对于需要快速响应的应用场景(如金融市场监控、实时监控系统等)至关重要。
- 跨领域插补策略:探索跨领域知识迁移的插补策略,以便将一个领域的插补经验应用到另一个领域,提高插补模型的泛化能力。
通过进一步探索这些方向,研究者可以开发出更加强大、灵活和高效的插补方法,以应对日益增长的数据分析需求。
Q: 总结一下论文的主要内容
A: 这篇论文《Deep Learning for Multivariate Time Series Imputation: A Survey》主要内容包括以下几个方面:
- 问题背景:介绍了多变量时间序列数据中缺失值问题的普遍性和重要性,以及它对数据分析和决策的影响。
- 研究动机:指出了传统统计和机器学习方法在处理时间序列数据中的局限性,强调了深度学习方法在插补任务中的潜力。
- 方法分类:提出了一种新的分类法,将深度学习插补方法分为预测方法和生成方法,并根据神经网络架构进一步细分为RNN、CNN、GNN、注意力机制、VAE、GAN和扩散模型等类别。
- 系统性回顾:对近年来提出的深度学习插补方法进行了全面的回顾,分析了它们的优势和局限性。
- 实证实验:通过实验评估了不同插补方法的性能,包括在三个真实世界数据集上的插补准确性和对下游任务性能的提升。
- 未来研究方向:指出了MTSI领域的开放性问题,如处理MNAR数据、提高下游任务性能、可扩展性、大型语言模型的应用等。
- 资源提供:提供了所有相关代码和配置,包括一个定期维护的多变量时间序列插补论文列表,以便研究者和实践者能够访问和使用这些资源。
指出了MTSI领域的开放性问题,如处理MNAR数据、提高下游任务性能、可扩展性、大型语言模型的应用等。
7. 资源提供:提供了所有相关代码和配置,包括一个定期维护的多变量时间序列插补论文列表,以便研究者和实践者能够访问和使用这些资源。
总的来说,这篇论文为深度学习在多变量时间序列插补领域的研究提供了一个全面的概述,旨在促进该领域的进一步发展和应用。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀

![<span style='color:red;'>AI</span><span style='color:red;'>论文</span><span style='color:red;'>速</span><span style='color:red;'>读</span> |2024[TPAMI]【<span style='color:red;'>综述</span>】自监督<span style='color:red;'>学习</span><span style='color:red;'>在</span><span style='color:red;'>时间</span><span style='color:red;'>序列</span>分析<span style='color:red;'>的</span>分类、进展与展望](https://img-blog.csdnimg.cn/img_convert/4846973252d2aaff086a1467353d9428.png)


























![[AIGC] 使用Curl进行网络请求的常见用法](https://img-blog.csdnimg.cn/direct/8ea76ace68f74711a52fd98229319846.png)