一、前言
本文将介绍张量的统计计算,包括基本统计量(均值、方差、标准差、最大值、最小值)、相关性统计量(相关系数、协方差)、累积统计量(张量的和、张量的累积和、张量的乘积、张量的累积乘积)、分布统计量(百分位数、偏度、峰度)、假设检验和离散度统计量等。
二、实验环境
本系列实验使用如下环境
conda create -n DL python==3.11
conda activate DL
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda install pydot
三、PyTorch数据结构
1、Tensor(张量)
Tensor(张量)是PyTorch中用于表示多维数据的主要数据结构,类似于多维数组,可以存储和操作数字数据。
1. 维度(Dimensions)
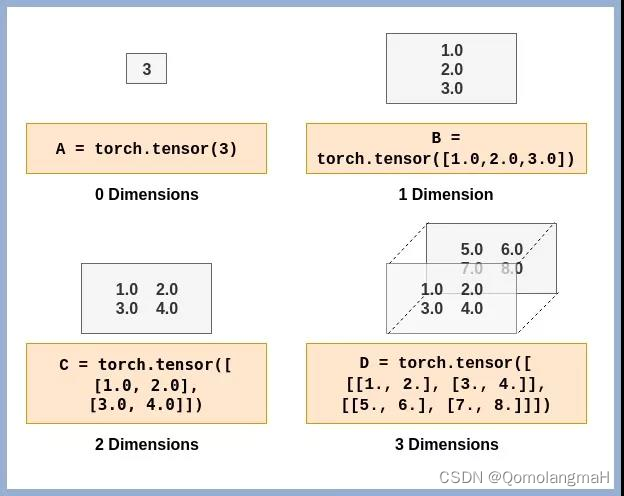
Tensor(张量)的维度(Dimensions)是指张量的轴数或阶数。在PyTorch中,可以使用size()方法获取张量的维度信息,使用dim()方法获取张量的轴数。
2. 数据类型(Data Types)
PyTorch中的张量可以具有不同的数据类型:
- torch.float32或torch.float:32位浮点数张量。
- torch.float64或torch.double:64位浮点数张量。
- torch.float16或torch.half:16位浮点数张量。
- torch.int8:8位整数张量。
- torch.int16或torch.short:16位整数张量。
- torch.int32或torch.int:32位整数张量。
- torch.int64或torch.long:64位整数张量。
- torch.bool:布尔张量,存储True或False。
【深度学习】Pytorch 系列教程(一):PyTorch数据结构:1、Tensor(张量)及其维度(Dimensions)、数据类型(Data Types)
3. GPU加速(GPU Acceleration)
【深度学习】Pytorch 系列教程(二):PyTorch数据结构:1、Tensor(张量): GPU加速(GPU Acceleration)
2、张量的数学运算
PyTorch提供了丰富的操作函数,用于对Tensor进行各种操作,如数学运算、统计计算、张量变形、索引和切片等。这些操作函数能够高效地利用GPU进行并行计算,加速模型训练过程。
1. 向量运算
【深度学习】Pytorch 系列教程(三):PyTorch数据结构:2、张量的数学运算(1):向量运算(加减乘除、数乘、内积、外积、范数、广播机制)
2. 矩阵运算
【深度学习】Pytorch 系列教程(四):PyTorch数据结构:2、张量的数学运算(2):矩阵运算及其数学原理(基础运算、转置、行列式、迹、伴随矩阵、逆、特征值和特征向量)
3. 向量范数、矩阵范数、与谱半径详解
【深度学习】Pytorch 系列教程(五):PyTorch数据结构:2、张量的数学运算(3):向量范数(0、1、2、p、无穷)、矩阵范数(弗罗贝尼乌斯、列和、行和、谱范数、核范数)与谱半径详解
4. 一维卷积运算
【深度学习】Pytorch 系列教程(六):PyTorch数据结构:2、张量的数学运算(4):一维卷积及其数学原理(步长stride、零填充pad;宽卷积、窄卷积、等宽卷积;卷积运算与互相关运算)
5. 二维卷积运算
【深度学习】Pytorch 系列教程(七):PyTorch数据结构:2、张量的数学运算(5):二维卷积及其数学原理
6. 高维张量
【深度学习】pytorch教程(八):PyTorch数据结构:2、张量的数学运算(6):高维张量:乘法、卷积(conv2d~ 四维张量;conv3d~五维张量)
3、张量的统计计算
1. 基本统计量
基本统计量是对张量中的元素进行整体性描述的统计指标,包括均值、方差、标准差、最大值、最小值等。这些统计量可以帮助我们了解张量的整体分布和特征。
a. 均值
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
mean = torch.mean(tensor)
print(mean)
- 输出:
tensor(3.)
c. 方差
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
variance = torch.var(tensor)
print(variance)
- 输出:
tensor(2.5000)
c. 标准差
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
std = torch.std(tensor)
print(std)
- 输出:
tensor(1.5811)
d. 最大值
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
max_value = torch.max(tensor)
print(max_value)
- 输出:
tensor(5)
e. 最小值
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
min_value = torch.min(tensor)
print(min_value)
输出:
tensor(1)
2. 相关性统计量
用于衡量不同张量(或张量中不同维度)之间的相关性。常见的相关性统计量包括相关系数、协方差等。相关系数可以衡量两个维度之间的线性相关程度,协方差可以衡量两个维度之间的总体相关性。
a. 相关系数
import torch
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
Y = torch.tensor([[2, 4, 6], [1, 3, 5]])
corr_XY = torch.corrcoef(X, Y)
print(corr_XY)
b. 协方差
import torch
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
Y = torch.tensor([[2, 4, 6], [1, 3, 5]])
cov_XY = torch.cov(X, Y)
print(cov_XY)
3. 累积统计量
a. 张量的和
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
sum_value = torch.sum(tensor)
print(sum_value)
- 输出:
tensor(15)
b. 张量的累积和
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
cumsum_value = torch.cumsum(tensor, dim=0)
print(cumsum_value)
- 输出:
tensor([ 1, 3, 6, 10, 15])
c. 张量的乘积
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
prod_value = torch.prod(tensor)
print(prod_value)
- 输出:
tensor(120)
d. 张量的累积乘积
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
cumprod_value = torch.cumprod(tensor, dim=0)
print(cumprod_value)
- 输出:
tensor([ 1, 2, 6, 24, 120])
4. 分布统计量
对张量中元素分布进行描述的统计指标,包括:
- 分位数可以帮助我们了解张量中的特定百分比位置的元素值;
- 偏度可以衡量分布的偏斜程度;
- 峰度可以衡量分布的尖锐程度。
a. 百分位数
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
percentile = torch.percentile(tensor, q=50)
print(percentile)
- 输出:
tensor(3)
百分位数是指在一个数据集中,某个百分比的数据落在该值以下的数值。常见的百分位数有中位数(50%分位数)、四分位数(25%和75%分位数)等。
b. 偏度(skewness)
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
skewness = torch.skew(tensor)
print(skewness)
- 输出:
tensor(0.)
偏度衡量了数据分布的偏斜程度。当偏度为0时,表示数据分布对称。
c. 峰度(kurtosis)
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
kurtosis = torch.kurtosis(tensor)
print(kurtosis)
- 输出:
tensor(-1.3000)
峰度衡量了数据分布的尾部厚度和峰度。负值表示数据分布相对于正态分布具有较平坦的峰度。
5. 假设检验
假设检验是用于判断张量中的数据是否满足某个特定的假设条件的统计方法。常见的假设检验方法包括 t 检验、方差分析、卡方检验等。假设检验可以帮助我们判断数据之间是否存在显著差异。
6. 离散度统计量
离散度统计量用于衡量张量中元素的离散程度,包括熵、基尼系数等。熵可以衡量数据的不确定性,基尼系数可以衡量数据的不平等程度。