【百度智能云千帆杯】贺岁灵感模型
前两天突然收到了百度的短信,邀请参加百度智能云千帆杯·AI原生应用挑战赛,看着挺有意思的就体验了一下。说是比赛,实际上就是发了500元代金券邀请用户来体验他们的AI模型,这期赛题内容是体验他们的 ERNIE-Speed模型 ,并用该模型为基础,训练一个自己的对话模型。以下是我参赛的具体内容。
1 「贺岁灵感模型」赛题说明
1.1 赛题背景
春节假期来临,专属贺岁时刻的精彩“文笔”展示环节,成为我们即将面对的一个“隐藏赛场”!如何生成一个能在春节帮你激发无限创意的模型,是本期赛题要解决的问题。
1.2 赛题内容
生成一个可制作贺岁文案内容的精调模型(限定使用ERNIE Speed,通过对模型精调使其保持原有能力的同时,具备准确理解并执行文案创作中创作长度相关指令的能力)。
- 输入:包含创作长度要求的对文案创作的需求描述文本。(如:如何应对生成给领导的拜年文案;作为“I”人,如何在家庭群中发送讨长辈欢心的50字以内拜年语;如果你作为家长,如何辅助指导孩子完成“300字过年作文”的作业…)
- 输出:严格符合长度要求且满足其他创作需要的创作内容。
1.3 参赛任务
- 通过在千帆大模型平台使用平台上的各种模型调优工具,结合相关数据,基于ERNIE-Speed调优生成符合赛题主题要求且效果优秀的模型。
- 补充说明:官方提供「贺岁文案」基础数据集,开发者需要在此基础上做延伸和扩充(模型训练最少需要100条数据)。
- 点击此处下载数据集
- 微调后的大模型需可访问在千帆大模型平台平台部署服务EndPoint、所有调优过程数据,超参设置和步骤描述,确保评审过程中必要的复现。
- 本次赛题必须使用百度智能云千帆大模型平台(千帆Modelbuilder)完成开发。
1.4 比赛时间
2024年2月8日 00:00:00 — 2024年2月21日 24:00:00
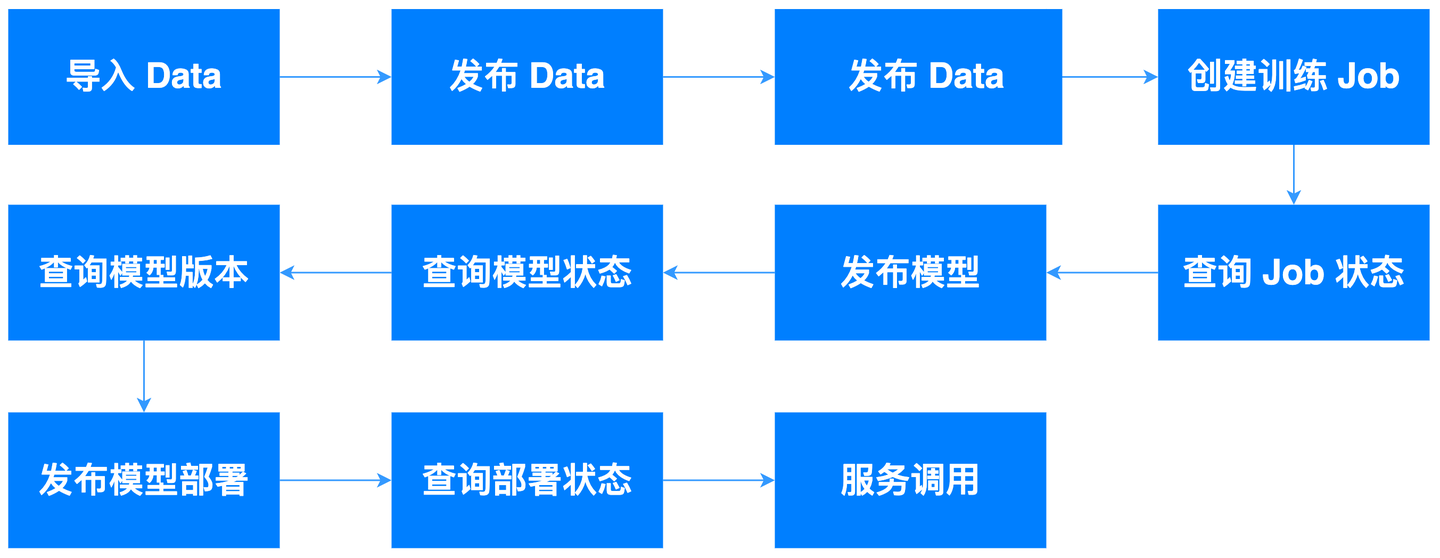
2 数据集
本次实验分别采用两个数据集进行训练,第一个是在原始数据集直接进行数据增强得到的数据集;第二个是在原始数据集基础上,使用chatgpt进行一定扩展后,再进行数据增强得到的数据集。
原始数据集
直接在原始的55条
prompt & response数据集上,进行数据清洗后,再进行数据增强,扩展到255条数据。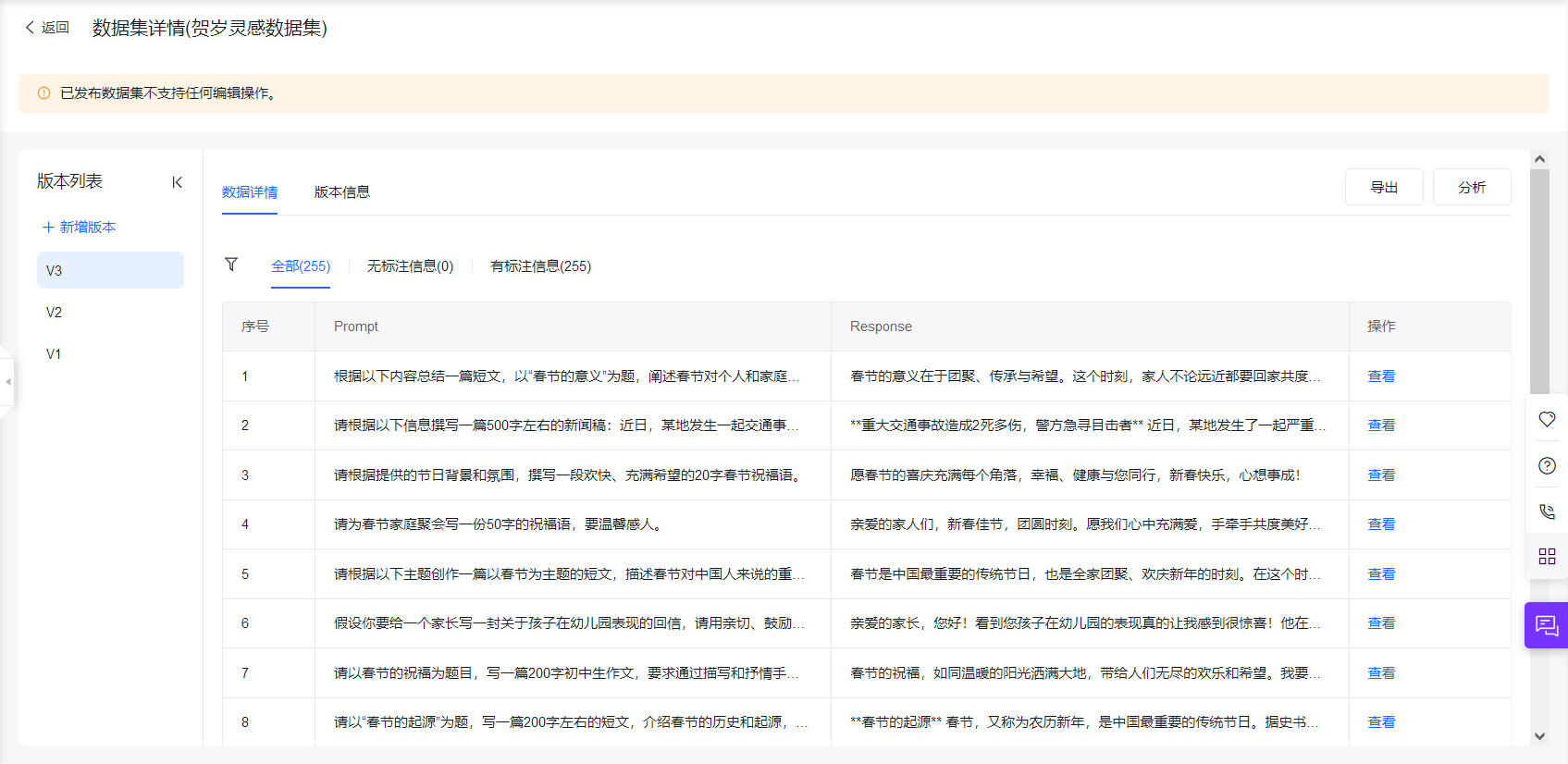
扩展数据集
在比赛给出的数据集基础上,通过chatgpt仿写,从原来的55条
prompt & response,扩写到87条。

然后在千帆大模型平台上上传数据集,并进行了数据增强,扩展到了378条,得到了最终模型训练所用数据集。

数据增强参数如下。

3 模型训练
本次实验采用在千帆大模型平台上的 模型精调 > SFT 模块进行训练。
V1模型——全量训练
V1版本采用原始数据集增强后进行训练,采用全量训练,训练轮次为20轮。学习率及其他参数采用默认值。
训练时长花费了26分钟,训练过程通过Paddle可视化,如下图所示。

训练评估值如下图所示。

可以看出训练结果较好,可能有些过拟合。
V2模型——LoRA训练
V2版本采用扩展数据集增强后训练,采用
LoRA进行训练,训练轮次为15轮。学习率及其他参数采用默认值。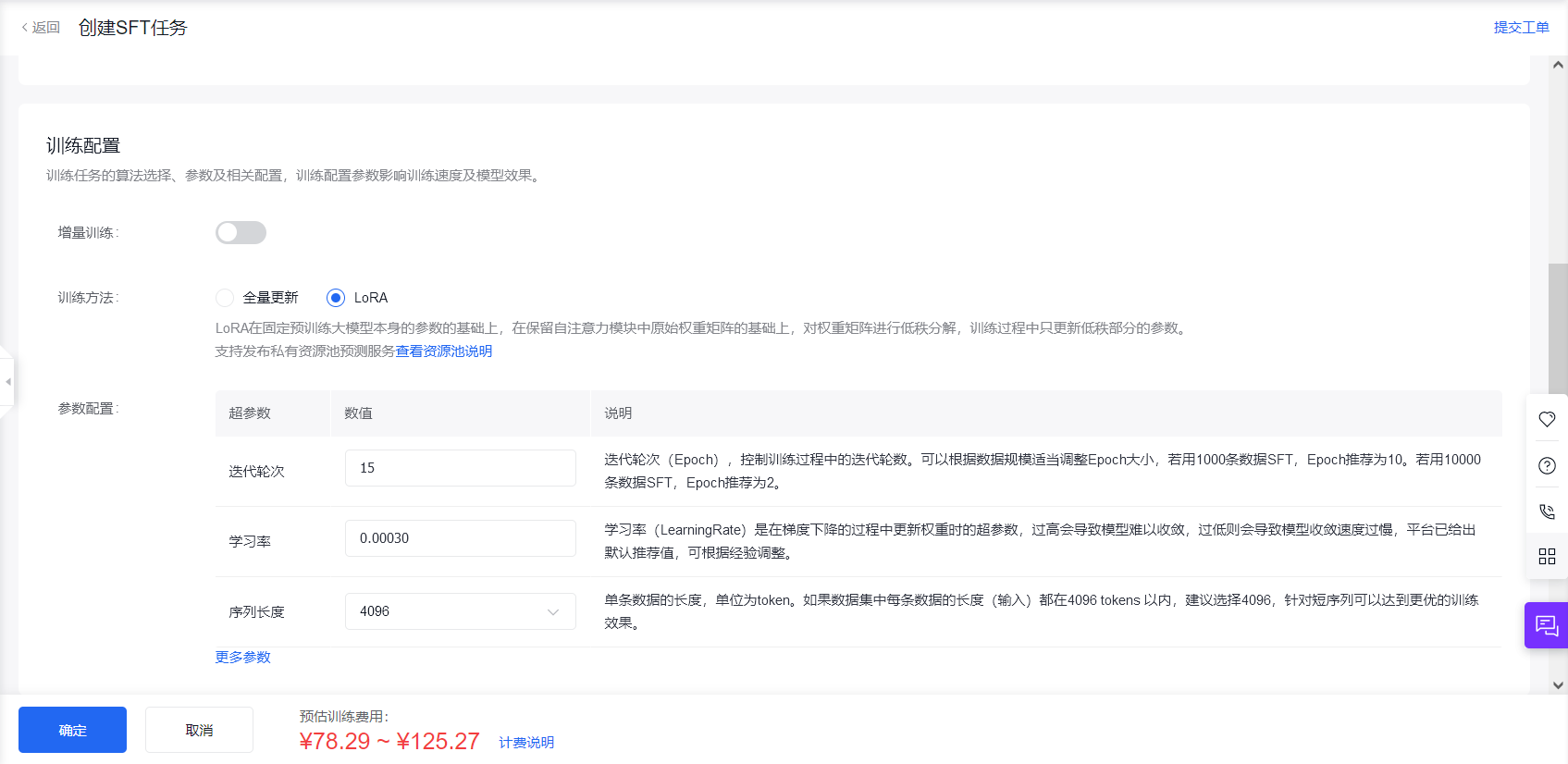
训练时长花费了32分钟,训练过程通过Paddle可视化,如下图所示。
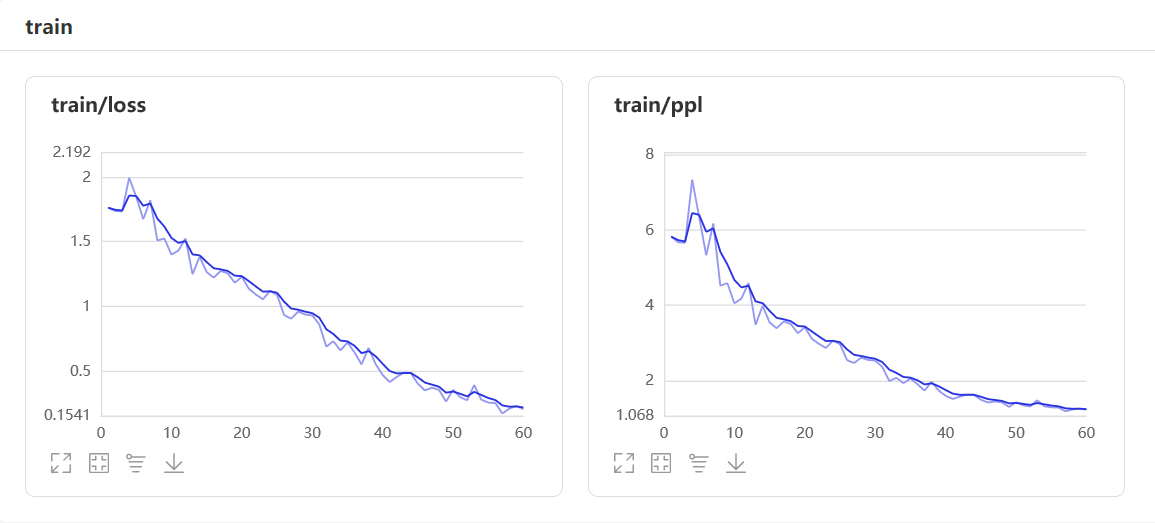
训练评估值如下图所示。

可以看出,训练轮次还是有点少,导致模型有些欠拟合。
4 模型评估
V1模型评估
在千帆大模型平台上,进行模型评估,采用自动规则打分指标,数据集采用原始数据集,结果如下。

可以看到评分还是不错的,但是观察评估详情,可以看到,模型对未训练的提问表现较差,无法在要求的字数范围内作答。而对于训练过的问题,答案与训练时完全相同,说明出现过拟合现象。


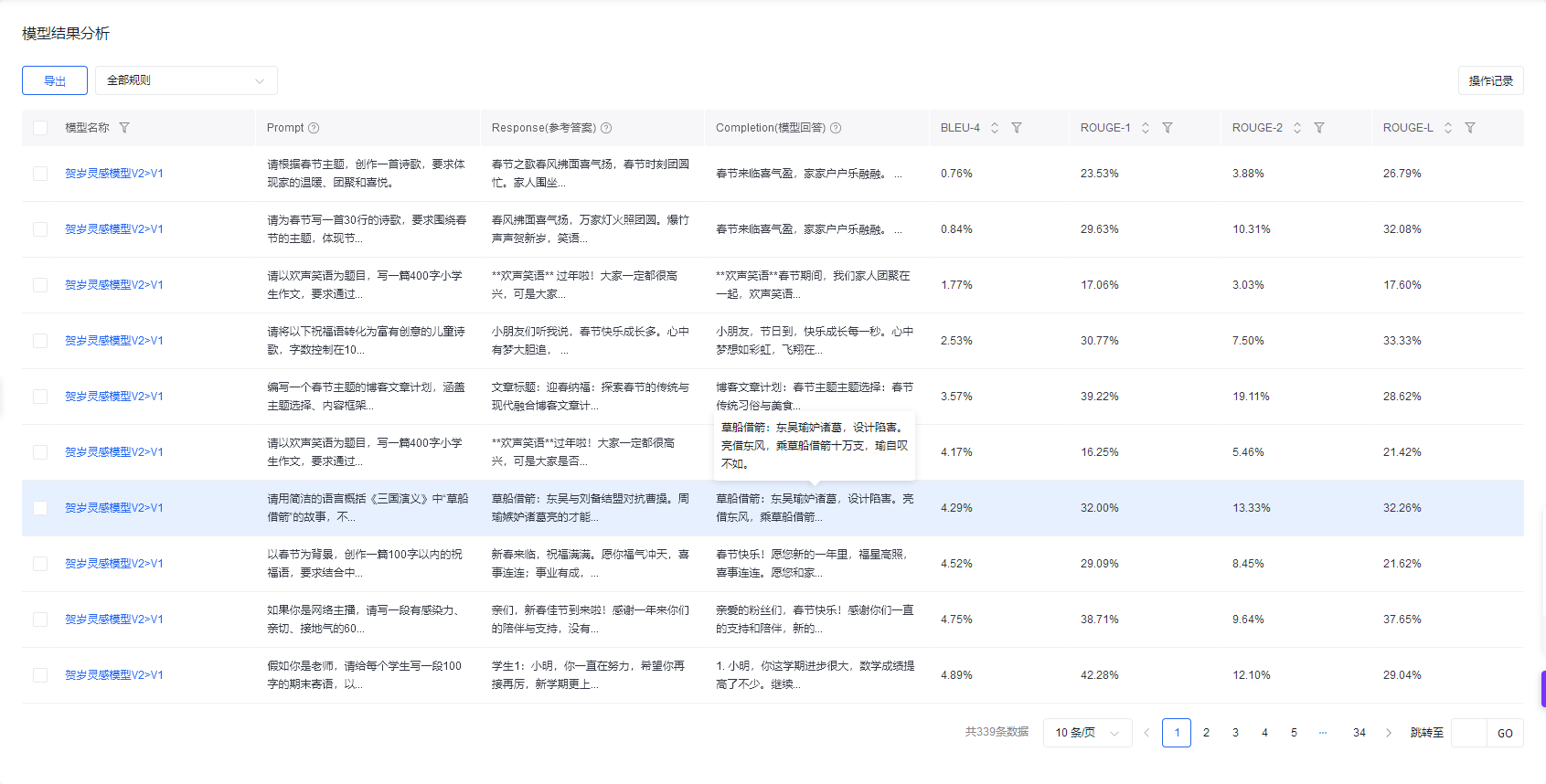
V2模型评估
在千帆大模型平台上,进行模型评估,采用自动规则打分指标,数据集采用扩展后的数据集,结果如下。

可以看到V2模型的评分再各项表现都不高,说明模型有较大问题。
具体来看,查看评估详情可知,模型的某些回答出现了明显语句不通的错误。
5 模型部署
通过千帆大模型平台的 模型服务 > 在线服务 ,可以将模型在线部署,并在体验中心进行测试。
V1模型实际体验测试
将V1模型与其基础版本
ERNIE-Speed进行对比,结果如下。
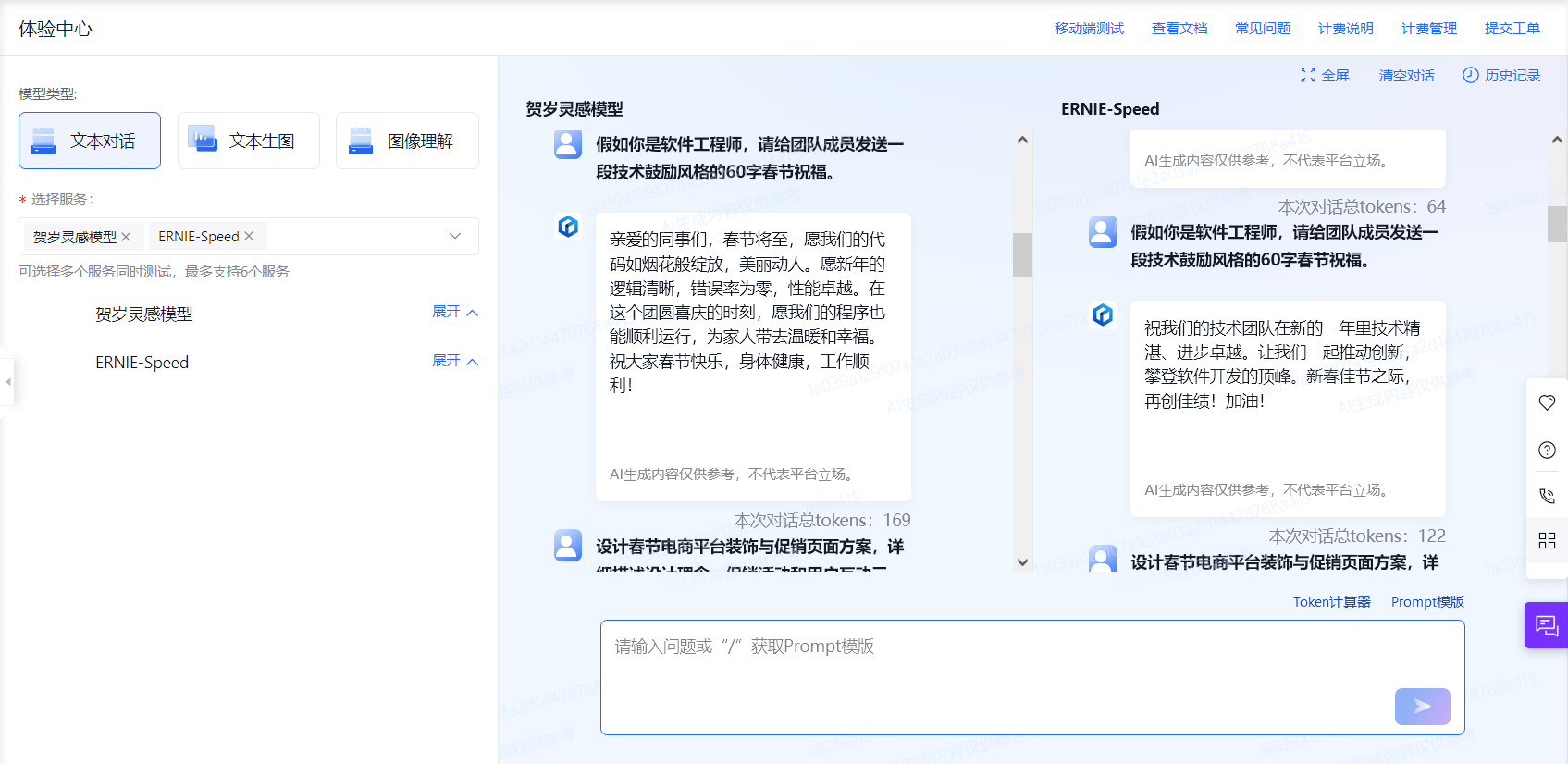



可以看到,该模型回答与训练样例比较符合,但是回答字数还是有些出入。而且因为在数据清洗时,删除了某些空格,导致回答没有分割与换行。
V2模型实际体验测试
将V2模型与其基础版本
ERNIE-Speed对比,结果如下。




可以看到V2模型也存在着相同的问题,无法分段、空格等,但是字数上相比
ERNIE-Speed控制的更好。并且某些回答出现了明显语句不通的错误。
6 总结
由以上实验结果可知,在特定目标上,全量更新的训练结果更好,数据集更大按理说效果也应该更好,但从结果来看并没有明显提升,可能数据集数量上差距并不大。
最终,我又重新训练了一个版本,使用扩展后的训练集,采用全量训练的方法,训练15轮得到的模型,训练过程如下。可知本次训练结果成功收敛,训练较为不错。

之后,在平台上进行模型评估,采用自动规则打分指标结合自动裁员打分指标,结果如下。

由评估结果可知,本次训练结果较为不错,除了准确率以外的得分都比较高。再根据下图评估详情可知,大部分输出结果与输入相同或相近,少部分有些许出入,但是回答也比较通顺。

参考:
比赛官网:https://cloud.baidu.com/qianfandev/aimatch
千帆杯第二期赛题:贺岁灵感模型:https://cloud.baidu.com/qianfandev/topic/268516
百度智能云千帆大模型平台(千帆ModelBuilder):https://cloud.baidu.com/product/wenxinworkshop百度智能云千帆社区:https://cloud.baidu.com/qianfandev
SFT最佳实践:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Xlkb0e6eu
百度智能云千帆大模型平台API文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t
百度智能云千帆大模型平台API在线调试平台:https://console.bce.baidu.com/tools/?u=bce-head#/api?product=AI&project=%E5%8D%83%E5%B8%86%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%B9%B3%E5%8F%B0&parent=ERNIE-Bot-4%EF%BC%88%E9%82%80%E6%B5%8B%EF%BC%89&api=rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro&method=post
百度智能云千帆大模型文档中心:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/qlgujhcpo