京东获得JD商品详情 API 返回值说明
item_get-获得JD商品详情 [查看演示] API注册测试
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
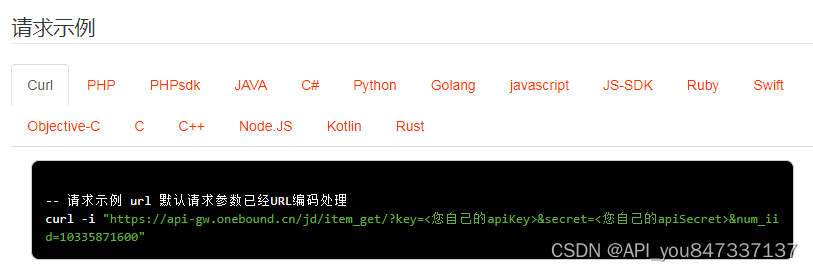
请求参数
请求参数:num_iid=10335871600
参数说明:num_iid:JD商品ID
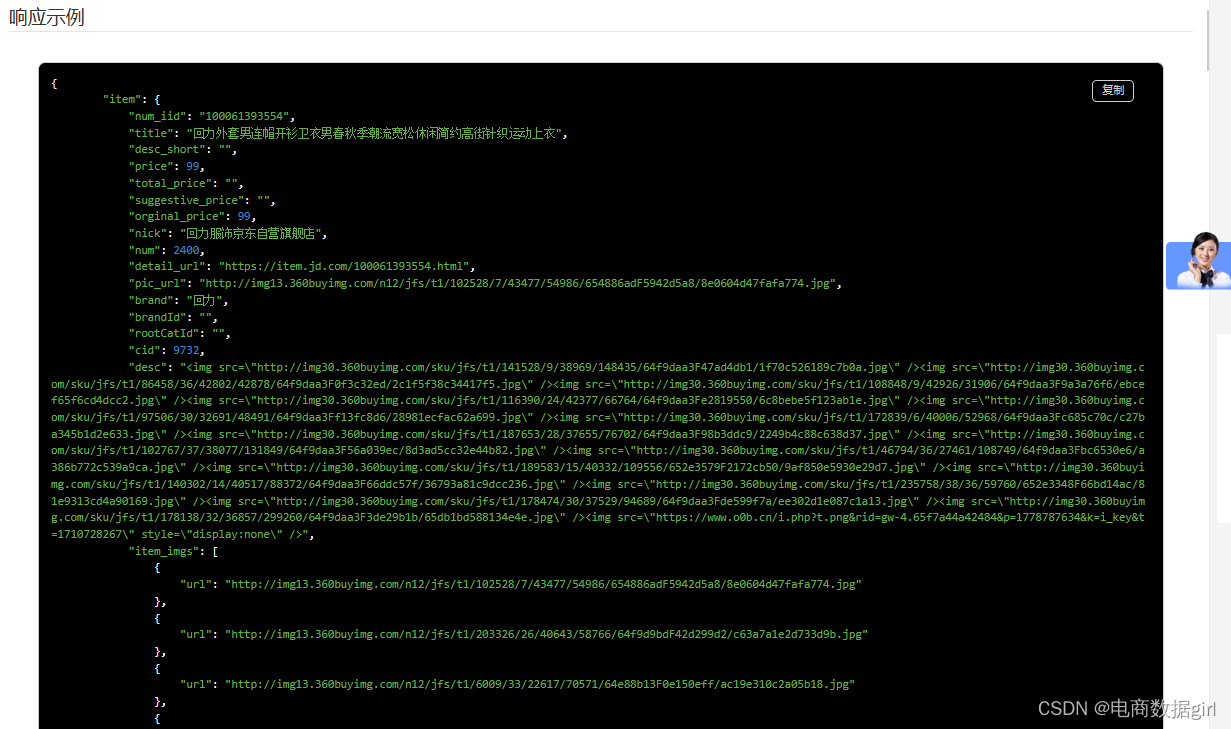
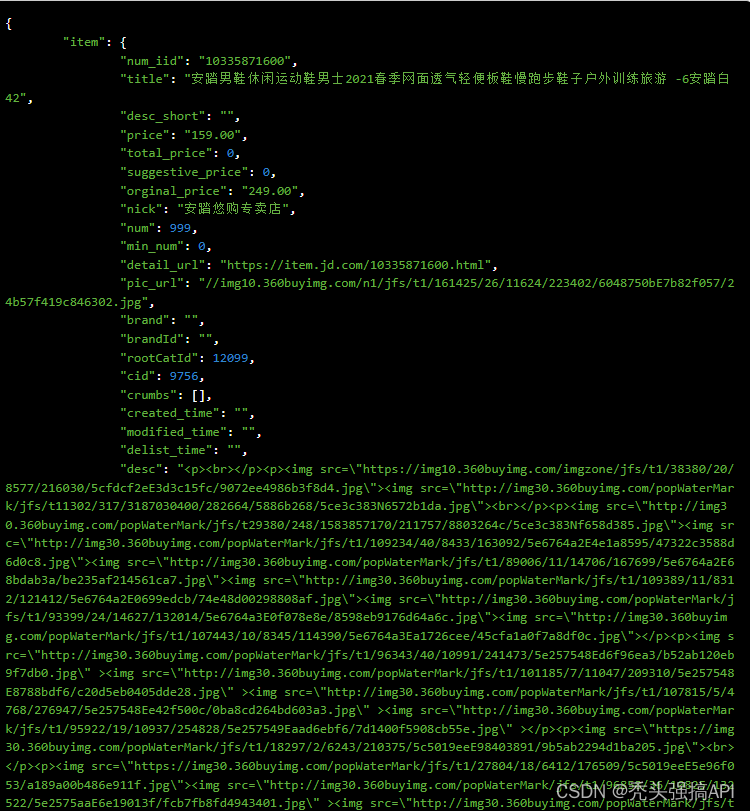
响应参数
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
items |
items[] | 0 | 获得JD商品详情 | |
num_iid |
Bigint | 0 | 29186819959 | 商品ID |
title |
String | 0 | MOCO2018夏季新品时尚V领条纹连衣裙 摩安珂 蓝白条色 S | 商品标题 |
desc_short |
String | 0 | 商品简介 | |
price |
Float | 0 | 719.0 | 价格 |
total_price |
Float | 0 | 0 | |
suggestive_price |
Float | 0 | 0 | |
orginal_price |
Float | 0 | 1199.00 | 原价 |
nick |
String | 0 | MO&Co.官方旗舰店 | 掌柜昵称 |
num |
Int | 0 | 999 | 库存 |
min_num |
Int | 0 | 0 | |
detail_url |
String | 0 | http://item.jd.com/29186819959.html | 商品链接 |
pic_url |
String | 0 | //img14.360buyimg.com/n0/jfs/t22033/147/1051007175/85125/c44dd0df/5b1f2855Ncbe35858.jpg | 商品图片 |
brand |
String | 0 | 品牌名称 | |
brandId |
Int | 0 | 品牌ID | |
rootCatId |
Int | 0 | 1343 | 顶级分类ID |
cid |
Int | 0 | 9719 | 分类ID |
crumbs |
Mix | 0 | [] | |
created_time |
String | 0 | ||
modified_time |
String | 0 | ||
delist_time |
String | 0 | ||
desc |
String | 0 | ||
desc_img |
Mix | 0 | [] | |
item_imgs |
Mix | 0 | [{ "url": "//img14.360buyimg.com/n0/jfs/t22033/147/1051007175/85125/c44dd0df/5b1f2855Ncbe35858.jpg"}] | 商品图片 |
item_weight |
String | 0 | ||
item_size |
String | 0 | ||
location |
String | 0 | 发货地 | |
post_fee |
Float | 0 | 6.00 | 物流费用 |
express_fee |
Float | 0 | 6.00 | 快递费用 |
ems_fee |
Float | 0 | 6.00 | EMS费用 |
shipping_to |
String | 0 | 发货至 | |
has_discount |
Boolean | 0 | false | |
video |
Mix | 0 | [] | 商品视频 |
is_virtual |
String | 0 | ||
sample_id |
String | 0 | 商品风格标识ID | |
is_promotion |
Boolean | 0 | ||
props_name |
String | 0 | 0:0:尺码:S;0:1:尺码:XS;0:2:尺码:M;0:3:尺码:L;0:4:尺码:XL | 商品属性名 |
prop_imgs |
Mix | 0 | {"prop_img": []} | 商品属性图片列表 |
property_alias |
String | 0 | 0:0:S;0:1:XS;0:2:M;0:3:L;0:4:XL | 商品属性别名 |
props |
Mix | 0 | [{ "name": "尺码","value": "S XS M L XL" }] | 商品详情 |
total_sold |
Int | 0 | ||
skus |
Mix | 0 | {"sku": [{"price": "719.00", "orginal_price": "1199.00", "properties": "0:0", "properties_name": "0:0:尺码:S", "quantity": 99, "sku_id": 29186819959, "sku_url": "http://item.jd.com/29186819959.html"}] | 商品规格信息 |
seller_id |
Int | 0 | 卖家ID | |
sales |
Int | 0 | 销量 | |
shop_id |
Int | 0 | 店铺ID | |
props_list |
Mix | 0 | {"0:0": "尺码:S"} | 商品属性 |
seller_info |
Mix | 0 | {"level": null, "shop_type": null, "user_num_id": 57467, "cid": null, "delivery_score": null, "item_score": null, "score_p": null, "zhuy": "//moco.jd.com", "search_id": "", "nick": "MO&Co.官方旗舰店", "shop_name": "MO&Co.官方旗舰店", "title": "MO&Co.官方旗舰店" } | 卖家信息 |
tmall |
Boolean | 0 | false | 是否天猫 |
error |
String | 0 | 错误信息 | |
warning |
String | 0 | 警告信息 | |
url_log |
Mix | 0 | [] | |
props_img |
Mix | 0 | [] | 属性图片 |
shop_item |
Mix | 0 | [] | |
relate_items |
Mix | 0 |
代码实例
# -*- endoding: utf-8 -*-# @ModuleName:run# @Function(功能):# @Author : 苏穆冰白月晨# @Time : 2021/5/14 13:28import requestsimport pypinyinimport reimport randomimport timeimport jsonurl_data_pinyin = ''num = 0headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36','accept-language': 'zh-CN,zh;q=0.9'}def request_data(url, id, url_data ,pageeee1):response = requests.get(url, headers = headers).textdata = re.findall("<li title='.*?'>(.*?)</li>", response)for i in data:if '<' in i :i = re.findall('<.*?>(.*?)</a>', i)[0]print(i)for i in range(1, pageeee1):url = 'https://club.jd.com/comment/productPageComments.action?'data = {'callback': 'fetchJSON_comment98', # 调整页数page'productId': str(id), # 商品id'score': 3, # 好评score3,中评2,差评1,0代表全部评论'sortType': 5, # 推荐排序'page': i, # 第几页评论'pageSize': 10, # 一页10条'isShadowSku': 0,'fold': 1}brand = url_datahtml = requests.get(url, params=data, headers=headers).texti = json.dumps(html) # 将页面内容编码成json数据,(无论什么格式的数据编码后都变成了字符串类型str)j = json.loads(i) # 解码,将json数据解码为Python对象comment = re.findall(r'{"productAttr":.*}', j) # 对网页内容筛选找到我们想要的数据,得到值为字典的字符串即'{a:1,b:2}'comm_dict = json.loads(comment[0]) # 将json对象obj解码为对应的字典dictcommentSummary = comm_dict['comments'] # 得到包含评论的字典组成的列表for comment in commentSummary: # 遍历每个包含评论的字典,获得评论和打分颜色版本时间c_content = ''.join(comment['content'].split()) # 获得评论,split()去空格并用join()连接起一整段评论,便于存储color = comment['productColor']name = comment['referenceName']time1 = comment['referenceTime']# productColor: "黑色";productSize: "128GB";creationTime: "2020-06-08 17:53:53";print([brand], [color], [name], [time1], c_content)sleeptime = random.randint(1, 4)time.sleep(sleeptime)sleeptime = random.randint(1, 4)time.sleep(sleeptime)def request_url(url, url_data ,pageeee1,num1 = 0 ):print('请求连接获取成功,链接为 :', url)sleeptime = random.randint(1, 4)time.sleep(sleeptime)response = requests.get(url, headers = headers).texturl_zi_data = re.findall(r'href="(.*?)"\s+.*?>\s+<em>(.*?)</em>', response)data_jiage = re.findall(r'<em>¥</em><i>(.*?)</i>', response)for i in url_zi_data:name = i[1]jiage = data_jiage[num1] + '¥'num1 += 1if '<font class="skcolor_ljg">' in name:name = name.replace('<font class="skcolor_ljg">', '')if '</font>' in name:name = name.replace('</font>', '')url_zi = 'https:' + i[0]data_id = re.findall('m/(.*?).html', url_zi)[0]url_pinglunshu = f'https://club.jd.com/comment/productCommentSummaries.action?referenceIds={data_id}&callback=jQuery4573443&_=1616473554889'headers1 = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}comments = requests.get(url_pinglunshu, headers=headers1).textcomments = re.findall(r'"DefaultGoodCountStr":"(.*?)"', comments)[0]print('\n')print('---------------------------------------------------------------------')print('主题:', name, '价格:', jiage, '评论数:', comments, '详情页面:', url_zi)request_data(url_zi, data_id, url_data ,pageeee1)if __name__ == '__main__':url_data = input('请输入关键字: ')pageeee = int(input('请输入商品页面页数: '))pageeee1 = int(input('请输入商品详情评论数据页数: '))pageeee = pageeee * 2url_data_pinyin_list = pypinyin.pinyin(url_data, style=pypinyin.NORMAL)for i in url_data_pinyin_list:url_data_pinyin += i[0]for i in range(1,pageeee,2):num += 1url = f'https://search.jd.com/Search?keyword={url_data}&wq={url_data}&page={i}&s={num*61}&click=0'request_url(url, url_data ,pageeee1)sleeptime = random.randint(1, 4)time.sleep(sleeptime)