前言
我们在Hugging Face不同模型对应的tokenizer映射字典,不存在某些专有词汇,我们需要新增对应的token,以便我们使用对应模型处理不存在专业词汇。为此,本篇文章针对此问题,记录如何为tokenizer添加对应词汇,便于模型转换。
一、tokenizer添加token
我选择llava对应小羊驼模型的tokenizer,我将其读取为tokenizer,在保存原有tokenizer,随后使用tokenizer.add_tokens添加token,也将其保存,并加载添加后的tokenizer,其详细代码如下:
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained(
'/home/llava_v1.5_lora/vicuna-13b-v1.5',
cache_dir=None,
model_max_length=4096,
padding_side="right",
use_fast=False,
) # 加载语言模型的tokenizer
vocab=["你好", "我完成加载","ok"]
if __name__ == '__main__':
vicuna_dict = tokenizer.get_vocab()
token_vocab = [tokenizer.tokenize(voc) for voc in vocab]
tokenizer.save_pretrained("llava_vicuna_token_ori") # 保存原有的tokenizer
new_tokens = ["你好", "我完成加载"]
# 添加新 token
tokenizer.add_tokens(new_tokens)
# 确保 tokenizer 重新构建词汇表
tokenizer.save_pretrained("llava_vicuna_token") # 保存更新后的tokenizer
tokenizer_ll = transformers.AutoTokenizer.from_pretrained('llava_vicuna_token',
cache_dir=None,
model_max_length=4096,
padding_side="right",
use_fast=False) # 加载语言模型的tokenizer
vicuna_dict_ll = tokenizer_ll.get_vocab()
token_vocab_ll = [tokenizer_ll.tokenize(voc) for voc in vocab]
二、结果比较
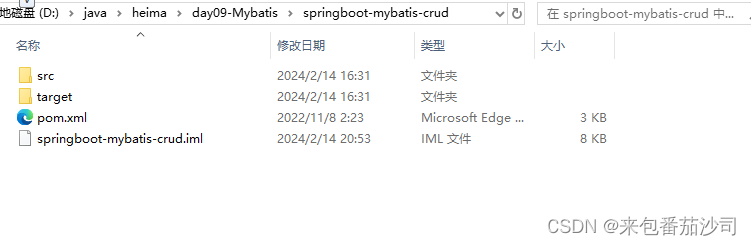
最终我们发现添加token后文件夹多了一个added_tokens.json文件,该文件夹就是我们添加内容。
added_tokens.json内容如下:
{
"你好": 32000,
"我完成加载": 32001
}
文件结果如下:

三、added_tokens.json文件修改
既然文件差异是多了一个字典added_tokens.json文件,那么我想直接把一些字典添加到该文件夹中,是否有效?答案是:肯定的。
1、手动添加token
那么added_tokens.json文件内容如下:
{
"你好": 32000,
"我完成加载": 32001,
"太棒了": 32002
}
2、代码验证添加token
使用代码查看如下:
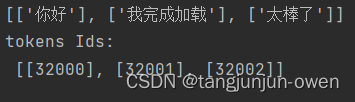
new_tokens = ["你好", "我完成加载","太棒了"]
tokenizer_ll = transformers.AutoTokenizer.from_pretrained('llava_vicuna_token',
cache_dir=None,
model_max_length=4096,
padding_side="right",
use_fast=False) # 加载语言模型的tokenizer
tokens=[tokenizer_ll.tokenize(t) for t in new_tokens]
print(tokens)
ids = [tokenizer_ll.convert_tokens_to_ids(t) for t in tokens]
print("tokens Ids:\n", ids)
3、结果显示
显示结果如下: