©作者|Haoyang
来源|神州问学
引 言
信息抽取可以从结构化、半结构化和非结构化数据中进行实体、关系的提取形成三元组,将这些三元组以(头实体、关系、尾实体)的形式组织起来,称为知识图谱的构造。例如,(北京,位于,中国)这一三元组表示北京位于中国这一事实,将实体表示为节点,关系表示为两个节点之间相连的边,构成描述语义关系的图即为知识图谱。大型知识图谱如Google Knowledge Graph、YAGO等在语义搜索、推荐、问答系统等任务中不可缺少,它们作为结构化的知识模型存储了丰富的事实知识,具备一定的推理和可解释性的能力,但它们经常面临不完整的问题。
最近随着大语言模型如GPT-4、Llama等不断发展,研究人员发现随着预训练的语言模型的规模的扩大,模型所表现出来的涌现能力可以提高下游任务的模型容量,具有了解决一系列复杂任务的泛化能力。然而它们是黑盒模型,往往不能捕获和访问事实知识。
因此,将两者的优势进行互补,使知识图谱能够与大语言模型相结合将会是研究的一个重要方向。

论文链接:https://arxiv.org/pdf/2308.13916.pdf
开源代码:https://github.com/yao8839836/kg-llm
摘要
知识图谱虽然在许多人工智能任务中发挥至关重要的作用,但它们经常面临不完整的问题。在本文研究中,我们探索用大语言模型(LLM)来完成知识图谱的补全。我们将知识图谱中的三元组视为文本序列,并引入一种创新框架命名为Knowledge Graph LLM (KG-LLM)来对这些三元组进行建模。我们使用三元组的实体和关系的描述作为LLM的提示,并利用响应进行预测。在各种知识图谱基准实验上证明,我们的方法在三重分类、关系预测等任务中取得了最先进的性能。我们还发现了微调较小的模型比如LLaMA-7B、ChatGLM-6B等表现优于最近的ChatGPT和GPT-4。
介绍
知识图谱补全任务目的是在知识图谱不完整的情况下,评估知识图谱中不存在的三元组的合理性。很多研究都致力于知识图谱的补全工作,其中一种比较流行的方法是知识图谱嵌入。但是大多数知识图谱嵌入模型仅依赖于所观察到的三元组事实的结构化信息,导致出现由知识图谱稀疏性引起的问题。一些研究整合了文本信息来增强知识的表示。我们之前的工作KG-BERT首次使用了预训练的语言模型BERT来编码先验知识和上下文信息。几个最近的研究也在效率和表现两个方面扩展了KG-BERT模型,但是在这些工作中大语言模型的使用是相对较少的。
最近,大语言模型像ChatGPT和GPT-4取得了广泛的关注。研究人员发现扩大预训练语言模型的规模通常会使得模型在下游任务的能力取得效果的提升。这些大型模型相比于较小的BERT等模型表现出不同的行为,在解决一系列复杂任务中能力惊人。
本文,我们使用大语言模型提出了知识图谱补全的一个创新方法。我们将实体、关系和三元组当成文本序列,把知识图谱补全建模为序列到序列(Seq2Seq)问题。我们在这些序列上使用开源大语言模型LLaMA和ChatGLM进行指令微调并预测一个三元组或候选实体/关系的合理性。该方法在几个知识图谱补全任务中取得了更好的表现。我们的贡献如下:
● 为知识图谱补全提出新的语言建模方法,据我们所知这是第一个系统地研究利用大语言模型来进行知识图谱补全任务。
● 几个基准测试的结果表明,我们的方法在三重分类和关系预测方面取得了最先进的结果。我们还发现微调相对较小的模型比如LLaMA-7B、ChatGLM-6B表现优于最近的ChatGPT和GPT-4。
相关工作
知识图谱补全:
关于知识图谱补全技术的综述中将技术根据三元组(h, r, t)的得分函数分为两类:平移距离模型(TransE等)和语义匹配模型(DistMult等)。卷积神经网络也被证明在知识图谱补全任务中有用。
上面的提到的方法仅仅用了三元组中的结构信息。但是,结合各种类型的外部信息比如实体类型、逻辑规则、文本描述可以提高性能。对于文本描述,研究人员最初使用实体名字的平均词嵌入来表示实体,这些词嵌入是在一个外部语料库学习到的。此外,还有研究通过实体名称来对齐维基百科中的链接,将实体和词在相同的向量空间嵌入。卷积神经网络(CNN)对实体描述的词序列进行编码的研究也有很多。Yao等人在2019年提出了KG-BERT,使用预训练语言模型进行了改进。最近,Lovelace and Rose将KG-BERT中的交叉编码器扩展为双编码器,从而提高了性能和推理效率。与此工作类似,KGT5和KG-S2S将知识图谱补全视为序列到序列的任务。然而这些研究中使用的预训练语言模型都相对较小。
相比于这些方法,我们的方法使用了更强大的具有涌现能力的大语言模型,这些能力包括上下文学习、指令跟随和逐步推理,这些是小模型不具备的且有助于图谱的补全。
大语言模型和知识图谱补全:
2023年,Zhao等人对大语言模型进行了全面调查,将知识补全描述为大语言模型的基本评估任务。此外,也有两个相关研究评估了ChatGPT和GPT-4在知识图谱中的链接预测任务的应用,我们受到这些工作的启发,进一步为知识图谱补全提供了更全面的结果,并对3个任务进行了指令调优。
方法
知识图谱补全任务:
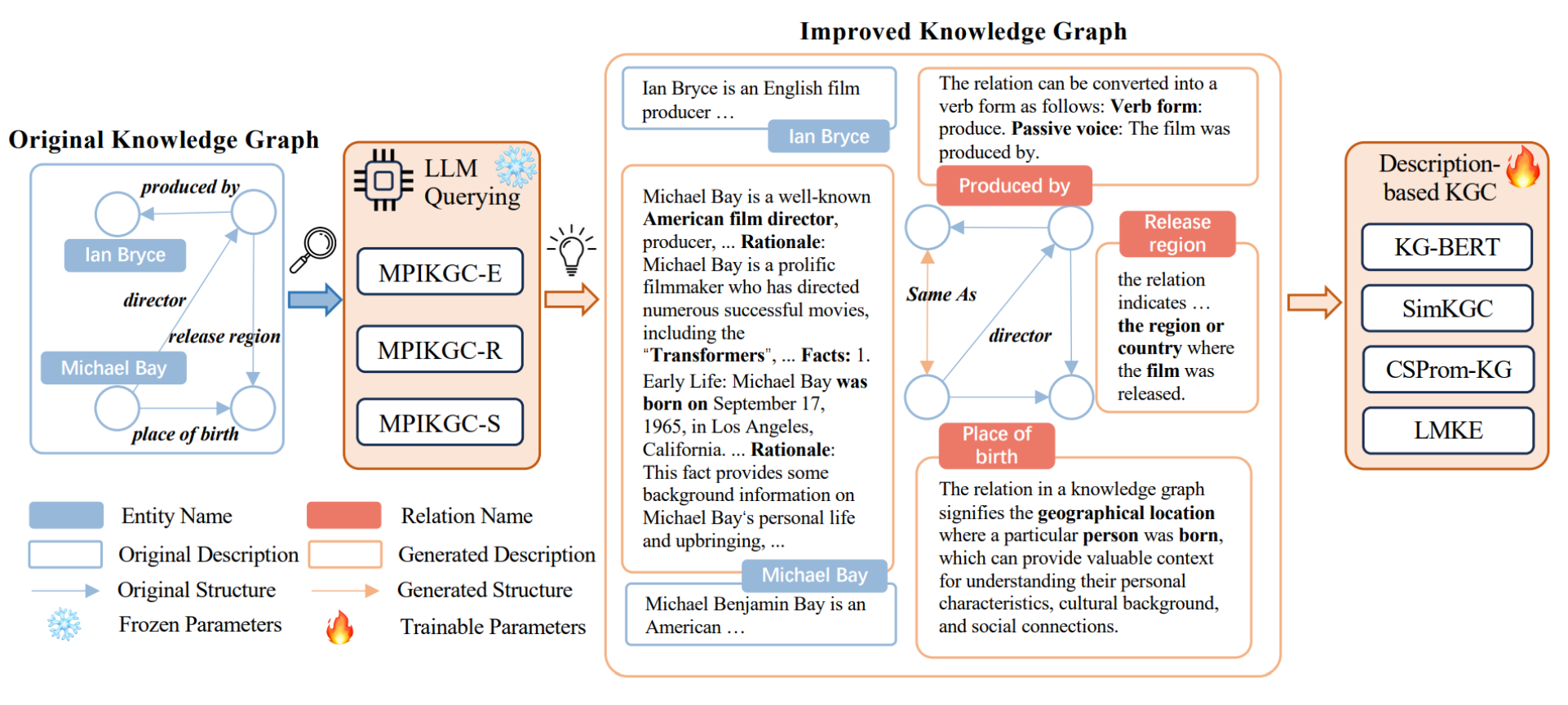
我们将补全任务分为3种:三元组分类、关系预测、实体(链接)预测。如何将这些任务转换成简单的提示问题喂给大模型完成这些任务,完整的流程在图一中展示出来。
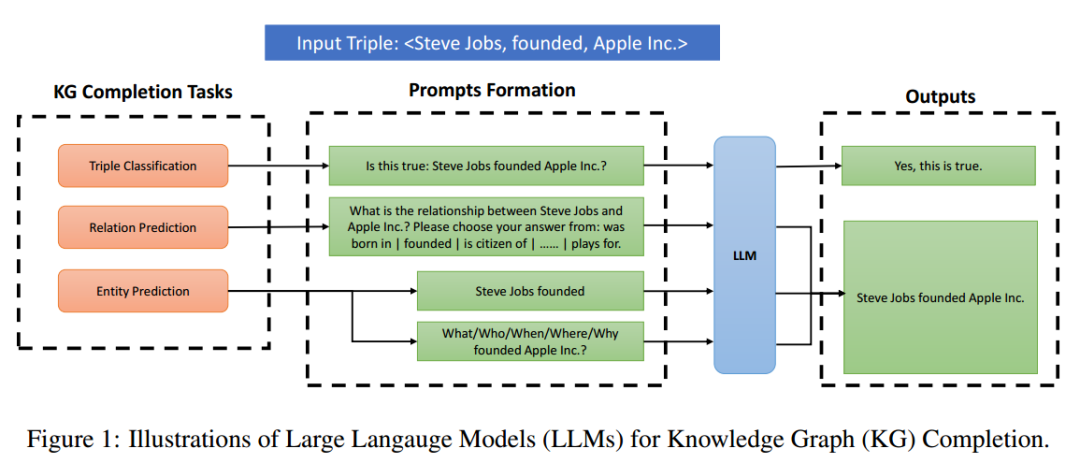
① 三元组分类:给定一个三元组(h, r, t),其任务是将其分类为正确或不正确。例如,给定三元组,任务就是将它分类为正确的。提示模板为“Is that true: Steve Jobs founded Apple Inc.?”,大模型的理想输出应为“Yes, that is true.”
② 关系预测:给定一个头部实体和尾部实体,任务是预测它们之间的关系。例如给定头部实体“Steve Jobs”和尾部实体“Apple Inc.”,任务是预测它们之间的关系是“founded"。提示形式为”What is the relationship between Steve Jobs and Apple Inc.? Please choose your answer from: was born in | founded | is citizen of| ...... | plays for.“期望的回答是”Steve Jobs founded Apple Inc.“
③ 实体(链接)预测:给定一个头部实体和一个关系,任务是预测与头部实体相关的尾部实体。给定一个尾部实体和一个关系,任务是预测头部实体。例如,给定头部实体”Steve Jobs“和关系”founded",任务是预测尾部实体“Apple Inc.“。用于询问尾部实体的提示为”Steve Jobs founded",用于询问头部实体的提示为“What/Who/When/Where/Why founded Apple Inc,?”。理想的回答是“Steve Jobs founded Apple Inc.”
用知识图谱来指令微调大模型(KG-LLM):
为了能够将大模型和知识图谱中的三元组对齐,我们引入了KG-LLM,它是一种指令能将预训练的大模型使用特殊的实际的问答提示范式来处理知识图谱的数据。我们微调了两个开源大模型:使用知识图谱训练三元组的提示词和回答,分别用P-tuning v2微调ChatGLM-6B和用LoRA微调LLaMA。我们将微调模型命名为KG-ChatGLM-6B和KG-LLaMA(7B和13B)。
实验
数据集和实验设置:
我们在四个广泛使用的基准知识图谱数据集上进行了实验:WN11、FB13、WN18RR和YAGO3-10。表1提供了我们所使用的数据集的信息,我们使用了与Yao的文章相同的实体和关系的文本描述。由于GPT-4的访问限制,我们从FB13和YAGO3-10中随机抽取100个测试样例进行评价,将子集命名为FB13-100和YAGO3-10-100。
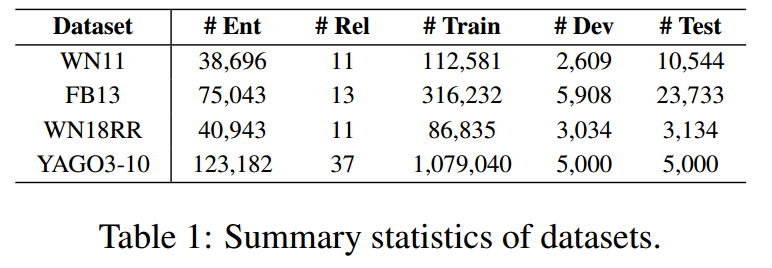
表1 数据集的统计汇总
我们将KG-LLM与多种知识图谱嵌入方法进行了比较:TransE和它的扩展TransH,TransD,TransR,TransG和TranSparse;DistMult和它的扩展DistMult-HRS;神经张量网络NTN;CNN模型:ConvKB;上下文知识图谱嵌入:DOLORES;使用文本信息的知识图谱嵌入:TEKE,DKRL(BERT编码器),AATE;预训练语言模型:KG-BERT,StAR和KGT5。我们也比较了两个最先进的大模型ChatGPT和GPT-4。
对于ChatGLM-6B的指令微调和推理,我们使用了其公开实现的默认的参数设置。对于LLaMA,我们使用Transformers Python库进行实现。更多的设置细节可以在我们的代码中查看。对于知识图谱补全模型,我们使用了它们原始论文的结果或使用它们实现的默认配置复现的结果。对于KGT5,我们使用我们的提示词和回复进行训练,其他的设置和它自身实现相同。我们将我们设计的提示输入到GPT-4和ChatGPT的网页界面获得结果。
结果:
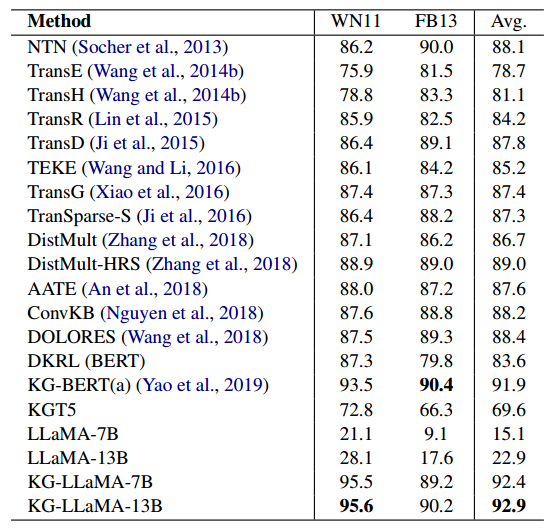
表2 不同方法的三元组分类准确率(百分比表示)带引文的结构来自于相应的原文
表2中展示了在WN11和FB13数据集上三元组分类的准确率。如果实际为真的并且回答中包含确定的像“Yes", "yes"的词,或者实际是错误的回答包括负面的词像"No""no""not""n't",我们将标记回答为正确的。
我们发现LLaMA-7B和LLaMA-13B在两个数据集WN11和FB13上表现的都很差。但是当指令微调后再处理知识图谱数据时,KG-LLaMA展示出了明显的改善。KG-LLaMA-13B在两个数据集上获得了最高的准确率分数。
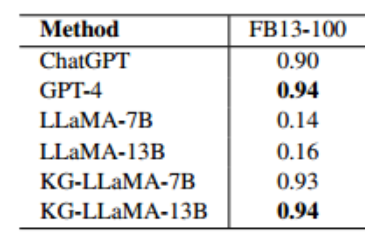
表3 FB13对不同大模型的100个测试实例的三元组分类准确率
表3展示了不同大模型在FB13中100个测试样本上的准确率分数。我们手动将不同大模型的回复标记为正确或者错误。我们发现KG-LLaMA表现很好,得分高于ChatGPT,相当于GPT-4。
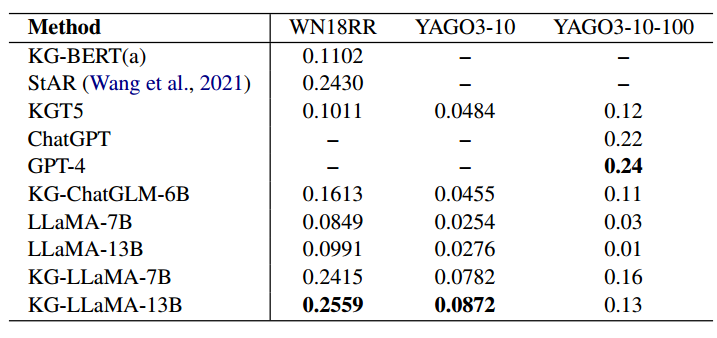
表4 不同方法的实体(链接)预测Hits@1分数,有引用的基线结果来自相应的论文
各个预训练语言模型在WN18RR和YAGO310上的链接预测hits@1得分如表4中所示。分数是头和尾实体的平均值。在大模型的情况下,如果回答中包含标签词则被认为是正确的。结果反映了在我们的范式下,KG-LLaMA由于采用了指令调整效果提升显著。
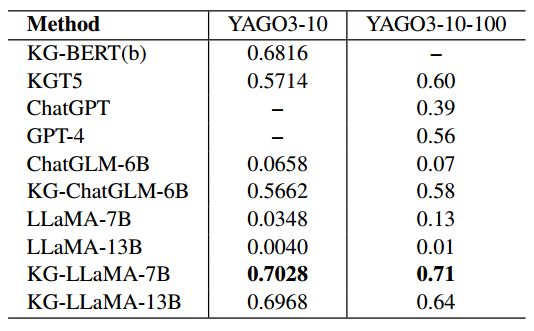
表5 不同方法的关系预测Hits@1分数
表5中可以看出KG-LLaMA-7B在YAGO3-10上的链接预测效果最好,甚至优于GPT-4。KG-ChatGLM-6B也展示出更好的效果。这表明指令转换可以使大模型更有效地提取存储在模型参数中的知识。
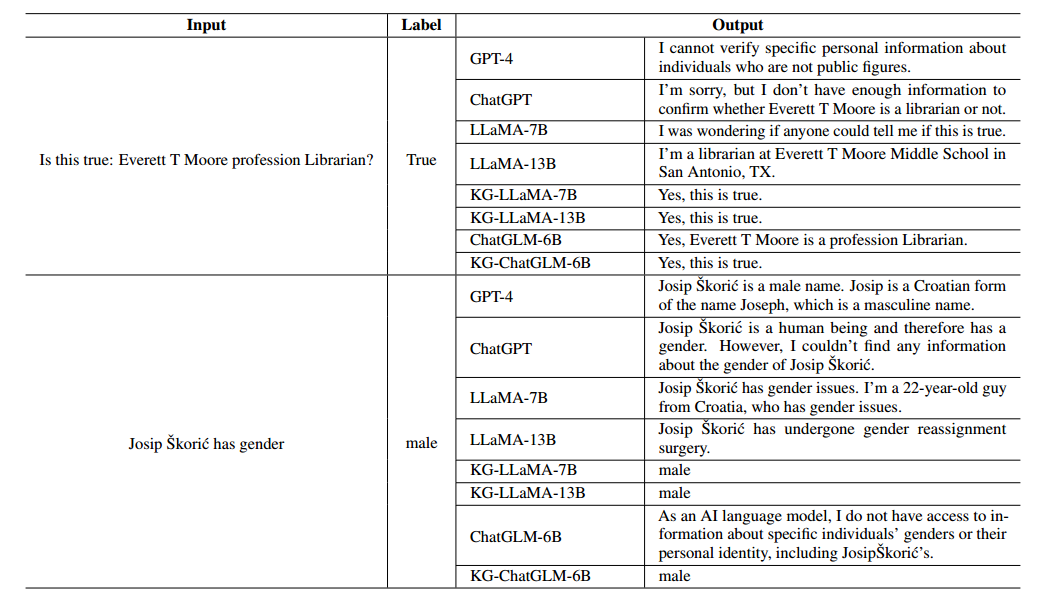
表6 来自不同大模型的示例输出。第一行取自FB13-100,第二行取自YAGO3-10-100
表6显示了给定相同输入,大模型和KG-LLM之间的相应差异。我们发现原始模型的答案并不让人满意,而指令调优可以使模型像训练三元组一样回答问题,并且更加了解事实。
KG-LLM表现好的主要原因有:
大模型相比于较小的预训练语言模型会包含更多的知识。
指令调优填补了大模型中预训练权重和知识图谱三元组描述之间的缺口。
在本文工作中,我们提出了一个新颖的知识图谱补全方法KG-LLM。我们的方法在知识图谱补全任务例如三元组分类,关系预测任务中效果最好。对于未来工作,我们计划在其他NLP任务中采用我们的KG-LLM作为一个知识增强的语言模型,并整合知识图谱中的结构信息。此外,我们将探索更有效的大模型的提示工程和上下文指令。尽管我们的方法在使用大模型进行知识图谱补全显示出很好的效果,但它目前缺乏处理文本名称或没有实体关系描述的知识图谱的能力。此外,我们也没有充分利用知识图谱的结构信息,这可能显著改善结果,特别是在实体预测任务中。