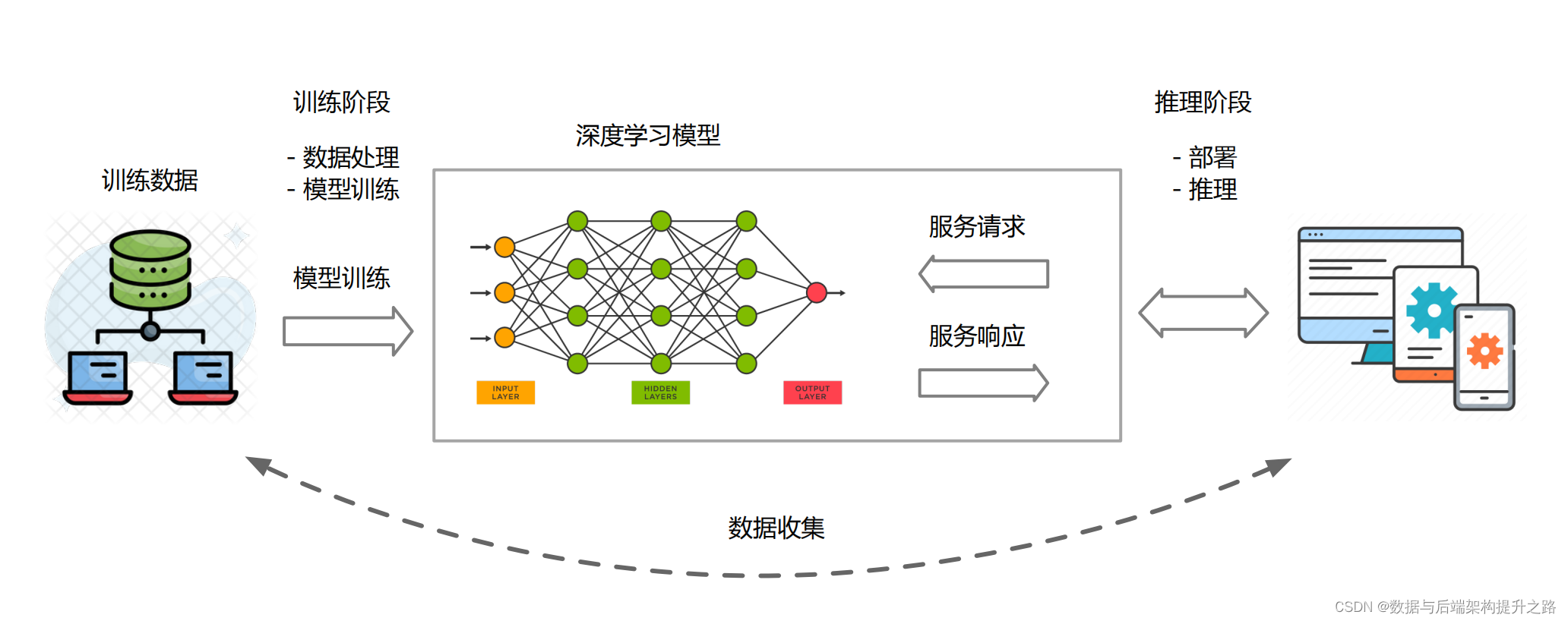
1. 深度学习模型架构
常见的深度学习模型架构包括:
1. 卷积神经网络(Convolutional Neural Network,CNN):主要用于处理图像和视频数据,具有平移不变性和局部连接性。
2. 循环神经网络(Recurrent Neural Network,RNN):适用于处理序列数据,如文本、语音和时间序列数据,能够捕捉数据中的时间依赖关系。
3. 长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU):RNN的变种,专门用于解决长期依赖问题,适用于需要记忆长距离依赖关系的任务。
4. 生成对抗网络(Generative Adversarial Network,GAN):用于生成新的数据样本,如图像、音频等,通过对抗训练方式学习生成数据的分布。
5. 注意力模型(Attention Model):适用于处理序列数据,特别是在自然语言处理任务中,能够聚焦于输入中的关键部分。
6. 自编码器(Autoencoder):用于学习数据的压缩表示,常用于无监督学习和降维任务。
7. 转换器(Transformer):主要用于处理序列数据,尤其在自然语言处理领域,如机器翻译和语言建模。
每种模型架构都有其特定的优点和适用场景,选择模型架构应根据具体的任务需求和数据特点进行。
2. CNN(卷积神经网络)模型
2.1 CNN(卷积神经网络)模型的基本结构
包括以下几个部分:
1. 输入层(Input Layer):接收输入数据的层,通常是图像或其他高维数据。
2. 卷积层(Convolutional Layer):卷积层是CNN的核心。通过卷积操作提取输入数据的特征。每个卷积层通常包括多个卷积核(filter),每个卷积核对输入进行卷积操作得到不同的特征图(feature map)。
卷积核的参数涉及:大小、步长、填充等。
3. 激活函数层(Activation Layer):对卷积层的输出进行非线性变换,增加模型的非线性拟合能力。常用的激活函数包括ReLU、Sigmoid、Tanh等。不同激活函数的特点,以及如何选择适合的激活函数
4. 池化层(Pooling Layer):通过降采样操作减小特征图的尺寸,减少参数数量,提高计算效率,同时保留主要的特征。常用的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
不同池化方法(如最大池化和平均池化)的原理和参数设置,以及它们对特征的影响。
5. 全连接层(Fully Connected Layer):将卷积层的输出展平成一维向量,并通过全连接操作连接到输出层。全连接层通常用于分类或回归任务。
2.2 CNN 示例
import torch
import torch.nn as nn
# 定义简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = self.fc(x)
return x
# 创建网络实例
net = SimpleCNN()3. RNN(循环神经网络)模型
3.1 RNN(循环神经网络)模型的基本结构
包括输入层、隐藏层和输出层。不同的RNN变体可能会在这个基本结构上进行扩展或修改。
1. 输入层:接收序列数据的输入,例如文本或时间序列数据。
2. 隐藏层:通过循环连接,将当前时刻的输入和前一时刻的隐藏状态结合起来。隐藏层的输出会传递给下一时刻的隐藏层作为输入,同时也可以作为输出层的输入。隐藏层在RNN中具有记忆功能,可以捕捉到序列数据的上下文信息。
3. 输出层:根据任务的不同,输出层可以是分类层、回归层或者序列生成层。输出层的结果可以用来预测下一个时刻的值、进行分类、生成序列等。
在传统的RNN结构中,隐藏层的输出会通过一个激活函数,如tanh或ReLU,进行非线性映射。然而,传统的RNN存在梯度消失或梯度爆炸的问题,导致长序列的依赖关系难以捕捉。因此,研究人员提出了一些改进的RNN变体,如LSTM(长短期记忆网络)和GRU(门控循环单元),来解决这些问题。
这些改进的RNN变体在基本的RNN结构上增加了门控机制,使模型能够更好地控制信息的流动和记忆的更新。这些门控机制可以选择性地保留或丢弃信息,从而提高模型对长期依赖关系的建模能力。
总结起来,RNN模型的基本结构包括输入层、隐藏层和输出层。隐藏层通过循环连接捕捉序列数据的上下文信息,输出层根据任务的不同进行相应的输出。改进的RNN变体(如LSTM和GRU)通过门控机制来增强模型的记忆和控制能力。
3.2 RNN示例
import torch
import torch.nn as nn
# 定义简单的RNN模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
out, hidden = self.rnn(x, hidden)
out = self.fc(out)
return out, hidden
# 创建网络实例
input_size = 10
hidden_size = 20
output_size = 5
net = SimpleRNN(input_size, hidden_size, output_size)4. LSTM(长短期记忆网络)
4.1 LSTM(长短期记忆)模型的基本结构
LSTM(长短期记忆)模型是一种循环神经网络(RNN)的变种,具有记忆单元和门控机制,用于解决长序列数据的建模问题。LSTM模型的基本结构包括输入门、遗忘门、输出门和记忆单元。
1. 输入门(Input Gate):决定是否将当前输入的信息纳入到记忆单元中。通过对输入数据和前一 时刻的隐藏状态进行线性变换和激活函数处理,生成一个介于0和1之间的门控向量。与门控向量相乘后,可以决定哪些信息需要被保留。
2. 遗忘门(Forget Gate):决定是否将前一时刻的记忆单元的信息保留到当前时刻。通过对输入数据和前一时刻的隐藏状态进行线性变换和激活函数处理,生成一个介于0和1之间的门控向量。与门控向量相乘后,可以决定哪些信息需要被遗忘。
3. 输出门(Output Gate):决定当前时刻的记忆单元状态的输出。通过对输入数据和前一时刻的隐藏状态进行线性变换和激活函数处理,生成一个介于0和1之间的门控向量。与门控向量相乘后,可以决定哪些信息需要被输出。
4. 记忆单元(Cell State):用于存储和传递记忆信息的状态。记忆单元根据输入门、遗忘门和输出门的控制,对当前输入和前一时刻的记忆单元状态进行更新和调整。
LSTM模型的参数设置包括隐藏层大小、输入维度、输出维度、激活函数等。根据具体任务和数据的特点,可以根据实验和调优来选择最佳的参数设置。在训练过程中,这些参数会根据梯度下降等优化算法进行更新,以最小化损失函数。参数的合理设置和调整是LSTM模型训练和性能优化的重要方面。
4.2 LSTM示例
import torch
import torch.nn as nn
# 定义一个简单的LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# 定义输入数据和模型参数
input_size = 10
hidden_size = 20
num_layers = 2
output_size = 1
seq_length = 5
batch_size = 3
# 创建模型和随机输入数据
model = LSTMModel(input_size, hidden_size, num_layers, output_size)
input_data = torch.randn(batch_size, seq_length, input_size)
# 将数据输入模型并获取输出
output = model(input_data)
print(output)
5. GAN(生成对抗网络)
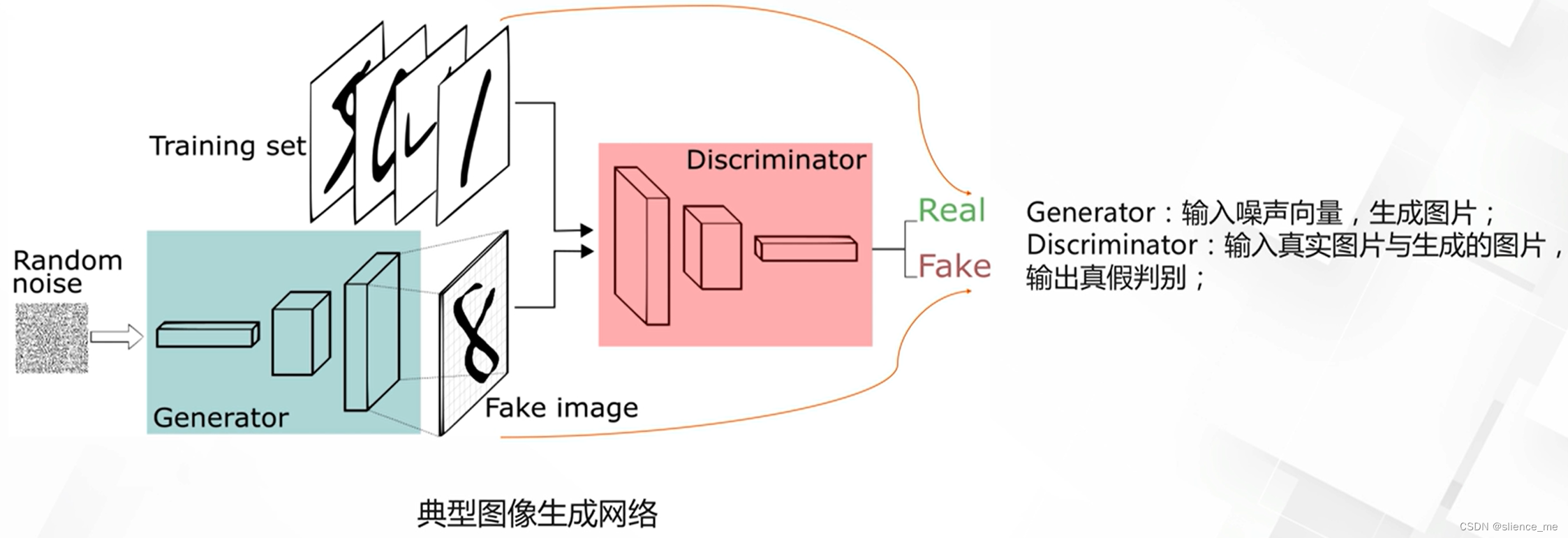
5.1 GAN的基本结构
GAN(Generative Adversarial Network,生成对抗网络)模型由两部分组成:生成器(Generator)和判别器(Discriminator)。这两部分分别构成了一个博弈的过程,其中生成器试图生成逼真的数据样本,而判别器试图区分真实数据和生成器生成的数据。它们相互对抗、相互学习,最终使得生成器能够生成逼真的数据样本。
生成器的基本结构:通常是一个神经网络,它接收一个随机噪声向量作为输入,并输出一个数据样本,如图像、文本等。
判别器的基本结构:也是一个神经网络,它接收真实数据样本或生成器生成的数据样本作为输入,并输出一个标量,表示输入数据是真实数据的概率。
整个GAN模型的训练过程是通过最小化生成器和判别器的损失函数来实现的。生成器试图最小化生成的样本被判别为假的概率,而判别器试图最小化将生成的样本错误分类为真实或假的概率。这种对抗训练的过程最终使得生成器能够生成逼真的数据样本。
总之,GAN模型的基本结构由生成器和判别器组成,二者通过对抗训练的方式共同学习,以达到生成逼真数据样本的目的。
5.2 GAN示例
以下是一个简单的使用PyTorch实现的生成对抗网络(GAN)示例,其中包括一个简单的生成器和鉴别器。在此示例中,我们使用MNIST数据集来生成手写数字图像。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Generator, self).__init__()
self.map1 = nn.Linear(input_size, hidden_size)
self.map2 = nn.Linear(hidden_size, hidden_size)
self.map3 = nn.Linear(hidden_size, output_size)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(self.map1(x))
x = self.activation(self.map2(x))
return self.map3(x)
# 定义鉴别器
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Discriminator, self).__init__()
self.map1 = nn.Linear(input_size, hidden_size)
self.map2 = nn.Linear(hidden_size, hidden_size)
self.map3 = nn.Linear(hidden_size, output_size)
self.activation = nn.LeakyReLU(0.2)
def forward(self, x):
x = self.activation(self.map1(x))
x = self.activation(self.map2(x))
return torch.sigmoid(self.map3(x))
# 定义训练参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lr = 0.0002
z_dim = 100
image_dim = 28 * 28
batch_size = 128
num_epochs = 50
# 初始化生成器和鉴别器
G = Generator(input_size=z_dim, hidden_size=128, output_size=image_dim).to(device)
D = Discriminator(input_size=image_dim, hidden_size=128, output_size=1).to(device)
# 定义损失函数和优化器
criterion = nn.BCELoss()
d_optimizer = optim.Adam(D.parameters(), lr=lr)
g_optimizer = optim.Adam(G.parameters(), lr=lr)
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
mnist_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
data_loader = DataLoader(dataset=mnist_dataset, batch_size=batch_size, shuffle=True)
# 训练GAN
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(data_loader):
real = real.view(-1, image_dim).to(device)
# 训练鉴别器
d_optimizer.zero_grad()
z = torch.randn(batch_size, z_dim).to(device)
fake = G(z)
real_output = D(real)
fake_output = D(fake)
d_loss = -(torch.mean(torch.log(real_output) + torch.log(1 - fake_output)))
d_loss.backward()
d_optimizer.step()
# 训练生成器
g_optimizer.zero_grad()
z = torch.randn(batch_size, z_dim).to(device)
fake = G(z)
fake_output = D(fake)
g_loss = -torch.mean(torch.log(fake_output))
g_loss.backward()
g_optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch [{epoch}/{num_epochs}], Batch Step [{batch_idx}/{len(data_loader)}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}")
# 生成器训练后,可以使用生成器G生成数字图像
6. 注意力模型
6.1 注意力模型结构
注意力模型通常包括以下组件:
1. 输入表示:输入数据通常会经过一些表示学习的层,如卷积层或循环神经网络(RNN)等,以便将输入数据转换为适合注意力计算的形式。
2. 注意力机制:这是注意力模型的核心部分,用于计算不同部分的输入对输出的影响程度。在注意力机制中,通常会计算每个输入位置的注意力权重,这些权重会根据输入的相关性来动态调整,以便在后续的处理中更加关注重要的部分。
3. 上下文表示:基于计算得到的注意力权重,输入的表示会被加权组合,形成一个综合的上下文表示,这个上下文表示会更加关注重要的部分,从而为后续的处理提供更多信息。
总之,注意力模型的结构包括输入表示、注意力机制和上下文表示。这些组件相互作用,使得模型能够在处理输入数据时更加灵活和准确。
6.2 注意力模型示例
在这个示例中,定义了一个简单的注意力层`Attention`,在`forward`方法中计算了注意力权重,并返回了上下文张量和注意力权重。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, input_dim, attention_dim):
super(Attention, self).__init__()
self.W = nn.Linear(input_dim, attention_dim)
self.v = nn.Linear(attention_dim, 1, bias=False)
def forward(self, encoder_outputs):
energy = torch.tanh(self.W(encoder_outputs))
attention = F.softmax(self.v(energy), dim=1)
context = attention * encoder_outputs
return context, attention
# 示例用法
input_dim = 100
attention_dim = 50
encoder_outputs = torch.rand(10, 20, input_dim) # 输入数据格式为 (sequence_length, batch_size, input_dim)
attention_layer = Attention(input_dim, attention_dim)
context, attention_weights = attention_layer(encoder_outputs)
print(context.shape) # 输出注意力机制得到的上下文张量的形状
print(attention_weights.shape) # 输出注意力权重的形状
7. 自编码器
7.1 自编码器的结构
自编码器通常包括以下组件:
1. 编码器(Encoder):编码器部分负责将输入数据进行压缩和提取关键特征,通常由多个隐藏层组成,每个隐藏层包含多个神经元。编码器的输出通常是输入数据的压缩表示。
2. 解码器(Decoder):解码器部分接收编码器的输出,负责将压缩表示的数据解码成与原始输入数据尽可能相似的数据。解码器也由多个隐藏层组成,通常会对编码器的输出进行逐步恢复,直到达到原始输入数据的维度。
3. 损失函数(Loss Function):自编码器的目标是使解码器的输出尽可能接近输入数据。因此,损失函数通常衡量解码器输出与原始输入的差异,并通过反向传播调整编码器和解码器的参数,以最小化重构误差。
总之,自编码器的结构包括编码器、解码器和损失函数。这些组件相互作用,使得自编码器能够学习数据的有效表示,并且能够在解码器阶段重构出与原始输入数据相似的输出。
7.2 自编码器示例
这个示例中,我们定义了一个简单的自编码器模型,并使用MNIST数据集进行训练。然后,我们展示了如何使用训练好的自编码器来重建图像。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 定义自编码器模型
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True))
self.decoder = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Sigmoid())
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor()])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=32, shuffle=True)
# 初始化模型、损失函数和优化器
autoencoder = Autoencoder()
criterion = nn.MSELoss()
optimizer = optim.Adam(autoencoder.parameters(), lr=0.001)
# 训练自编码器
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for data in trainloader:
inputs, _ = data
inputs = inputs.view(-1, 28*28)
optimizer.zero_grad()
outputs = autoencoder(inputs)
loss = criterion(outputs, inputs)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('Epoch {} Loss: {}'.format(epoch+1, running_loss/len(trainloader)))
# 使用自编码器进行图像重建
import matplotlib.pyplot as plt
import numpy as np
dataiter = iter(trainloader)
images, labels = dataiter.next()
img = images[0]
img = img.view(-1, 28*28)
output = autoencoder(img)
output = output.view(1, 28, 28)
fig, axs = plt.subplots(1, 2)
axs[0].imshow(np.squeeze(img.view(28, 28)), cmap='gray')
axs[1].imshow(np.squeeze(output.data.numpy()), cmap='gray')
plt.show()
8. 转换器(Transformer)
8.1 转换器的基本结构
转换器(Transformer)是一种用于自然语言处理和其他序列到序列任务的架构。
它的结构主要包括以下组件:
1. 注意力机制(Attention Mechanism):Transformer中的核心组件之一,它允许模型在处理输入序列时关注输入序列中不同位置的信息,而无需通过递归或卷积来实现。通过自注意力机制,模型可以更好地捕获输入序列中不同位置之间的依赖关系。
2. 编码器(Encoder):编码器由多个编码器层组成,每个编码器层包括自注意力子层和前馈神经网络子层。编码器负责将输入序列编码成一系列隐藏表示,以捕获输入序列的结构和语义信息。
3. 解码器(Decoder):解码器也由多个解码器层组成,每个解码器层同样包括自注意力子层、编码器-解码器注意力子层和前馈神经网络子层。解码器负责生成输出序列,同时利用编码器的隐藏表示和自注意力机制来捕获输入和输出序列之间的依赖关系。
4. 位置编码(Positional Encoding):由于Transformer没有内置的序列顺序信息,因此需要添加位置编码来为模型提供关于输入序列中单词位置的信息。
总之,Transformer的结构主要由注意力机制、编码器、解码器和位置编码组成,这些组件相互作用,使得Transformer能够有效地处理序列到序列的任务。
8.2 转换器的示例
我们定义了一个简单的 Transformer 模型,并且实例化了这个模型,输入一些示例数据进行前向传播。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Transformer
# 定义一个简单的 Transformer 模型
class SimpleTransformerModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_heads, num_layers):
super(SimpleTransformerModel, self).__init__()
self.transformer = Transformer(d_model=input_dim, nhead=num_heads, num_encoder_layers=num_layers)
self.fc = nn.Linear(input_dim, hidden_dim)
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc(x)
x = x.permute(1, 0, 2) # 将输入转换为 (sequence_length, batch_size, input_size)
output = self.transformer(x) # 使用 Transformer 进行转换
output = output.permute(1, 0, 2) # 将输出转换回 (batch_size, sequence_length, input_size)
output = self.output_layer(output)
return output
# 实例化模型并进行前向传播
model = SimpleTransformerModel(input_dim=512, hidden_dim=256, output_dim=10, num_heads=8, num_layers=4)
input_data = torch.rand(20, 32, 512) # 20个序列,每个序列长度为32,输入维度为512
output = model(input_data)
print(output.shape) # 打印输出的形状