目录
1 前言
为了指导学习过程,强化学习使用从环境生成的标量奖励信号。该信号衡量agent相对于任务目标的性能。换句话说,对于给定的观察(状态),奖励衡量采取特定action的即时有效性。在训练期间,agent会根据收到的不同state-action组合的奖励来更新其策略。
一般来说,积极的奖励来鼓励某些agent的行为,消极的奖励(惩罚)会阻止其他行动。好的奖励信号会引导agent最大化长期累积奖励的期望。
例如,当agent必须尽可能长时间地执行任务时,常见的策略是在成功执行任务的每个时间步提供小的正奖励,而在任务失败时提供较大的惩罚。这种方法鼓励更长的训练时间,并有效阻止导致agent失败的行动。
如果奖励函数包含多个信号,例如位置、速度和控制代价,则必须考虑信号的相对大小,并相应地调整它们对奖励信号的贡献。
奖励信号可以是连续或离散的,但要求其能在action和observation信号发生变化时提供丰富的信息。
在已有的控制系统应用中,已存在较好的成本函数和约束规范,可以直接使用此类规范生成奖励函数。
2 Continuous Rewards 连续奖励
连续奖励函数会随着环境action和observation的变化而不断变化。一般来说,连续奖励信号可以改善训练过程中的收敛性,并可以产生更简单的网络结构。
连续奖励的一个例子是二次调节器(QR)成本函数,其累积长期奖励可以表示为:
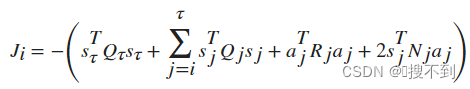
其中





























![vue2的ElementUI的form表单报错“Error: [ElementForm]unpected width”修复](https://img-blog.csdnimg.cn/direct/313acc9568e3443f8fa46709f2210b19.png)
![[Angular 基础] - 自定义指令,深入学习 directive](https://img-blog.csdnimg.cn/direct/81684ce270e9446f925100de5f113a5e.png)