按照数据结构来组织、存储和管理数据的仓库。
是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库:数据库是一些关联表的集合。
数据表:表是数据的矩阵。
列:一列包含相同类型的数据。
行:也称为记录,表示一组相关的数据。
主键:主键是唯一的,一个数据表只能包含一个主键。
外键:外键用来关联两个表,来保证参照完整性;MyISAM 存储引擎本身并不支持外键,只起到注释作用,而 InnoDB 完整支持外键。
索引:用于快速访问数据表的数据,索引是对表中的一列或者多列的值进行排序的一种结构。
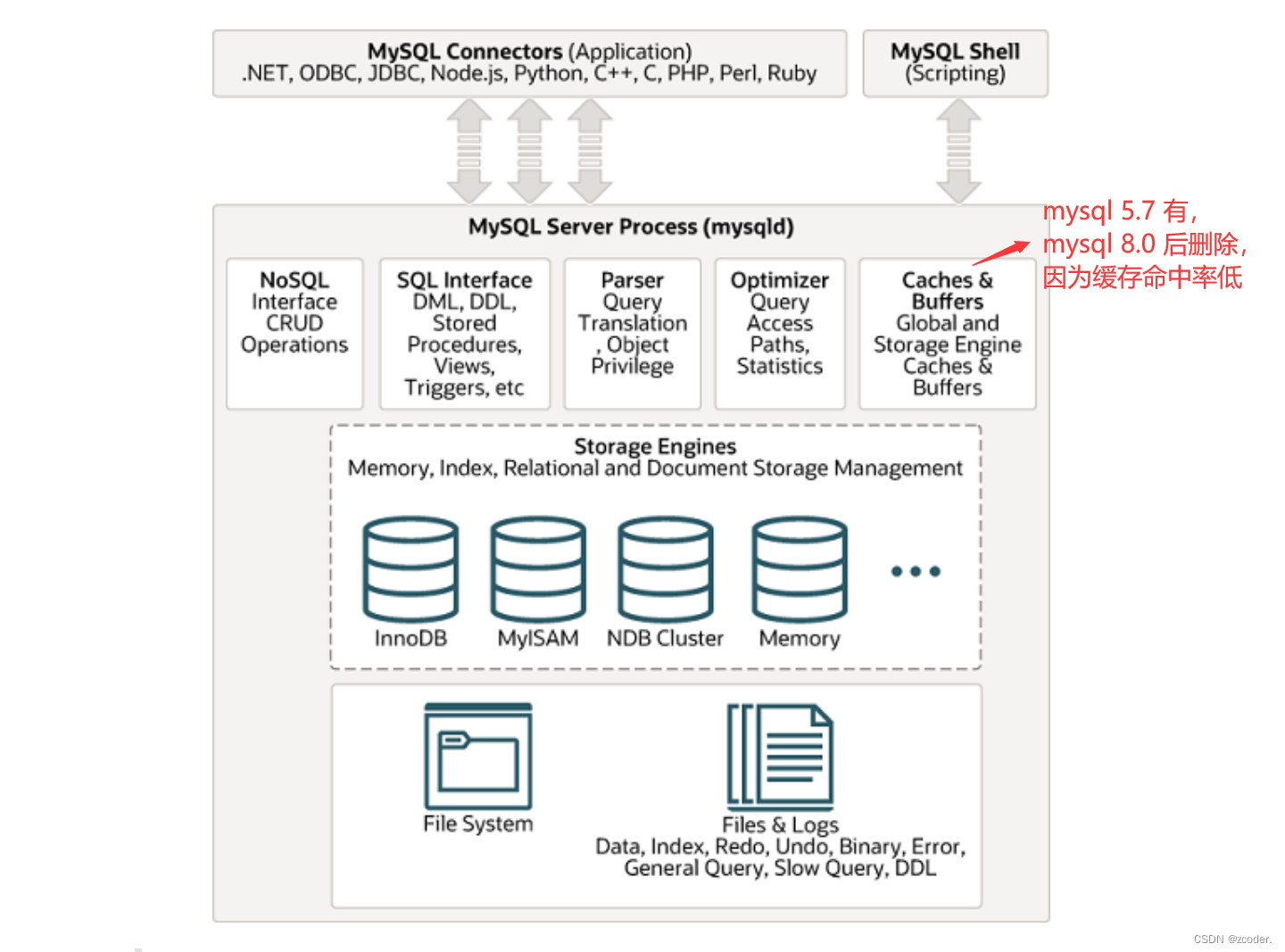
首先有一个 MySQL Connectors,也就是应用层所对应的驱动(和 MySQL 数据库进行交互),它支持不同的语言。
然后是 MySQL Server Process,它分为两个部分:
Server 层:主要作用是计算,对客户端发来的具体的 SQL 语句进行词法、句法分析,生成语法树,然后会生成执行计划。
SQL 接口:将 SQL 语句解析生成相应对象:DML、DDL、存储过程、视图、触发器等(词法、句法分析)。
查询解析器:将 SQL 对象交由解析器验证和解析,并生成语法树(如果不满足 SQL 语句的标准就 return)。
查询优化器:SQL 语句执行前使用查询优化器进行优化(根据 SQL 语句生成执行计划,通常会为一个 SQL 语句生成多条执行计划,再分别计算每条执行计划的代价,最后选择代价最小的执行计划)。
存储引擎层:主要作用是存储,MySQL 支持可插拔的存储引擎,可以在创建表的时候选择不同的存储引擎去处理这张表,常用的是 InnoDB(支持完备的事务)。存储引擎层仅仅向 Server 层提供一套接口。
Server 层生成执行计划后,会调用存储引擎层所提供的接口:
管理缓存数据。
制定策略:数据什么时候,以什么形式写入磁盘。
最后就是 MySQL 中的一些服务上层应用的日志。
MySQL 计算和存储是一体的,所以不适合做集群、分布式分布式的解决方案是将计算和存储进行分离,计算做成多个节点,存储进行分区、分节点 ,可以使用分布式的、支持 MySQL 协议的 TiDB 数据库
当客户端通过 TCP 与 MySQL 建立连接时,MySQL 需要处理不同客户端的连接。 主线程会监听客户端是否与 MySQL 建立连接,如果建立连接,就会调用 accept 接收连接,然后会为这条客户端连接分配一个线程去处理它的数据。
每一条连接中的数据都是串行执行的,每个 SQL 语句都是一个事务。
不是 reactor 网络模型网络处理流程:主线程接收连接,接收连接交由连接池处理。
主要处理方式:IO 多路复用 select + 阻塞的 IO。
On-Line Transaction Processing,联机事务处理,主要对数据库进行增删改。
OLTP 主要用来记录某类业务事件的发生。
数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功。
On-Line Analytical Processing,联机分析处理,主要对数据库进行查询。
当数据累积到一定的程度,需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取想要的信息,为公司做决策提供支持。
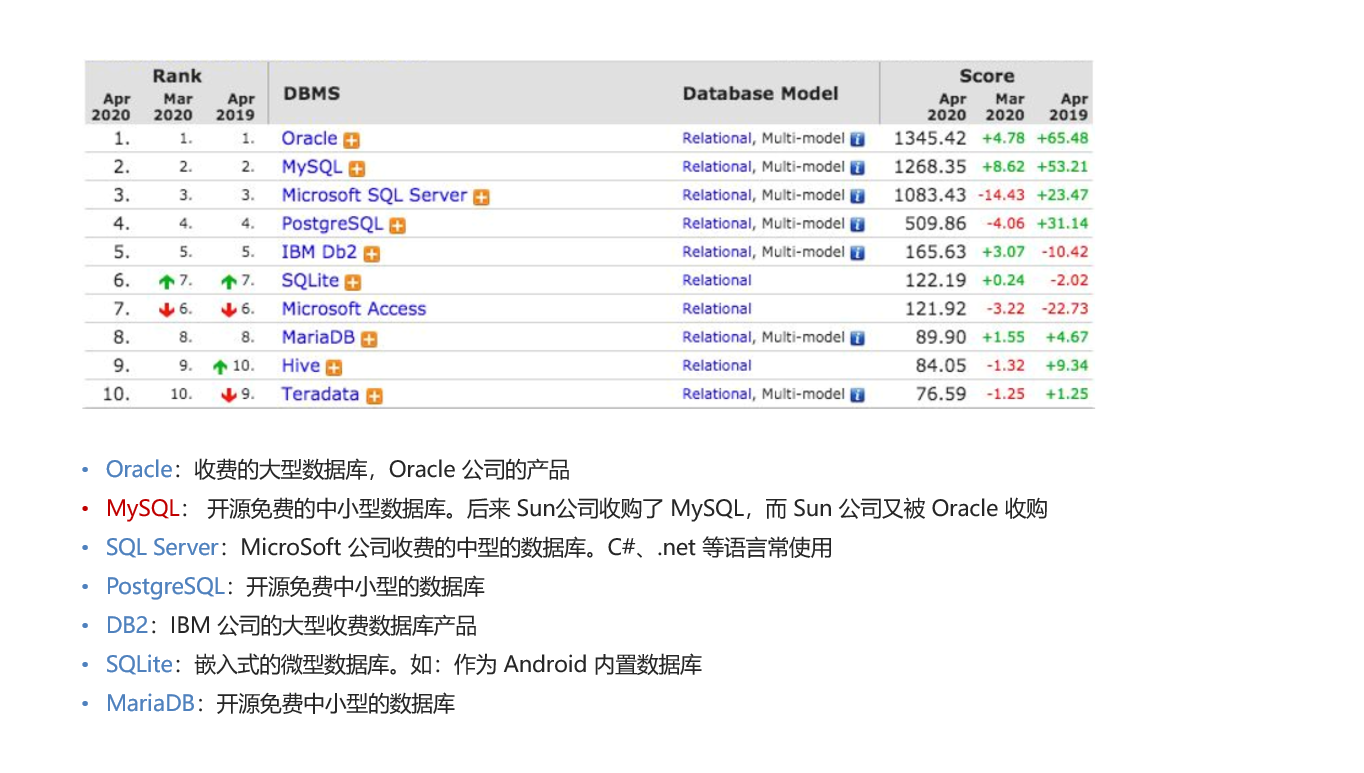
结构化查询语言(Structured Query Language)简称 SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系型数据库系统。
关系型数据库:MySQL、Oracle、SQL Server 等。
SQL 命令包括:DQL、DML、DDL、DCL 以及 TCL。
DQL
Data Query Language,数据查询语言。
select:从一个或者多个表中检索特定的记录。
DML
Data Manipulate Language:数据操作语言。
insert:插入记录。update:更新记录。delete:删除记录。
DDL
Data Define Language:数据定义语言。
create:创建一个新的表、表的视图、或者在数据库中的对象。alter:修改现有的数据库对象,例如修改表的字段。drop:删除表、数据库对象或者视图。truncate:删除表数据,保留表结构。
DCL
Data Control Language:数据控制语言。
grant:授予用户权限。revoke:收回用户权限。
TCL
Transaction Control Language:事务控制语言。
commit:事务提交。rollback:事务回滚。
连接器
查询缓存(mysql 5.7 有,mysql 8.0 已经删除):kv 存储,命中直接返回,否则继续执行
分析器:词法、句法分析生成语法树。
优化器:制定执行计划,选择查询成本最小的计划。
执行器:根据执行计划,从存储引擎获取数据,并返回给客户端。
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。
范式一(列不可分)
确保每列保持原子性,数据库表中的所有字段都是不可分解的原子值。
例如:表中有一个地址字段,如果需要访问地址字段中的城市属性,则需要将该字段拆分为多个字段:省份、城市、详细地址等。
范式二(依赖主键)
确保表中的每列都和主键相关,而不能只与主键的某一部分相关(组合索引)。
范式三(在范式二的基础上直接依赖)
确保每列都和主键直接相关,而不是间接相关,减少数据冗余。
反范式(允许冗余存储,为了提升查询效率)
范式可以避免数据冗余,减少数据库的空间,减小维护数据完整性的麻烦;但是采用数据库范式化设计,可能导致数据库业务涉及的表变多,并且造成更多的联表查询,将导致整个系统的性能降低,因此基于性能考虑,可能需要进行反范式设计。
CREATE DATABASE ` 数据库名` DEFAULT CHARACTER SET utf8;
DROP DATABASE ` 数据库名` ;
USE ` 数据库名` ;
创建表
5 大约束
not null:非空约束
auto_increment 自增约束
unique:唯一约束
primary:主键约束(非空 + 唯一)
foreign:外键约束
CREATE TABLE ` table_name` ( column_name column_type) ;
CREATE TABLE IF NOT EXISTS ` zcoder_test` (
` id` INT UNSIGNED AUTO_INCREMENT COMMENT '编号' ,
` course` VARCHAR ( 100 ) NOT NULL COMMENT '课程' ,
` teacher` VARCHAR ( 40 ) NOT NULL COMMENT '讲师' ,
` price` DECIMAL ( 8 , 2 ) NOT NULL COMMENT '价格' ,
PRIMARY KEY ( ` id` )
) ENGINE = innoDB DEFAULT CHARSET = utf8 COMMENT = '课程表' ;
删除表(DDL)
速度快。
删除整张表结构和表数据,包括索引、约束、触发器等。
不能回滚(会释放空间)。
DROP TABLE ` table_name` ;
清空数据表
truncate(DDL)
速度较快。
删除表数据,其它保留(auto_increment 置 1)。
不能回滚(会释放空间)。
以页为单位进行删除。
delete(DML)
速度慢。
删除部分或全部数据,其它保留(条件删除)。
可以回滚(是标记删除)。
逐行删除。
TRUNCATE TABLE ` table_name` ;
DELETE TABLE ` table_name` ;
INSERT INTO ` table_name` ( ` field1` , ` field2` , . . . , ` fieldn` ) VALUES ( value1, value2, . . . , valuen) ;
INSERT INTO ` zcoder_test` ( ` course` , ` teacher` , ` price` ) VALUES ( 'C++开发' , 'Zcoder' , 28000.0 ) ;
DELETE FROM ` table_name` [ WHERE Clause] ;
DELETE FROM ` zcoder_test` WHERE id = 1 ;
UPDATE table_name SET field1= new_value1, field2= new_value2 [ , fieldn= new_valuen]
UPDATE ` zcoder_test` SET ` teacher` = 'Zcoder' WHERE id = 1 ;
UPDATE ` zcoder_test` set ` age` = ` age` + 1 WHERE id = 1 ;
SELECT field1, field2, . . . fieldN FROM table_name [ WHERE Clause]
SELECT * FROM student;
SELECT ` sname` , ` class_id` FROM student;
SELECT ` sname` AS '姓名' , ` class_id` AS '班级ID' FROM student;
SELECT distinct ` class_id` FROM student;
SELECT * FROM ` student` WHERE ` name` = 'Zcoder' ;
SELECT * FROM ` student` WHERE ` gender` = "男" AND ` class_id` = 2 ;
SELECT * FROM ` student` WHERE ` class_id` BETWEEN 1 AND 3 ;
SELECT * FROM ` student` WHERE ` class_id` IS NOT NULL ;
SELECT * FROM ` student` WHERE ` class_id` IS NULL ;
SELECT * FROM ` student` WHERE ` gender` <> '' ;
SELECT * FROM ` student` WHERE ` gender` = '' ;
SELECT * FROM ` teacher` WHERE ` tname` LIKE '张%' ;
SELECT * FROM ` teacher` WHERE ` tname` LIKE '_晴%' ;
SELECT * FROM ` student` LIMIT 1 , 2 ;
SELECT * FROM ` score` ORDER BY ` num` ASC ;
SELECT * FROM ` score` ORDER BY ` course_id` DESC , ` num` DESC ;
SELECT sum ( ` num` ) FROM ` score` ;
SELECT avg ( ` num` ) FROM ` score` ;
SELECT max ( ` num` ) FROM ` score` ;
SELECT min ( ` num` ) FROM ` score` ;
SELECT count ( ` num` ) FROM ` score` ;
SELECT ` gender` , group_concat( ` age` ) as ages FROM ` student` GROUP BY ` gender` ;
SELECT ` gender` FROM ` student` GROUP BY ` gender` ;
SELECT ` gender` , count ( * ) as num FROM ` student` GROUP BY ` gender` ;
SELECT ` gender` , count ( * ) as num FROM ` student` GROUP BY ` gender` HAVING num > 6 ;
联表查询 INNER JOIN:只取两张表有对应关系的记录
SELECT cid FROM ` course` INNER JOIN ` teacher` ON course. teacher_id = teacher. tid;
联表查询 LEFT JOIN:在内连接的基础上保留左表没有对应关系的记录
SELECT course. cid FROM ` course` LEFT JOIN ` teacher` ON course. teacher_id = teacher. tid;
联表查询 RIGHT JOIN:在内连接的基础上保留右表没有对应关系的记录
SELECT course. cid FROM ` course` RIGHT JOIN ` teacher` ON course. teacher_id = teacher. tid
select * from course where teacher_id = ( select tid from teacher where tname = '小呆侯老师' )
多行子查询
多行子查询即返回多行记录的子查询
IN 关键字:运算符可以检测结果集中是否存在某个特定的值,如果检测成功就执行外部的查询。
EXISTS 关键字:内层查询语句不返回查询的记录。而是返回一
ALL 关键字:表示满足所有条件。使用 ALL 关键字时,只有满
ANY 关键字:允许创建一个表达式,对子查询的返回值列表,
在 FROM 子句中使用子查询:子查询出现在 from 子句中,这
select * from student where class_id in ( select cid from course where teacher_id = 2 ) ;
select * from student where exists ( select cid from course where cid = 5 ) ;
SELECT student_id, sname FROM
( SELECT * FROM score WHERE course_id = 1 OR
course_id = 2 ) AS A
LEFT JOIN student ON A. student_id =
student. sid;
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。其内容由查询定义。
基表:用来创建视图的表叫做基表。
通过视图,可以展现基表的部分数据。
视图数据来自定义视图的查询中使用的表,使用视图动态生成。
优点:
简单:使用视图的用户完全不需要关心后面对应的表的结构、
安全:使用视图的用户只能访问他们被允许查询的结果集。
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用
CREATE VIEW < 视图名> AS < SELECT 语句>
作用:
可复用,减少重复语句书写;类似程序中函数的作用。
逻辑更清晰,屏蔽查询细节,只关注数据返回。
权限控制,某些表对用户屏蔽,但是可以给该用户通过视图来对该表操作。
重构利器
假如因为某种需求,需要将 user 拆成表 usera 和表 userb;
如果应用程序使用 sql 语句:select * from user 那就会提示该表不存在;
若此时创建视图 create view user as select a. name, a. age, b. sex from usera as a, userb as b where a. name= b. name;
则只需要更改数据库结构,而不需要更改应用程序;