文本到图像生成在扩散模型的出现下取得了显著进展。然而,基于文本生成街景图像仍然是一项困难的任务,主要是因为街景的道路拓扑复杂,交通状况多样,天气情况各异,这使得传统的文本到图像模型难以处理。为了解决这些挑战,今天给大家分享一个新颖的可控文本到图像框架,名为Text2Street。在该框架中,首先引入了基于车道的道路拓扑生成器,通过计数适配器实现文本到地图的生成,具有准确的道路结构和车道线,实现可控道路拓扑生成。然后,提出了基于位置的目标布局生成器,通过目标级边界框扩散策略获得文本到布局的生成,实现可控交通目标布局生成。最后,设计了多控制图像生成器,将道路拓扑、目标布局和天气描述集成在一起,实现可控街景图像生成。大量实验表明,所提出的方法实现了可控的街景文本到图像生成,并验证了Text2Street框架在街景中的有效性。
介绍
文本到图像生成,作为计算机视觉的一个重要任务,旨在仅基于文本描述生成连贯的图像。近年来,针对常见场景(如人物和目标)的文本到图像生成已经付出了很多努力。特别是随着扩散模型的出现,取得了显著进展。然而,在专业领域生成图像同样具有重要价值,包括自动驾驶、医学图像分析、机器人感知等。对于街景的文本到图像生成在自动驾驶感知和地图构建的数据生成方面具有特殊重要性,但目前仍相对未被充分探索。
街景文本到图像生成作为一个尚未充分开发的任务,面临着几个严峻的挑战,可以分为三个主要方面。首先,生成符合交通规则的道路拓扑结构是一个挑战。一方面,如下图1(a)所示,从文本-图像对中学习道路结构受限于图像中不完整的道路结构信息,这是由于有限的成像角度和频繁的遮挡所导致的。这种复杂性使得在nuScenes数据集上微调的稳定扩散模型难以生成预期的图像。另一方面,如下图1(b)所示,生成符合交通规则且与文本中指定的车道线数量相匹配的车道线也是一个极具挑战性的任务。第二,交通状态的表示是街景图像中的一个关键元素,通常通过存在的交通目标数量来实现。然而,使用当前模型生成指定数量的交通目标并遵循运动规则经常无法达到预期。如下图1(c)所示,现有方法往往缺乏对精确数字要求的敏感性。例如,尽管我们的目标是生成一个有两辆车的道路场景,但稳定扩散模型的实际输出往往包括数量明显更多的车辆。最后,天气条件通常取决于场景内容,基于这些条件直接生成图像往往会产生模糊或次优结果,如下图1(d)所示。由于存在这三个挑战,街景文本到图像生成是计算机视觉中一项具有挑战性的任务。

为了解决前面提到的挑战,本文提出了一种新颖的用于街景的可控文本到图像框架,称为Text2Street,如图2所示。
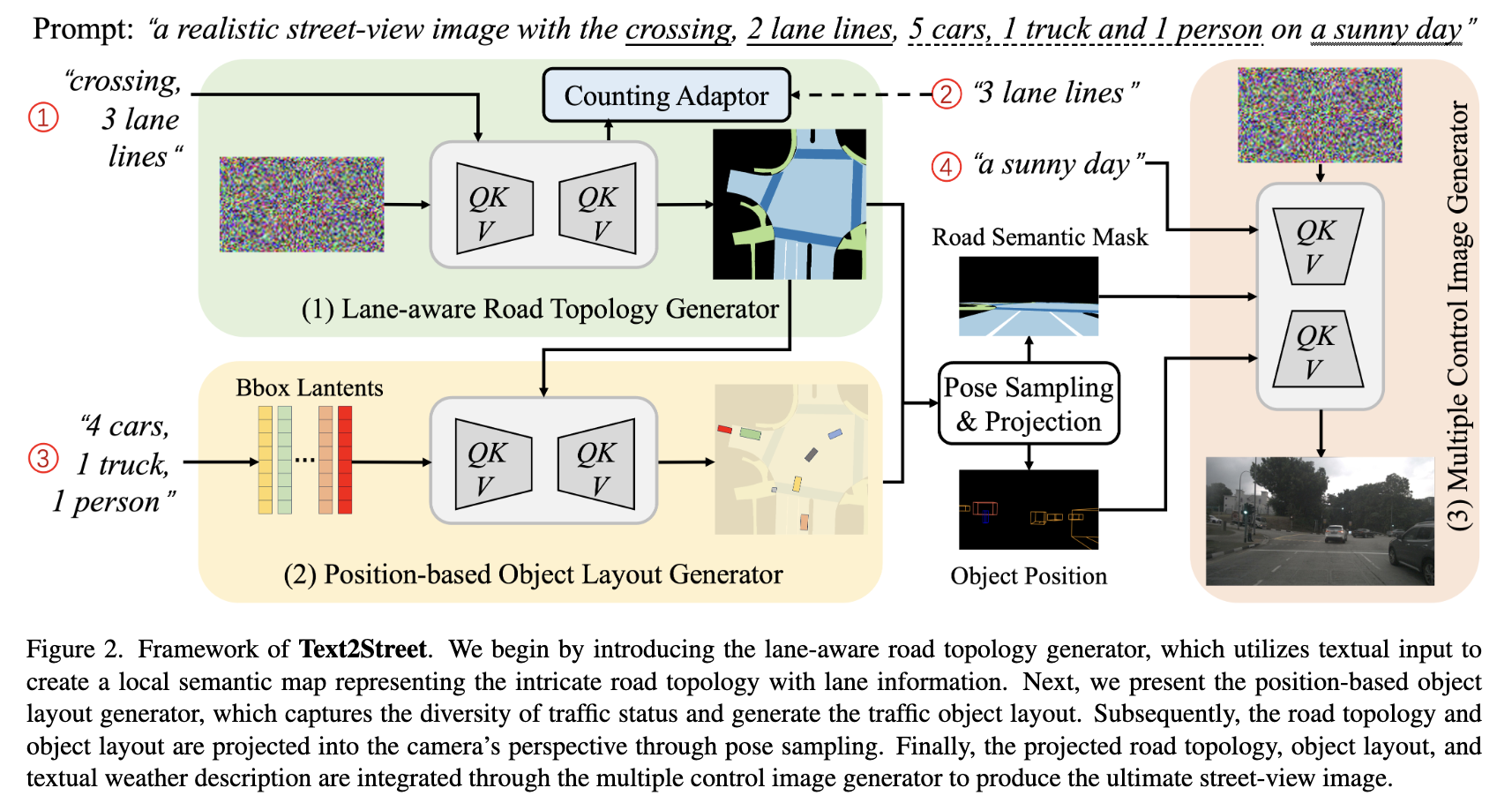
在这个框架内,首先引入了基于车道的道路拓扑生成器,利用文本描述创建表示复杂道路拓扑的局部语义地图。该生成器还通过计数适配器在语义地图内生成符合指定数量和交通规则的车道线。随后引入了基于位置的目标布局生成器,以捕获多样化的交通状态。通过采用目标级边界框扩散策略,它根据文本描述生成符合指定数量和交通规则的交通目标布局。最后,通过姿态采样,将道路拓扑和目标布局投影到相机的成像视角中。通过多控制图像生成器将投影的道路拓扑、目标布局和文本天气描述集成在一起,生成最终的街景图像。实验验证证实了我们提出的方法从文本输入生成街景图像的有效性。
本文的主要贡献如下:
提出了一种新颖的用于街景的可控文本到图像框架,仅基于文本描述实现了对道路拓扑、交通状态和天气条件的控制。
引入了基于车道的道路拓扑生成器,能够生成特定的道路结构以及车道拓扑。
提出了基于位置的目标布局生成器,能够生成符合交通规则的特定数量的交通目标。
提出了多控制图像生成器,能够整合道路拓扑、交通状态和天气条件,实现多条件图像生成。
相关工作
文本到图像生成
近年来,许多方法致力于处理通用的文本到图像生成任务。例如,AlignDRAW 在画布上迭代地绘制斑点,同时关注描述中的相关词语。GAWWN 根据生成对抗网络的指导,根据描述中的指令合成图像,描述了在哪个位置绘制什么内容。DALLE 描述了一种简单的方法来完成这个文本到图像任务,基于一个Transformer,该Transformer自回归地对文本和图像 tokens建模,形成单一的数据流。DALLE2提出了一个两阶段模型:一个先验模型根据文本标题生成一个 CLIP 图像embedding,一个解码器根据图像embedding生成图像。DDPM提出了使用扩散模型进行高质量图像合成的结果,扩散模型是一类受到非平衡热力学考虑的潜变量模型。Stable Diffusion将扩散模型应用于预训练自编码器的潜空间中进行训练,并通过在模型架构中引入交叉注意力层,将扩散模型转化为强大而灵活的生成器,用于一般的条件输入。这些方法在通用的文本到图像生成任务中取得了显著的结果。然而,在街景文本到图像任务中,它们的效果并不值得称赞。
街景图像生成
最近,在街景图像生成方法的研究中出现了一波热潮。例如,SDM 分别处理语义布局和嘈杂图像。它将嘈杂图像馈送给 U-Net 结构的编码器,同时将语义布局馈送给解码器,采用多层空间自适应归一化操作符。BEVGen 合成一组与交通场景的鸟瞰布局相匹配的逼真且空间一致的周围图像。BEVGen 结合了一种新颖的跨视角转换与空间注意力设计,学习相机与地图视图之间的关系,以确保它们的一致性。GeoDiffusion 将各种几何条件转换为文本提示,并为预训练的文本到图像扩散模型提供支持,用于高质量的检测数据生成,并能够对边界框以及自动驾驶场景中的额外几何条件(如相机视图)进行编码。BEVControl 提出了一种两阶段生成方法,可以生成准确的前景和背景内容。这些方法通常需要BEV地图、目标边界框或语义mask的输入来生成图像。然而,几乎没有研究仅依赖文本生成街景图像。在本文中,主要关注解决街景文本到图像生成的问题。
提出的方法
为了解决街景文本到图像生成中的这些挑战(即复杂的道路拓扑结构、多样化的交通状况和各种天气条件),引入了Text2Street,这是一个新颖的可控框架,如前面图2所示。
概述
Text2Street 接受街景描述提示(例如,“一个有路口、3条车道、4辆汽车和1辆卡车在晴天行驶的街景图像”)作为输入,并生成相应的街景图像。在主要流程之前,输入提示通过一个大语言模型(例如,GPT-4)进行解析,以提取道路拓扑、交通状况和天气条件的描述,然后将其输入三个主要组件。
第一个组件是基于车道的道路拓扑生成器,它将道路拓扑描述(“路口、3条车道”)作为输入,并生成局部语义地图。第二个组件是基于位置的目标布局生成器,它将交通状况中的交通目标描述(“4辆汽车和1辆卡车”)作为输入,并生成交通目标的布局。第三个组件是多控制图像生成器,它将道路拓扑、目标布局和天气条件描述(“晴天”)作为输入,并输出与原始街景描述提示相匹配的图像。
基于车道的道路拓扑生成器
对于稳定扩散模型,直接生成符合道路拓扑的图像,包括道路结构和车道拓扑,是困难的。为了解决这个问题,这里引入了基于车道的道路拓扑生成器(LRTG),如下图3所示。
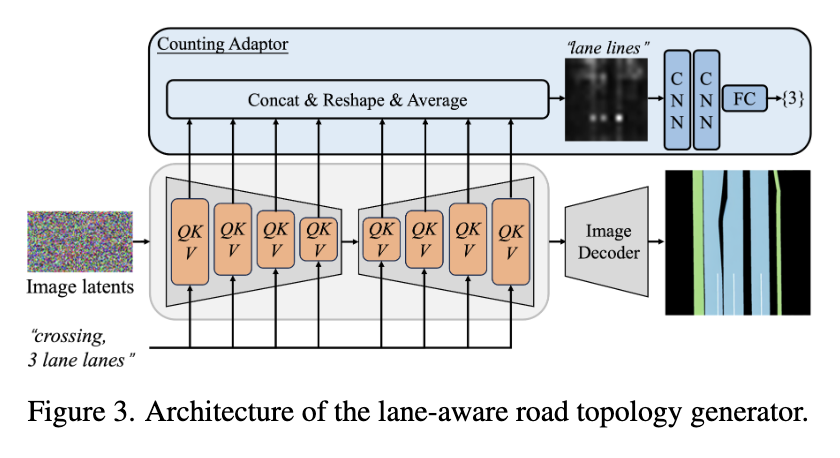
这个生成器并不直接产生道路图像;相反,它首先创建一个描述道路结构的局部语义地图,代表了一个完整的区域级道路结构,包括可行驶区域、交叉口、人行道、斑马线等。同时,为了确保生成的车道线符合交通规则(即等距和平行车道),在语义地图上对车道线进行特征化和生成,这比直接在透视视图图像上生成车道线更容易和更可控。此外,为了确保车道线的数量与提供的文本一致,还引入了一个计数适配器,以精确生成指定数量的车道线。在LRTG中,仅生成语义地图,这作为街景图像的一个重要中间步骤,稍后进一步详细介绍。
在生成局部语义地图时,利用稳定扩散模型根据CLIP文本编码器对道路拓扑描述进行编码。随后,编码输入被馈送到U-Net的交叉注意力层中以去噪图像潜变量,最终输出相应的语义地图。与稳定扩散模型一致,学习目标如下:
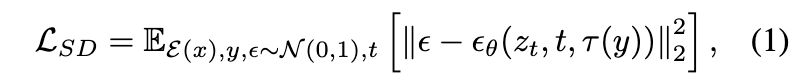
其中, x ∈ 是从标记的语义地图中裁剪出来的,在 RGB 空间中。E(·) 是预训练自编码器的编码器,z = E(x) 表示编码图像的潜变量, 来自于时间步 t 的正向扩散过程,y 是文本提示,τ(·) 表示预训练的 CLIP 文本编码器,术语 ϵ 表示目标噪声,而 (·) 表示用于预测噪声的时间条件 U-Net。这种方式确保了在语义地图中生成道路结构和车道线形状的合理性。
为了精确控制车道线的数量,计数适配器 收集了 U-Net 所有交叉注意力层的注意力分数。然后,这些分数被重塑以匹配相同的分辨率,然后平均以产生所有 tokens的注意力特征。从这些注意力特征中,选择与 tokens“车道线”相对应的特征 。这些选定的特征经过两个卷积层(卷积核为 3×3)和一个全连接层的进一步处理,用于预测车道线的数量 。
实现精确控制车道线数量的学习目标如下:

根据公式1和2,可以联合优化LRTG以生成局部语义地图,包括所需的道路结构和车道线。
基于位置的目标布局生成器
为了确保生成的图像能够描绘多样化的交通状况,利用大语言模型将交通状态转换为交通目标的数量(例如,汽车、卡车、行人等)。然后,提出了基于位置的目标布局生成器(POLG),根据目标数量的文本描述创建目标布局,如下图4所示。

为了确保生成指定数量的目标,采用了目标级别的边界框扩散策略来生成目标边界框的位置。同时,为了确保生成的交通目标符合交通规则,将LRTG中的局部语义地图纳入到边界框扩散过程中。通过POLG,生成交通目标的布局信息,这也作为生成最终街景图像的中间步骤。
在边界框扩散策略中,首先将交通目标表示为位置向量 ,其中 表示目标位置的坐标, 表示目标的尺寸, 表示目标的偏航角, 表示目标的类别。随后,根据扩散模型 DDPM对位置向量进行扩散。此外,为了确保目标遵守交通规则(例如汽车必须在道路上行驶而不能逆行),使用 ControlNet,将来自 LRTG 的局部语义地图作为 POLG 的控制因素。最终,学习目标如下:

其中,o 表示目标的位置向量, 来自于时间步 t 的正向扩散过程,m 表示局部语义地图,C(·) 表示 ControlNet。其他符号与公式1中的符号一致。根据公式3,可以通过基于文本描述的 POLG 优化和生成符合交通状况的交通目标的布局信息。
多重控制图像生成器
为了生成与道路拓扑和交通状况相符合的具有真实天气的图像,引入了多重控制图像生成器(MCIG),如下图5所示。

在这两个信息进入MCIG之前,进行了相机姿态采样和图像投影,以有效利用先前生成的局部语义地图和交通目标布局。这导致了透视视图下的2D道路语义mask 和交通目标布局地图 ,如前面图2所示。2D交通目标布局图也被表示为2D交通目标位置向量 。投影使用基于内在和外在转换的传统方法,其中内参使用固定的相机参数,外参在先前相机高度附近进行采样。
如图5所示,MCIG包括五个模块:目标级别位置编码器、文本编码器、语义mask控制网络、目标布局控制网络和朴素稳定扩散。前四个模块根据四种不同类型的信息控制图像生成,即2D交通位置向量、描述天气的文本、2D道路语义mask和2D交通目标布局图。
目标级别位置编码器对2D交通目标位置向量进行编码,包括2D边界框和目标类别,表示为:

边界框编码器将目标边界框映射到高维空间,确保网络可以学习更高频率的映射函数,并专注于每个目标的位置。具体而言,边界框编码器是基于正弦和余弦的编码函数。编码函数的数学形式如下:
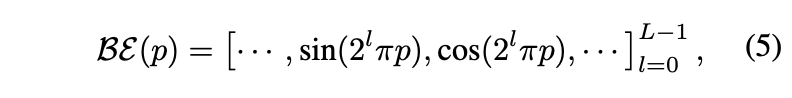
其中,BE(·) 应用于每个目标 Pi 的边界框的每个组件(即 ),并且 L 被经验性地设定为 10。同时,类别编码器 CE 利用 CLIP 文本编码器对目标类别(例如,“汽车”)进行编码。随后,边界框编码和类别编码在每个目标的特征embedding维度上进行串联。然后,通过一个两层全连接网络 (·) 将串联特征映射到与原始文本编码器embedding相同维度的特征中,作为位置embedding。基于 CLIP 文本编码器的文本编码器对天气描述文本 T 进行编码,生成文本embedding。
目标位置编码和天气文本embedding在标记维度上进行串联后,分别输入到稳定扩散的交叉注意力层中,控制图像生成过程中的目标位置和天气。同时,语义mask控制网络和目标布局控制网络采用两个类似的控制网络,利用图像(即语义mask和布局地图)作为输入,在街景图像生成过程中控制道路拓扑和目标布局。MCIG 的学习目标函数如下:
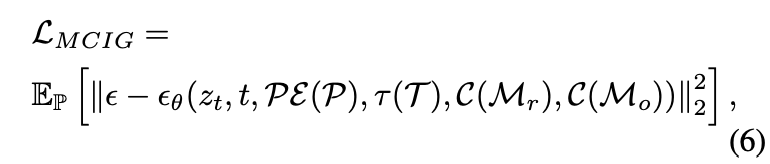
为了方便表述,P 是 {} 的集合。 通过使用公式6对 MCIG 进行优化,获得符合关于道路拓扑、交通状态和天气条件的初始提示的街景图像。
实验和结果
实验设置
数据集。 为了验证所提出方法的性能,在公共自动驾驶数据集 nuScenes 上进行所有实验。nuScenes 数据集包含 1,000 个街景场景(分别用于训练/验证/测试的数量为 700/150/150)。每个场景大约包含 40 帧,每帧包括由安装在自动驾驶车辆上用于全景视图的六个摄像头拍摄的六个 RGB 图像。此外,每帧都带有一个包含 32 种语义类别的标注语义地图。为了简单起见,在所有实验中仅使用由前置摄像头拍摄的图像。
评估指标。为了全面评估街景图像的文本到图像生成,从图像级别和属性级别对生成结果进行评估。
在图像级别评估中,使用Frechet Inception Distance (FID) SFID来衡量图像的保真度,以及CLIP分数SCLIP来衡量图像与文本的对齐性。
在属性级别评估中,主要衡量文本到图像街景生成在四个方面的准确性:道路结构、车道线计数、交通目标计数和天气状况。对于这四个指标,在nuScenes数据集上训练了四个神经网络来评估生成图像的分数。具体来说,基于ResNet-50的两类分类器用于道路结构准确性Sroad的训练,以区分街景RGB图像中的道路结构是“交叉口”还是“非交叉口”。对于车道线计数准确性Slane,类似地,在ResNet-50上训练了一个六类分类器,以区分街景RGB图像中车道线的数量是否等于0、1、2、3、4或≥ 5。对于交通目标计数准确性,基于YOLOv5的目标检测器被训练用于评估街景RGB图像中交通目标的数量。对于天气状况准确性,还在ResNet-50上训练了一个四类分类器,以区分街景RGB图像中的天气状况是晴天、晴夜、雨天还是雨夜。所有模型均在nuScenes训练数据集上进行训练,并用作街景图像生成的属性级别评估的评估指标。
训练和推断。在训练阶段,分别训练了三个生成器,即车道感知道路拓扑生成器(LRTG)、基于位置的目标布局生成器(POLG)和多重控制图像生成器(MCIG)。LRTG和MCIG使用Stable Diffusion进行初始化,POLG基于带有ControlNet修改的DDPM进行随机初始化,并且CLIP 文本编码器采用预训练权重固定。对于这三个生成器,使用AdamW优化器进行10个epochs的训练,学习率为,batch size大小为32。此外,LRTG中的语义地图被调整为512×512的分辨率,MCIG中的RGB图像被调整为895×512的分辨率。在推断阶段,这三个生成器按顺序进行推断,去噪迭代次数都设置为30次。
与最先进方法的比较
将我们的方法与几种最先进的文本到图像生成算法进行比较,包括Stable Diffusion、Stable Diffusion 2.1和Attend-and-Excite在nuScenes验证数据集上的表现,如下表1所列。这些方法都是在nuScenes训练数据集上进行微调的。请注意,我们还将在nuScenes验证数据集上的性能列为“参考”。
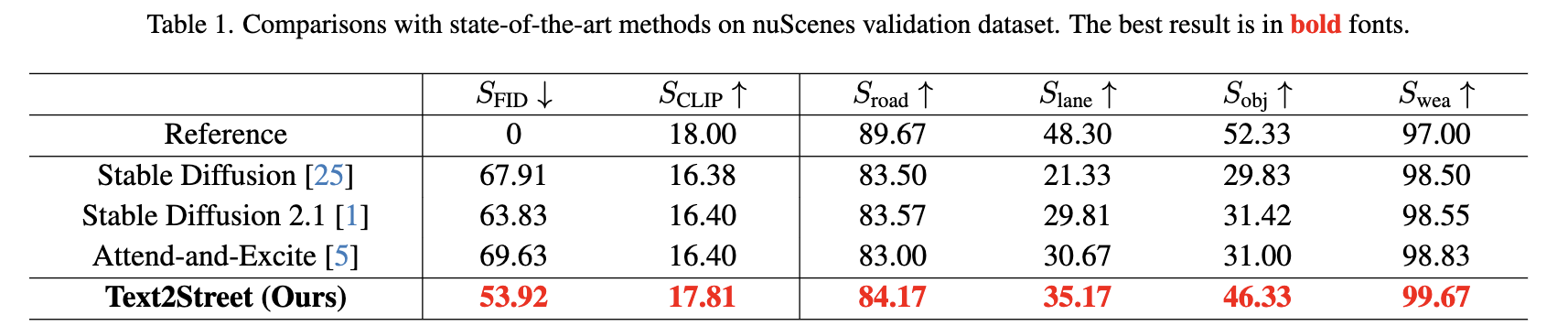
将我们的方法与最先进方法进行比较,可以看到,我们的方法在表1中几乎所有指标上都表现出色。特别是,我们的方法在属性级别指标(即)上表现最佳,表现出了对于细粒度的文本到图像街景图生成的优越可控性。具体而言,相对于第二表现最好的方法,我们的方法在指标上分别表现出了明显的4.50%和14.91%的改进。此外,我们的方法在图像级别指标(即)上也表现更好,反映了其整体生成质量和图像-文本一致性的优越性。总的来说,这些观察结果验证了我们提出的方法在街景图像可控生成方面的有效性。
我们的方法生成的视觉示例如下图6所示。从下图6可以明显看出,与其他方法相比,我们的方法在处理不同道路结构(第1和第4行)、不同车道线数量(第1和第3行)、不同数量的交通目标(第1和第2行)以及不同天气条件(第2和第3行)时都能产生更好的结果。这表明我们的方法可以有效地仅基于文本生成街景图像,并暗示了其在街景文本到图像生成中的可控性和优越性。

消融分析
为了评估各个组件的有效性,在nuScenes验证数据集上进行了消融实验,比较了提出方法内部性能的变化。
首先,为了验证车道感知道路拓扑生成器(LRTG)的有效性,引入了三个模型进行消融比较。第一个模型,称为“基线”,是一个仅带有文本编码器的简单多重控制图像生成器(MCIG),实际上是一个 Stable Diffusion 模型。第二个模型,称为“”,是在“基线”的基础上增加了不包括车道线控制的 LRTG。第三个模型,“A2”,在第一个模型的基础上添加了具有车道线控制的 LRTG。这三个模型的比较如下表2的前三行所示。可以观察到,引入道路结构控制(“A1”)显著提高了指标,而同时引入道路结构和车道线(“”)进一步提升了指标。这证实了LRTG在控制道路拓扑方面的有效性。
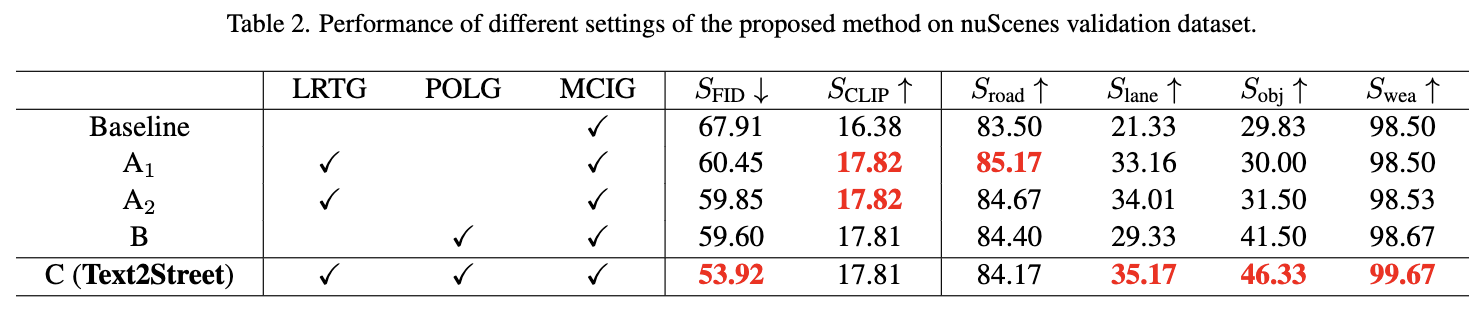
第二,为了验证基于位置的目标布局生成器(POLG)的有效性,将POLG添加到“基线”中,称为“B”。比较前面表2的第一行和第四行,显然,包含POLG显著提高了指标,证明了POLG在交通目标生成中的控制能力。
第三,为了验证不同模块的兼容性,我们还列出了模型“C”(即Text2Street),该模型结合了所有三个模块。从前面表2的最后一行可以看出,“C”在所有指标上都取得了最佳性能,确认了不同模块之间的兼容性。
目标检测的文本到图像生成
为了展示街景文本到图像生成对下游任务的实用性,选择目标检测作为代表性任务。使用提出的Text2Street基于随机提示生成30,000张图像,作为原始训练数据的补充,以在nuScenes数据集上训练YOLOv5,如表3所示。结果表明,我们方法生成的图像对于下游街景任务是有益的,突显了街景文本到图像生成的潜力。

图像编辑
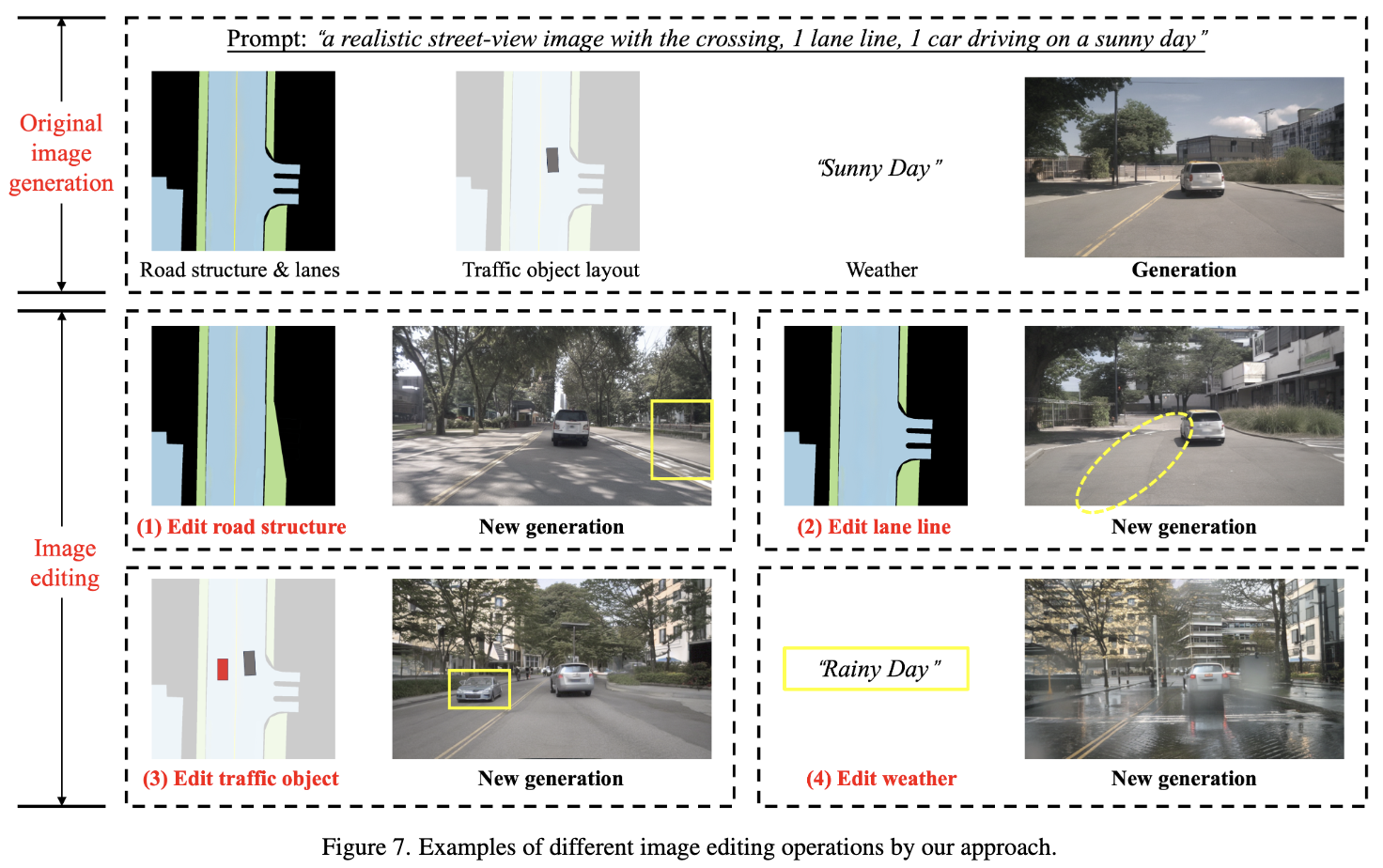
除了街景文本到图像生成外,本文方法还允许对局部语义地图、目标布局或文本进行修改,从而在最初生成的RGB图像中编辑道路结构、车道线、目标布局和天气条件,如下图7所示。
结论
本文提出了一种新颖的用于街景的可控文本到图像生成框架。这个框架设计了车道感知道路拓扑生成器,以文本到地图的方式对道路拓扑施加控制。此外,提出了基于位置的目标布局生成器,通过文本到布局的方式控制交通目标的布局。此外,多重控制图像生成器被构建起来,以整合多重控制来生成街景图像。实验结果证实了所提出方法的有效性。
参考链接
[1] Text2Street: Controllable Text-to-image Generation for Street Views
地址:https://arxiv.org/pdf/2402.04504
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术