查找
查找的基本概念
查找表 (search table) :由同一类型的数据元素 ( 或记录 ) 构成的集合。由于“集合”中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的数据结构,可以是线性表、树、图。关键字 (key) :数据元素 ( 或记录 ) 中某个数据项的值,用它可以标识 ( 识别 ) 一个数据元素( 或记录 ) 。如果一个关键字可以唯一地标识一个数据元素,则称其为主关键字;否则为次关键字。当数据元素仅有一个数据项,数据元素的值就是关键字。查找 (searching) :根据给定的某个值,在查找表中确定一个其关键字等于给定值的记录或数据元素。若表中存在这样的一个记录,则称查找是成功的,此时查找的结果可给出整个记录信息,或给出该记录在查找表中的位置;若表中不存在这样一个记录,则称查找是失败的,此时查找结果可给出一个“空”记录或“空”指针。平均查找长度 (average search length) :为确定记录在查找表中的位置,需和给定值进行比较的关键字次数的期望值称为查找算法在查找成功时的平均查找长度。对于长度为 n 的查找表,查找成功时的平均查找长度
查找的基本方法
线性表
#define MAXSIZE 20
typedef int KeyType;
typedef struct
{
KeyType r[MAXSIZE + 1];
int length;
}SqList;
void Init(SqList& L)
{
int i;
for (i = 0;i <= 20;i++)
L.r[i] = 0;
L.length = 0;
}
void Input(SqList& L)
{
int x;
while (cin >> x)
{
L.r[++L.length] = x;
if (cin.get() == '\n')
break;
}
}顺序查找
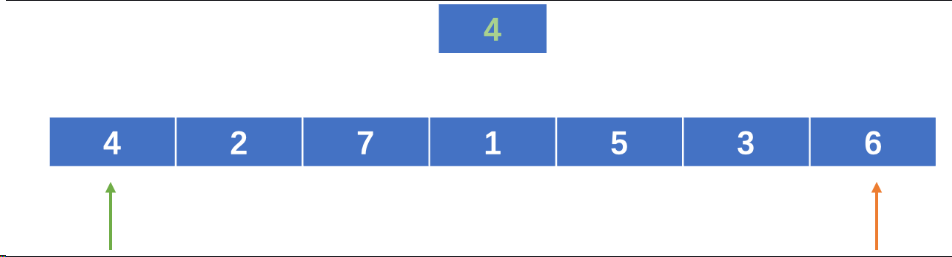
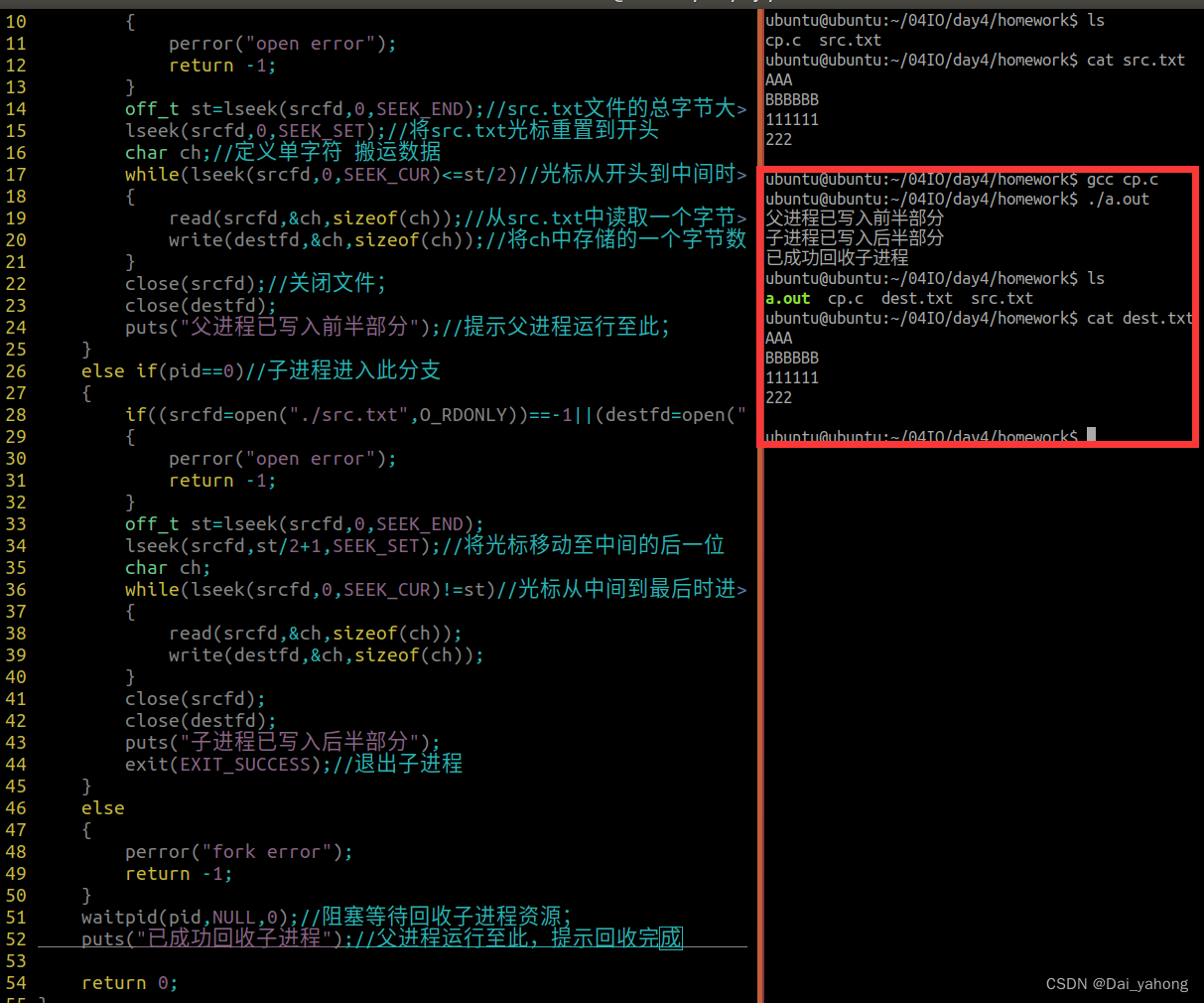
算法思想:在表的一端设置一个称为“监视哨”的附加单元,存放要查找元素的关键字。从表的另端开始查找,如果未在“监视哨”找到要查找元素的关键字,返回失败信息,否则返回相应下标。
int SeqSearch(RecordList l,KeyType k)
//在顺序表|中顺序查找其关键字等于k的元素,若找到,则函数值为该元素在表中的位置,否则为 0
{
l.r[0].key=k; i=l.length;
while (l.r[i].key!=k)
i--;
return(i);
}其中 1.r[0]为“监视哨”,可以起到防止越界的作用。
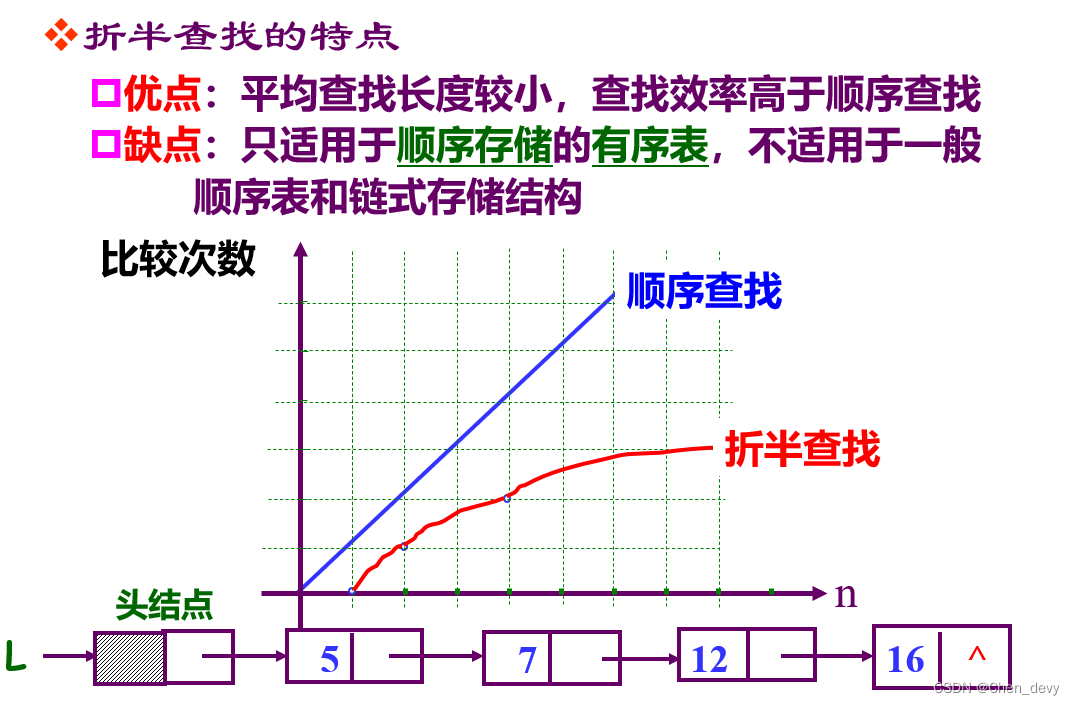
折半查找
折半查找法又称为二分查找法,这种方法对待查找的列表有两个要求:
(1)必须采用顺序存储结构;
(2)必须按关键字大小有序排列。
算法思想:首先,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
int BinSrch (RecordList lKeyType k)
//在有序表|中折半查找其关键字等于k的元素,若找到,则函数值为该元素在表中的位置
{
low=1; high=l.length;//置区间初值
while (low<=high)
{
mid=(low+high)/2;
if(k==l.r[mid].key)
return(mid);//找到待査元素
else if(k<l.r[mid].key)
high=mid-1;//未找到,则继续在前半区间进行査找
else
low=mid+1;//继续在后半区间进行査找
}
return (0);
}分块查找
插值查找
int main(void)
{
SqList L;
int key;
Init(L);
Input(L);
cin >> key;
Search(L, key);
return 0;
}
树表式
typedef struct node
{
KeyType key;
struct node *lchild, *rchild;
} BSTNode, *BSTree;二叉排序树
二叉排序树的插入和生成
已知一个关键字值为 key 的结点 s ,若将其插入到二叉排序树中,只要保证插入后仍符合二叉排序树的定义即可。插入过程可描述如下:
① 若二叉排序树是空树,则 key 成为二叉排序树的根。
② 若二叉排序树是非空树,则将 key 与二叉排序树的根进行比较,如果 key 等于根结点的值,则停止插入;如果 key 小于根结点的值,则将 key 插入左子树;如果 key 大于根结点的值,则将 key 插入右子树。
二叉排序树或者是一棵空树,或者是具有如下性质的二叉树:① 若它的左子树非空,则左子树上所有结点的值均小于根结点的值;② 若它的右子树非空,则右子树上所有结点的值均大于根结点的值;③ 它的左、右子树也分别是二叉排序树。
BSTree SearchBST(BSTree bt, KeyType key)
/*在根指针 bt 所指二叉排序树中,查找关键字等于 key 的元素,若查找成功,则返回指向该元
素的指针,否则返回空指针*/
{
if(!bt) return NULL;
else
if(bt->key==key) return bt; /*查找成功*/
else
if(key<bt->key)
return SearchBST(bt->lchild, key); /*在左子树查找*/
else
return SearchBST(bt->rchild, key); /*在右子树查找*/
}
由二叉排序树的定义可以得出一个重要性质:
中序遍历一棵二叉排序树时可以得到一个递增有序序列。
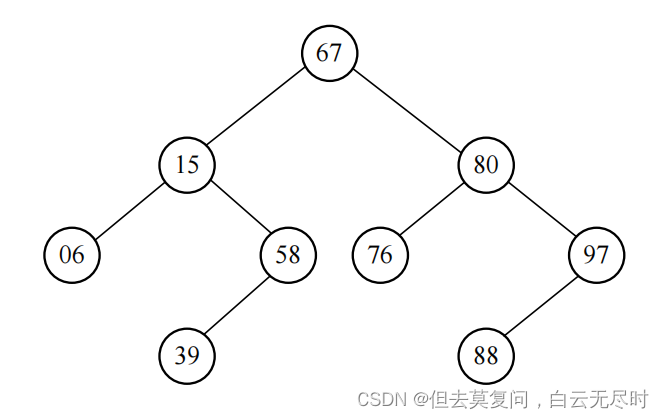
如对 进行中序遍历,可得到序列:06 , 15 , 39 , 58 , 67 , 76 , 80 , 88 , 97 。
哈希
//构造哈希表
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
void initHashTable(Node** hashTable, int m) {
for (int i = 0; i < m; i++) {
hashTable[i] = NULL;
}
}
void insert(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (*head == NULL) {
*head = newNode;
} else {
Node* temp = *head;
while (temp->next != NULL) {
temp = temp->next;
}
temp->next = newNode;
}
}
int hash(int key, int m) {
return key % m;
}
void printSynonyms(Node** hashTable, int n) {
Node* head = hashTable[n];
if (head == NULL) {
printf("-1");
} else {
Node* temp = head;
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
}
}
int main() {
int n;
int m;
int key;
int data;
Node* keywords = NULL;
while (scanf("%d", &key) != EOF) {
insert(&keywords, key);
if (getchar() == '\n') {
break;
}
}
// 输入哈希函数中的除数m
scanf("%d", &m);
// 输入散列地址n
scanf("%d", &n);
Node** hashTable = (Node**)malloc(m * sizeof(Node*));
initHashTable(hashTable, m);
Node* temp = keywords;
while (temp != NULL) {
int h = hash(temp->data, m);
insert(&hashTable[h], temp->data);
temp = temp->next;
}
// 输出散列地址n的同义词序列
printSynonyms(hashTable, n);
return 0;
}
排序
分类
根据在排序过程中涉及的存储器不同,可将排序方法分为两大类:内部排序、外部排序。内部排序:在排序进行的过程中不使用计算机外部存储器的排序过程。外部排序:在排序进行的过程中需要对外存进行访问的排序过程。
存储结构
(1) 向量结构:将待排序的记录存放在一组地址连续的存储单元中。由于在这种存储
方式中,记录之间的次序关系由其存储位置来决定,所以排序过程中一定要移动记录才行。
(2) 链表结构:采用链表结构时,记录之间逻辑上的相邻性是靠指针来维持的,这样
在排序时,就不用移动记录元素,而只需要修改指针。这种排序方式被称为链表排序。
(3) 记录向量与地址向量结合:将待排序记录存放在一组地址连续的存储单元中,同
时另设一个指示各个记录位置的地址向量。这样在排序过程中不移动记录本身,而修改地
址向量中记录的“地址”,排序结束后,再按照地址向量中的值调整记录的存储位置。这种
排序方式被称为地址排序。
简单排序方法
简单选择排序
我们假定排序结果是从小到大排列。简单选择排序的基本思想:首先,在待排序序列
中选择出最小的记录,然后将这个最小的数据元素与第一个记录交换,第一个记录到位,
这叫做第一趟排序;第二趟,就是从第二个记录到最后一个记录中选择最小的记录,之
后将最小的记录与第二个记录交换,第二个记录到位;以此类推,进行 n - 1 趟,序列就
有序了。
例如,对下列一组关键字:
(49 1 , 38 , 65 , 49 2 , 76 , 13 , 27 ,52) 进行简单选择排序 
void SelectSort(SqList *L)
{ /*对顺序表 L 作简单选择排序*/
RecordType temp;
for(i=1; i<L->length; ++i)
{ /*选择第 i 个小的记录,并交换到位*/
j=i; /* j 用于记录最小元素的位置*/
for(k=i+1; k<=L->length; k++) /*在 L.r[i..L.length]中选择 key 最小的记录*/
if(L->r[k].key<L->r[j].key)
j=k;
if(i!=j) /*第 i 个小的记录 L->r[j]与第 i 个记录交换*/
{
temp=L->r[j];
L->r[j]=L->r[i];
L->r[i]=temp;
}
}
}/*SelectSort直接插入排序
插入排序的基本思想是:在一个已排好序的记录子集的基础上,每一步将下一个待排
序的记录有序地插入到已排好序的记录子集中,直到将所有待排记录全部插入为止。 
void InsertSort(SqList *L)
{ /*对顺序表 L 作插入排序*/
for(i=2; i<=L->length; ++i)
if(L->r[i].key<L->r[i-1].key)
{ /*当“<”时,才需将 L->r[i]插入有序表*/
L->r[0]=L->r[i]; /*将待插入记录复制为哨兵*/
j=i-1;
while(L->r[0].key<L->r[j].key)
{
L->r[j+1]=L->r[j]; /*记录后移*/
j--;
}
L->r[j+1]=L->r[0]; /*插入到正确位置*/
}
} 希尔排序
希尔排序的基本思想:先将整个待排记录序列分割成为若干子序列,对每个子序列分别进行直接插入排序,待整个序列中记录“基本有序”时,再对全体记录进行一次直接插入排序。 
起泡排序。
先进排序方法
快速排序
1. 基本原理
快速排序最早是由图灵奖获得者 Tony.Hoare 于 1962 年提出的一种划分交换排序。它采用了一种分治的策略。该方法的基本思想是:
(1) 先从数列中取出一个数作为基准数(该记录称为枢轴)。
(2) 将比基准数大的数全放到它的右边,小于或等于基准数的全放到它的左边。
(3) 再对左右两部分重复第 (2) 步,直到各区间只有一个数,达到整个序列有序。
归并排序
1. 基本原理
归并排序 (merge sort) 是利用归并操作的一种排序方法。所谓归并,是指将两个或两个
以上的有序表合并成一个有序表,通过两两合并有序序列之后再合并,最终获得一个有序
序列。
堆排序
树形选择排序
树形选择排序也称做锦标赛排序,其基本思想是:先把待排序的 n 个记录的关键字两
两进行比较,取出较小的,然后再在 n / 2 个较小的记录中,采用同样的方法进行比较,选
出每两个中较小的,如此反复,直到选出最小关键字记录为止。可以用一棵有 n 个结点的
树来表示,选出的最小记录就是这棵树的根结点。在输出最小记录后,为再次选出次小记
录,将根结点即最小记录所对应的叶子结点的关键字的值置为∞,再进行上述的过程,直
到所有的记录全部输出为止。
堆排序
堆排序:对 n 个元素的序列进行堆排序,先将其建成堆,以根结点与第 n 个结点交换,
调整前 n - 1 个结点成为堆,再以根结点与第 n - 1 个结点交换;重复上述操作,直到整个序
列有序。