1. 索引基本概念
1.1 索引介绍
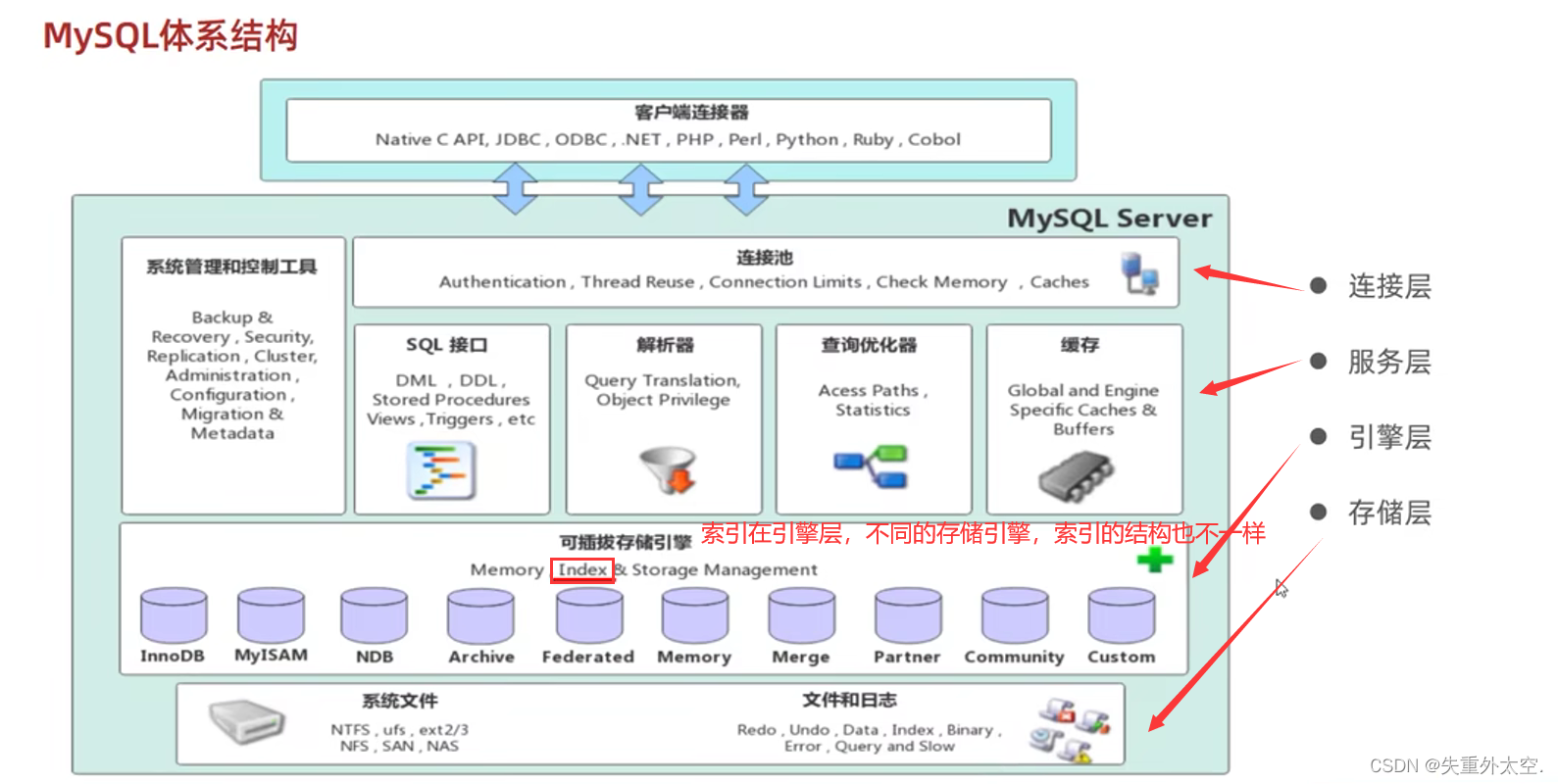
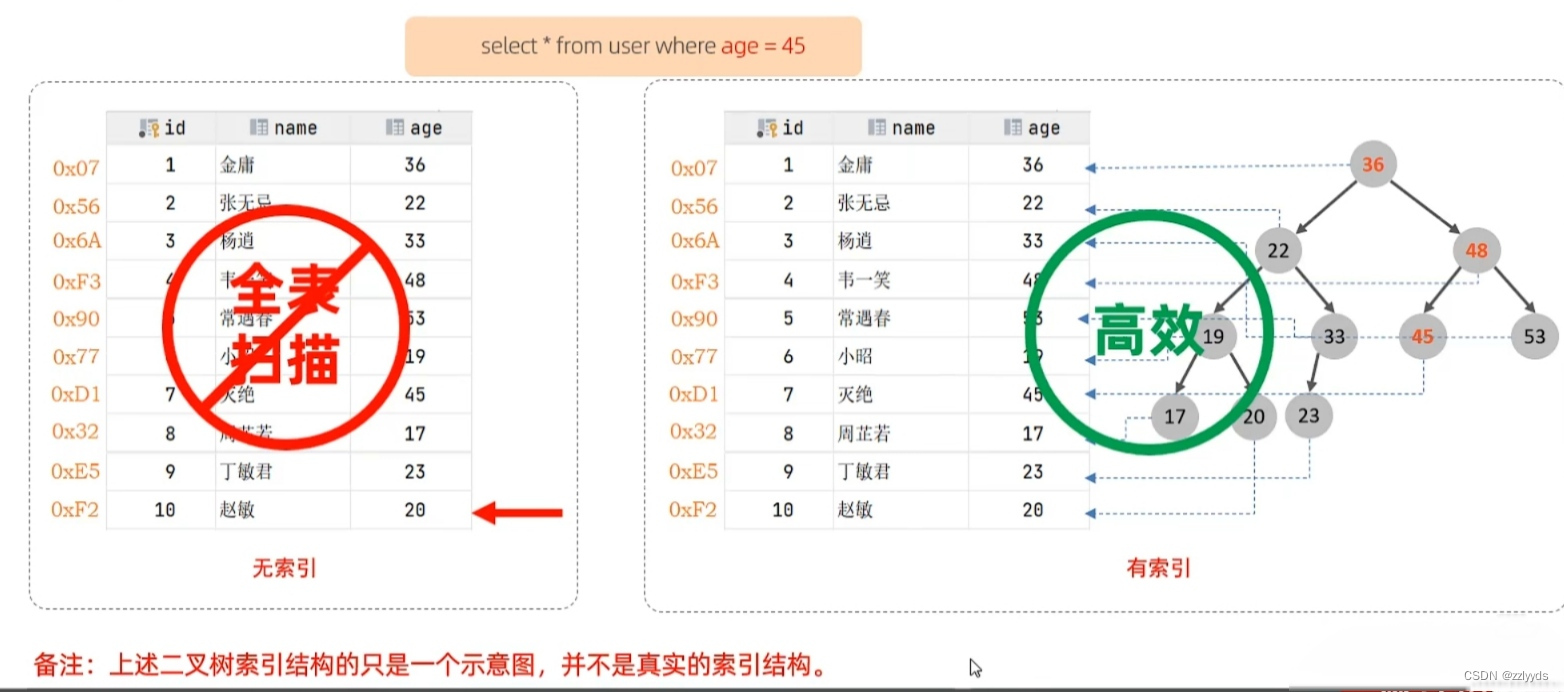
索引(index):是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或者多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。(具体细节在MySQL进阶章节详细讨论)
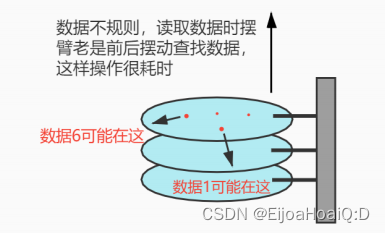
在数据库中,使用条件查询时需要遍历表,相当于O(N)的时间复杂度,但是数据库中的数据是存储在硬盘上的,而数据结构中的O(N)是基于内存的角度谈论的,所以硬盘I/O操作遍历操作更加缓慢!
而索引的目的就是提高 “查询效率” ,考虑有一本书,如何能够快速的找到某个章节的页码,这个时候就需要借助目录了 ,而索引的功能就类似于目录,能够提高查询效率。
索引特点:
- 索引能够加快查询效率
- 索引自身也是一定的数据结构组成,也要占据相应的存储空间
- 当我们进行新增、删除、修改操作时,不仅需要修改数据,同时也要对索引进行维护管理
总结:因此索引适用的场景需要具备如下两大条件:1、对于存储空间要求不高(存储空间充裕);2、应用场景以查询居多,增加、修改、删除等频率不高
1.2 索引相关SQL操作
1.2.1 查看索引
语法格式:show index from 表名;
create database blog_mysql_index;
create table t_user(username varchar(20) primary key,`password` varchar(20) not null);
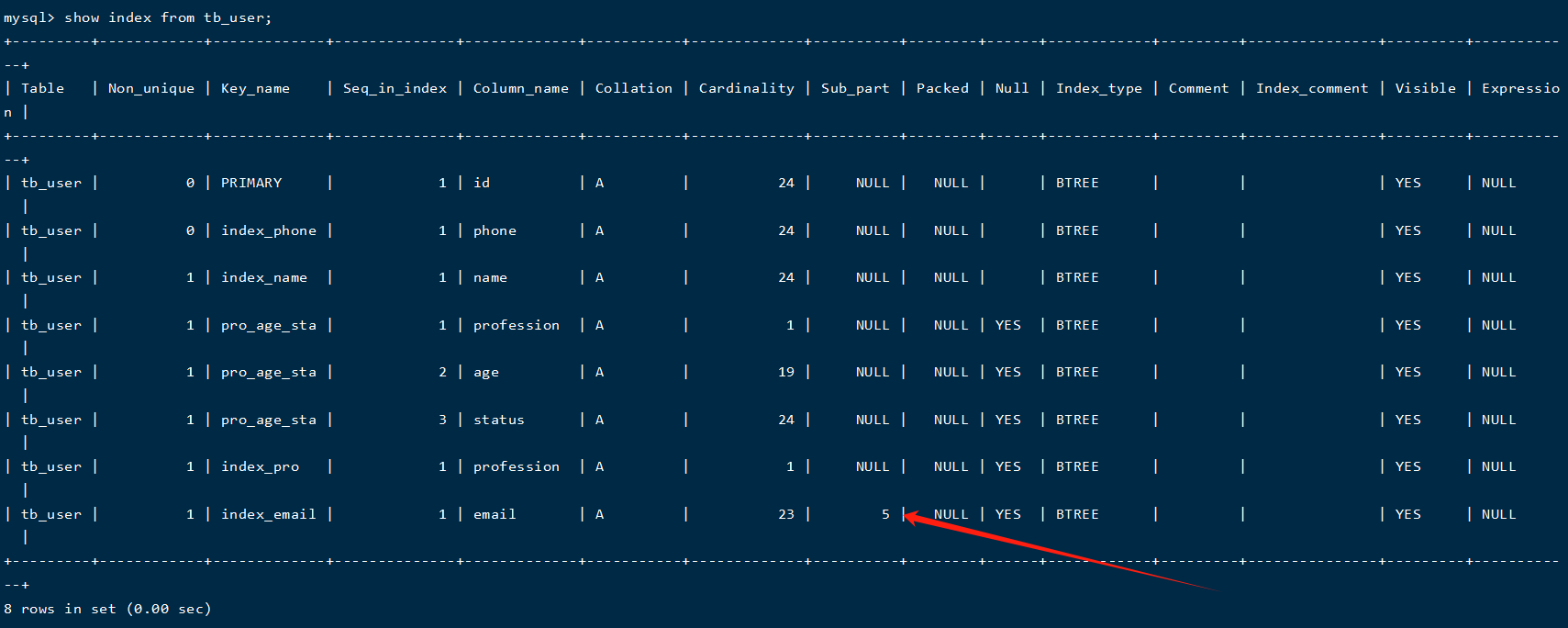
show index from t_user;
结果:

从中我们可以发现表中具有哪些索引,以及哪些列上加上了索引,并且我们可以发现某些约束例如 primary key、unique 等频繁用于查询操作,所以会自动加上一些索引
1.2.2 新增索引
语法格式:create index 索引名 on 表名(列名);
create index index_password on t_user(`password`);
show index from t_user;
结果:

从中我们可以发现列password也加上了索引。需要注意的是,创建索引这个操作是一个危险操作!如果表中数据量比较少不会产生问题,但是如果数据量非常庞大,这个时候添加索引就会导致数据结构重新组织,此时就会触发大量的硬盘I/O,数据库服务器很容易就宕机了!
1.2.3 删除索引
语法格式:drop index 索引名 on 表名;
drop index index_password on t_user;
show index from t_user;
结果:

同理,删除索引也是一个十分危险的操作!所以尽量在建表之初就确定好哪些字段需要加上索引,而不要等到生产环境上线数据量庞大之后再考虑索引的问题。
但是实际情况由于需求的不断变化,因此很难项目之初就确定好,所以事实上程序员可以通过"曲线救国"的方式处理索引问题,那就是使用新的机器部署数据库,然后建表建索引,逐步将原环境上的数据拷贝到新数据库中,最后用新的机器代替旧的机器就可以了!
2. 索引底层数据结构
我们需要关心索引底层数据结构的实现,但是我们此处也是简单介绍(详细内容在数据库进阶或者高阶数据结构部分介绍)
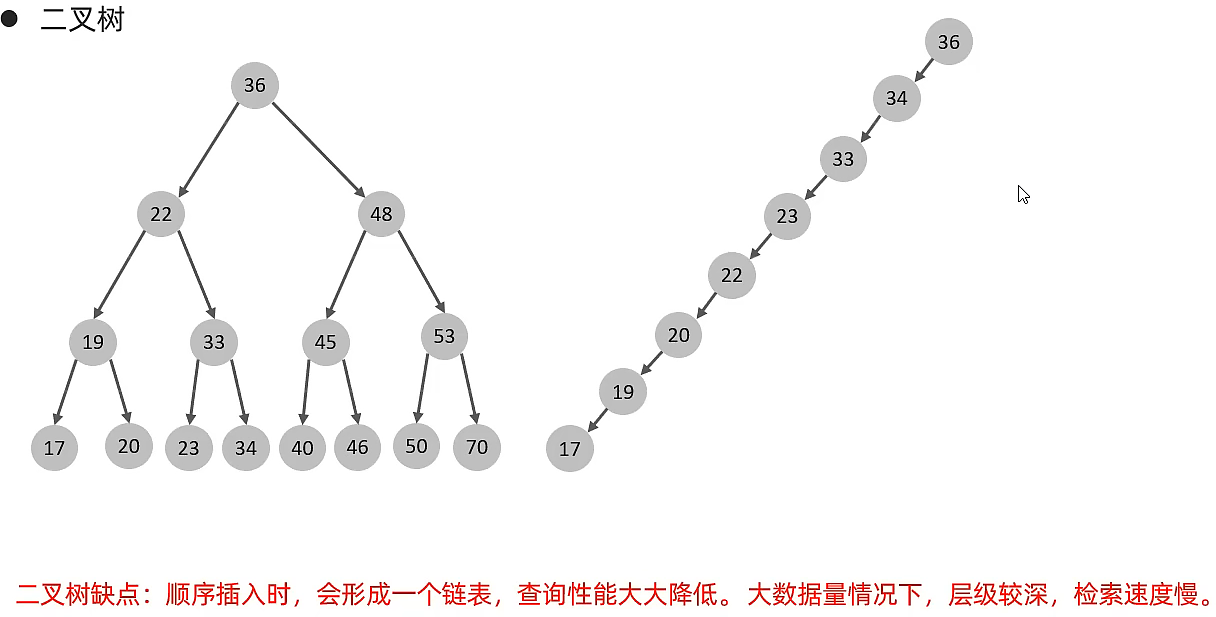
前面提到索引本身实际上就是通过额外的数据结构来对表中的数据进行重新组织,那么我们需要考虑使用什么样的数据结构才能在时间、空间上占据优势呢?回忆下我们之前学习的常见数据结构有顺序表、链表、栈、队列、二叉树、哈希表,其中顺序表、链表、栈、队列显然是不适合用于"查找"功能的!而哈希表通过一定时间扩容是可以实现平均时间复杂度为O(1)的,但是哈希表的原理是通过哈希函数计算得出存储下标进行查找,而数据库中很多操作并不是单纯比较相等,例如between and范围比较就无法使用哈希表!所以此处最适合的还是平衡二叉树这样的数据结构(时间复杂度为O(logN))
2.1 Java中的ArrayList与LinkedList的区别(常见面试题)
个人整理:
- 针对ArrayList来说,它的底层实现是数组,具有随机访问特性,随机访问的时间复杂度是O(1),ArrayList尾插/尾删较快(时间复杂度都是O(1)),而在头插/头删/中间节点插入/中间节点删除的平均时间复杂度是O(N)
- 针对LinkedList来说,它的底层实现是基于链表的,不支持随机访问,进行头插/头删/尾插/尾删的时间复杂度是O(1),中间节点插入/删除的时间复杂度是O(N)
- LinkedList相较于ArrayList的唯一优势就是可以支持头插头删,因此可以用来轻松实现队列这样的数据结构,除此以外,其他方面大多数都是ArrayList占据优势
常见错误说法:
使用LinkedList占用空间比ArrayList少,因为ArrayList需要预分配好空间大小,容易浪费
LinkedList中的节点不止存放数据,也需要其他空间用于存放指针域,所以具体的存储空间大小不一定!
LinkedList的遍历速度快于ArrayList
这也是错误的,链表访问下一个元素需要通过next指针引用,相比于ArrayList的i++操作要多一次访存操作,而i++通常会优化到寄存器
LinkedList的中间节点插入的时间复杂度是O(1)
正确答案应该是O(N),这是Java的接口设计失误导致的!事实上C++通过迭代器的方式可以实现O(1)时间复杂度,但是Java的插入就是通过遍历找节点的方式
2.2 B+树
数据库的索引使用了B+树这样的数据结构,可以说B+树像是专门为数据库这样的场景量身定制的数据结构了,要想理解B+树,我们需要先了解它的前身——B树(也被写做B-树)
2.2.1 B-树
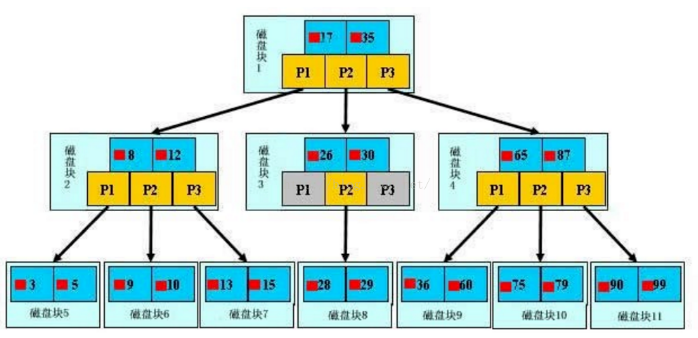
B-树:是一颗N叉搜索树(有序),是对于二叉搜索树的扩展,一个节点可以包含N个key值,这N个值又划分出了N+1个区间,如下图所示:
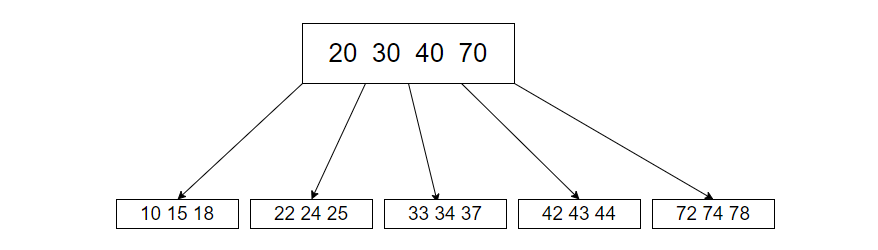
因此相较于二叉搜索树来说,相同高度的B树可以表示的数据个数更多了,使用B树来查询的时候,如果单论比较次数确定比二叉搜索树多很多,但是关键在于同一个节点的多个key值可以通过一次硬盘IO读取,即使总的比较次数增加了,但是硬盘IO次数少了,显著提高了效率!
2.2.2 B+树
B+树:B+树就是在B-树的基础上又做出了改进,同样也是N叉搜索树,每个节点可以包含多个key值,N个key可以划分出N个区间,B+树如图所示:
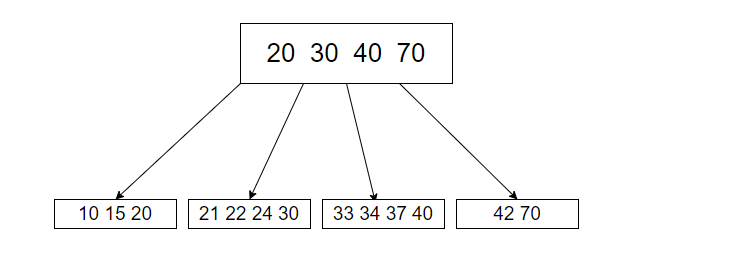
B+树的特点:
- N叉搜索树,一个节点包含N个key值,N个key值划分出N个区间
- 每个节点的N个key中,设定一个最大值(或最小值)
- 每个节点的N个key值都会在子树中重复出现
- 把叶子节点通过 链式结构 相连
B+树的好处:
- 针对范围查询比较有利,例如查询
21 <= age <= 37的所有人群,只需要在B+树中找到叶子节点中的21然后沿着链表往后一直遍历到37即可,得益于该链式结构,就省去了对树进行回溯查找的麻烦了 - 查询时间以及IO次数更加稳定,查询所有元素都需要经过根节点直到叶子节点的过程,所以途经的硬盘IO次数是固定的,更加稳定可预测!
- 由于叶子节点是数据的全集,因此非叶子节点为了节省内存空间可以只存储对应的key值缓存而不存储具体元素内容,大幅度减少了硬盘IO的次数